This is the multi-page printable view of this section. Click here to print.
Security with eBPF
- 1: Seccomp
- 2: Linux Security Module (LSM)
- 3: Landlock
- 4: bpf_send_signal
- 5: Tetragon
- 6: Bpfilter
1 - Seccomp
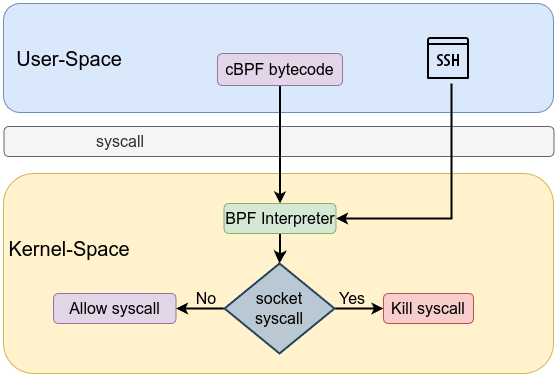
Seccomp, short for Secure Computing Mode, is a powerful kernel feature that limits the system calls a process can make, thereby reducing the exposed kernel surface and mitigating potential attacks. Seccomp is a security facility in the Linux kernel designed to be a tool for sandboxing processes by restricting the set of system calls they can use. to minimizes the kernel’s exposed interface, allowing developers to reduce the risk of kernel-level exploits. The filtering mechanism is implemented using Berkeley Packet Filter (cBPF) programs which inspect system call numbers and arguments before the system call is executed.
User-space security agents are vulnerable to TOCTOU attacks, tampering, and resource exhaustion because they depend on kernel communication to make security decisions. Seccomp addresses these issues by moving filtering into the kernel. Using a cBPF program, seccomp evaluates system call metadata atomically, eliminating the window for TOCTOU exploits and preventing tampering—since filters, once installed, become immutable and are inherited by child processes. This kernel-level enforcement ensures robust protection even if the user-space agent is compromised. Seccomp filtering is implemented as follows:
- The filter is defined as a cBPF program that evaluates each system call based on its number and its arguments. Since cBPF programs cannot dereference pointers, they operate only on the provided system call metadata, preventing time-of-check-time-of-use (TOCTOU) vulnerabilities.
- Once a process installs a seccomp filter using either the prctl() or seccomp() system call, every system call is intercepted and evaluated by the BPF program within the kernel. This means that even if the application logic is compromised, the kernel remains protected by the filter rules.
Note
cBPF’s limitations ensure that the filter logic only works with the system call metadata, making it less susceptible to common attacks that exploit pointer dereferencing.The prctl system call is used to control specific characteristics of the calling process and will be explained shortly. Using Seccomp in an application, developers typically follow these steps:
- The filter is defined using the
struct seccomp_datawhich is defined in the kernel source codeinclude/uapi/linux/seccomp.hwhich provides the metadata needed to evaluate each system call. This structure is defined as follows:
/**
* struct seccomp_data - the format the BPF program executes over.
* @nr: the system call number
* @arch: indicates system call convention as an AUDIT_ARCH_* value
* as defined in <linux/audit.h>.
* @instruction_pointer: at the time of the system call.
* @args: up to 6 system call arguments always stored as 64-bit values
* regardless of the architecture.
*/
struct seccomp_data {
int nr;
__u32 arch;
__u64 instruction_pointer;
__u64 args[6];
};
- Ensure that the process or its children cannot gain elevated privileges after the filter is installed using the following:
prctl(PR_SET_NO_NEW_PRIVS, 1);
- Use the
prctlwithPR_SET_SECCOMPto Install or activate seccomp filtering with a BPF program:
prctl(PR_SET_SECCOMP, SECCOMP_MODE_FILTER, &prog);
Here, prog is a pointer to a struct sock_fprog (defined in include/uapi/linux/filter.h) containing the BPF filter.
Seccomp Return Values
When a system call is intercepted, the BPF program returns one of several possible values. Each return value directs the kernel on how to handle the intercepted call. The actions are prioritized, meaning that if multiple filters are in place, the one with the highest precedence takes effect. The primary return values are:
SECCOMP_RET_KILL_PROCESS: Immediately terminates the entire process. The exit status indicates a SIGSYS signal.SECCOMP_RET_KILL_THREAD: Terminates only the current thread, again with a SIGSYS signal.SECCOMP_RET_TRAP: Sends a SIGSYS signal to the process, allowing the kernel to pass metadata about the blocked call (like the system call number and address) to a signal handler.SECCOMP_RET_ERRNO: Prevents execution of the system call and returns a predefined errno to the calling process.SECCOMP_RET_USER_NOTIF: Routes the system call to a user space notification handler, allowing external processes (like container managers) to decide how to handle the call.SECCOMP_RET_TRACE: If a tracer is attached (viaptrace), the tracer is notified, giving it an opportunity to modify or skip the system call.SECCOMP_RET_LOG: Logs the system call, then allows its execution. This is useful for development and debugging.SECCOMP_RET_ALLOW: Simply allows the system call to execute.
Seccomp return values are defined in include/linux/seccomp.h Kernel source code as the following:
#define SECCOMP_RET_KILL_PROCESS 0x80000000U /* kill the process */
#define SECCOMP_RET_KILL_THREAD 0x00000000U /* kill the thread */
#define SECCOMP_RET_KILL SECCOMP_RET_KILL_THREAD
#define SECCOMP_RET_TRAP 0x00030000U /* disallow and force a SIGSYS */
#define SECCOMP_RET_ERRNO 0x00050000U /* returns an errno */
#define SECCOMP_RET_USER_NOTIF 0x7fc00000U /* notifies userspace */
#define SECCOMP_RET_TRACE 0x7ff00000U /* pass to a tracer or disallow */
#define SECCOMP_RET_LOG 0x7ffc0000U /* allow after logging */
#define SECCOMP_RET_ALLOW 0x7fff0000U /* allow */
BPF Macros
Seccomp filters consist of a set of BPF macros. We will explain the most used ones:
BPF_STMT(code, k): A macro used to define a basic cBPF instruction that does not involve conditional branching. Thecodeparameter specifies the operation, andkis an immediate constant value used by the instruction.BPF_JUMP(code, k, jt, jf): A macro to define a conditional jump instruction.
code: Specifies the jump operation along with condition flags.
k: The constant value to compare against.
jt (jump true): The number of instructions to skip if the condition is met.
jf (jump false): The number of instructions to skip if the condition is not met.BPF_LD: This flag indicates a load instruction, which reads data into the accumulator.BPF_W: Specifies that the data to load is a word (typically 32 bits).BPF_ABS: Instructs the load operation to use absolute addressing—that is, load data from a fixed offset within the data structure (in this case, theseccomp_datastructure).BPF_K: Denotes that the operand (k) is an immediate constant.BPF_JMP: Indicates that the instruction is a jump (conditional or unconditional) type.BPF_JEQ: A condition flag used with jump instructions that causes a jump if the accumulator equals the constantk.
Let’s explore a simplified C code example demonstrating how to set up a seccomp filter to block socket syscall to prevent a process from initiating new network connections.
Code Example
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <stddef.h>
#include <sys/prctl.h>
#include <linux/seccomp.h>
#include <linux/filter.h>
#include <errno.h>
#define SYSCALL_SOCKET 41 // syscall number for socket
struct sock_filter filter[] = {
BPF_STMT(BPF_LD | BPF_W | BPF_ABS, offsetof(struct seccomp_data, nr)),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYSCALL_SOCKET, 0, 1),
BPF_STMT(BPF_RET | BPF_K, SECCOMP_RET_ERRNO | (EPERM & SECCOMP_RET_DATA)),
BPF_STMT(BPF_RET | BPF_K, SECCOMP_RET_ALLOW),
};
struct sock_fprog prog = {
.len = (unsigned short)(sizeof(filter) / sizeof(filter[0])),
.filter = filter,
};
int main(int argc, char *argv[]) {
if (argc < 2) {
fprintf(stderr, "Usage: %s <binary> [args...]\n", argv[0]);
exit(EXIT_FAILURE);
}
if (prctl(PR_SET_NO_NEW_PRIVS, 1, 0, 0, 0)) {
perror("prctl(PR_SET_NO_NEW_PRIVS) failed");
exit(EXIT_FAILURE);
}
if (prctl(PR_SET_SECCOMP, SECCOMP_MODE_FILTER, &prog)) {
perror("prctl(PR_SET_SECCOMP) failed");
exit(EXIT_FAILURE);
}
printf("Seccomp filter installed. Attempting socket on %s...\n", argv[1]);
execve(argv[1], &argv[1], NULL);
perror("socket");
return EXIT_FAILURE;
}
Seccomp filter is written using cBPF macros and defines a simple seccomp policy to block the socket system call. First, loads the system call number (from the nr field of the seccomp_data structure) into the accumulator
BPF_STMT(BPF_LD | BPF_W | BPF_ABS, offsetof(struct seccomp_data, nr)),
BPF_LD: Instructs the program to load data.BPF_W: Specifies that a 32-bit word should be loaded.BPF_ABS: Indicates that the data is located at an absolute offset from the beginning of theseccomp_datastructure.offsetof(struct seccomp_data, nr): Computes the offset of thenrfield (which holds the system call number) within theseccomp_datastructure.
Second, compare the syscall Number with socket. If the syscall is socket, the next instruction (which blocks the syscall) is executed. Otherwise, the filter skips over the block action and moves on.
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYSCALL_SOCKET, 0, 1),
BPF_JMP: Specifies that this is a jump instruction.BPF_JEQ: Adds the condition “jump if equal” to the operation.BPF_K: Indicates that the comparison value is an immediate constant.SYSCALL_SOCKET: The constant to compare against (i.e., the syscall number forsocket).0: If the condition is true (the syscall number equalsSYSCALL_SOCKET), do not skip any instructions (i.e., continue with the next instruction).1: If the condition is false (the syscall number does not equalSYSCALL_SOCKET), skip one instruction.
Third, Block the socket() syscall and return error code (e.g., EPERM).
BPF_STMT(BPF_RET | BPF_K, SECCOMP_RET_ERRNO | (EPERM & SECCOMP_RET_DATA)),
BPF_RET: Instructs the program to return a value immediately, effectively terminating the BPF program’s evaluation for this syscall.BPF_K: Indicates that the return value is given as an immediate constant.Return Value:SECCOMP_RET_ERRNO | (EPERM & SECCOMP_RET_DATA)
This tells the kernel to block the syscall by returning an error. Specifically, it sets the syscall’s return value to an error code (EPERM), meaning “Operation not permitted.”
Fourth, If the syscall was not socket, this instruction permits it.
BPF_STMT(BPF_RET | BPF_K, SECCOMP_RET_ALLOW),
BPF_RET | BPF_K: Again, a return instruction with a constant.Return Value:SECCOMP_RET_ALLOW. This instructs the kernel to allow the syscall to proceed.
Then, ensure that the process or its children cannot gain elevated privileges after the filter is installed
prctl(PR_SET_NO_NEW_PRIVS, 1, 0, 0, 0)
PR_SET_NO_NEW_PRIVS:This option tells the kernel to set a flag that prevents the process or its children from gaining new privileges. Finally, installing the seccomp filter.
prctl(PR_SET_SECCOMP, SECCOMP_MODE_FILTER, &prog)
Compile the code using clang -g -O2 seccomp_socket.c -o seccomp_socket, then chmod +x seccomp_socket. Next, run the code against ssh similar to the following: ./seccomp_socket /usr/bin/ssh [email protected]
Seccomp filter installed. Attempting socket on /usr/bin/ssh...
socket: Operation not permitted
ssh: connect to host 192.168.1.3 port 22: failure
We can see what is happening under the hood using strace ./seccomp_socket /usr/bin/ssh [email protected]
[...]
newfstatat(AT_FDCWD, "/etc/nsswitch.conf", {st_mode=S_IFREG|0644, st_size=569, ...}, 0) = 0
openat(AT_FDCWD, "/etc/passwd", O_RDONLY|O_CLOEXEC) = 3
fstat(3, {st_mode=S_IFREG|0644, st_size=2232, ...}) = 0
lseek(3, 0, SEEK_SET) = 0
read(3, "root:x:0:0:root:/root:/bin/bash\n"..., 4096) = 2232
close(3) = 0
socket(AF_INET, SOCK_STREAM, IPPROTO_TCP) = -1 EPERM (Operation not permitted)
getpid() = 2169
write(2, "socket: Operation not permitted\r"..., 33socket: Operation not permitted
) = 33
getpid() = 2169
write(2, "ssh: connect to host 192.168.1.3"..., 51ssh: connect to host 192.168.1.3 port 22: failure
[...]
Executing socket syscall is being blocked and a return value is showing -1 EPERM (Operation not permitted), which confirms that the filter is working as intended.
Note
The header file/include/linux/syscalls.h in the Linux kernel source code contains the prototypes for all system calls, providing the necessary declarations for the syscall interfaces. Additionally, for the x86_64 architecture, the file arch/x86/entry/syscalls/syscall_64.tbl lists all the system calls along with their corresponding syscall IDs, which are used to generate the syscall dispatch table during the kernel build process.
In the previous example we took blacklist approach by denying socket syscall for example. If we want to take the whitelist approach for a specific binary all we have to do is to record all its syscalls using something like strace. Let’s explore the whitelist approach, the following code has a menu with list of options such as running command ls which uses execve syscall , or opening /etc/passwd which uses open syscall and write syscall.
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/syscall.h>
#include <fcntl.h>
#include <string.h>
#include <errno.h>
int main(void) {
int choice;
while (1) {
printf("\nSyscall Menu:\n");
printf("1. Execve /usr/bin/ls\n");
printf("2. Open /etc/passwd\n");
printf("3. Write a message to stdout\n");
printf("4. Exit\n");
printf("Enter your choice: ");
if (scanf("%d", &choice) != 1) {
fprintf(stderr, "Invalid input.\n");
int c;
while ((c = getchar()) != '\n' && c != EOF);
continue;
}
getchar();
switch (choice) {
case 1: {
char *argv[] = { "ls", NULL };
char *envp[] = { NULL };
printf("Executing /usr/bin/ls via execve syscall...\n");
if (syscall(SYS_execve, "/usr/bin/ls", argv, envp) == -1) {
perror("execve syscall failed");
}
break;
}
case 2: {
printf("Opening /etc/passwd via open syscall...\n");
int fd = syscall(SYS_open, "/etc/passwd", O_RDONLY);
if (fd == -1) {
perror("open syscall failed");
} else {
printf("File /etc/passwd opened successfully (fd = %d).\n", fd);
if (syscall(SYS_close, fd) == -1) {
perror("close syscall failed");
}
}
exit(0);
}
case 3: {
const char *msg = "Hello from syscall write!\n";
printf("Writing message to stdout via write syscall...\n");
if (syscall(SYS_write, STDOUT_FILENO, msg, strlen(msg)) == -1) {
perror("write syscall failed");
}
exit(0);
}
case 4: {
printf("Exiting via exit_group syscall...\n");
syscall(SYS_exit_group, 0);
exit(0);
}
default:
printf("Invalid choice. Please select a number between 1 and 5.\n");
}
}
return 0;
}
Let’s compile it using gcc -O2 -Wall syscalls.c -o syscalls. Recording syscall can be done using strace. For example, we want to record write option in our code.
strace -c -f ./syscalls , then choose option 3:
Syscall Menu:
1. Execve /usr/bin/ls
2. Open /etc/passwd
3. Write a message to stdout
4. Exit
Enter your choice: 3
Writing message to stdout via write syscall...
Hello from syscall write!
The strace would look like this:
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
0.00 0.000000 0 2 read
0.00 0.000000 0 9 write
0.00 0.000000 0 2 close
0.00 0.000000 0 4 fstat
0.00 0.000000 0 8 mmap
0.00 0.000000 0 3 mprotect
0.00 0.000000 0 1 munmap
0.00 0.000000 0 3 brk
0.00 0.000000 0 2 pread64
0.00 0.000000 0 1 1 access
0.00 0.000000 0 1 execve
0.00 0.000000 0 1 arch_prctl
0.00 0.000000 0 1 set_tid_address
0.00 0.000000 0 2 openat
0.00 0.000000 0 1 set_robust_list
0.00 0.000000 0 1 prlimit64
0.00 0.000000 0 1 getrandom
0.00 0.000000 0 1 rseq
------ ----------- ----------- --------- --------- ----------------
100.00 0.000000 0 44 1 total
These are all of used syscalls to run the binary to this option:
case 3: {
const char *msg = "Hello from syscall write!\n";
printf("Writing message to stdout via write syscall...\n");
if (syscall(SYS_write, STDOUT_FILENO, msg, strlen(msg)) == -1) {
perror("write syscall failed");
}
Let’s build seccomp program to allow only these syscalls
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <stddef.h>
#include <sys/prctl.h>
#include <linux/seccomp.h>
#include <linux/filter.h>
#include <errno.h>
#include <sys/syscall.h>
#define SYS_READ 0
#define SYS_WRITE 1
#define SYS_CLOSE 3
#define SYS_FSTAT 5
#define SYS_MMAP 9
#define SYS_MPROTECT 10
#define SYS_MUNMAP 11
#define SYS_BRK 12
#define SYS_PREAD64 17
#define SYS_ACCESS 21
#define SYS_EXECVE 59
#define SYS_ARCH_PRCTL 158
#define SYS_SET_TID_ADDRESS 218
#define SYS_OPENAT 257
#define SYS_SET_ROBUST_LIST 273
#define SYS_PRLIMIT64 302
#define SYS_GETRANDOM 318
#define SYS_RSEQ 334
struct sock_filter filter[] = {
BPF_STMT(BPF_LD | BPF_W | BPF_ABS, offsetof(struct seccomp_data, nr)),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_READ, 18, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_WRITE, 17, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_CLOSE, 16, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_FSTAT, 15, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_MMAP, 14, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_MPROTECT, 13, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_MUNMAP, 12, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_BRK, 11, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_PREAD64, 10, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_ACCESS, 9, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_EXECVE, 8, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_ARCH_PRCTL, 7, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_SET_TID_ADDRESS, 6, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_OPENAT, 5, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_SET_ROBUST_LIST, 4, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_PRLIMIT64, 3, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_GETRANDOM, 2, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_RSEQ, 1, 0),
BPF_STMT(BPF_RET | BPF_K, SECCOMP_RET_ERRNO | (EPERM & SECCOMP_RET_DATA)),
BPF_STMT(BPF_RET | BPF_K, SECCOMP_RET_ALLOW),
};
struct sock_fprog prog = {
.len = (unsigned short)(sizeof(filter) / sizeof(filter[0])),
.filter = filter,
};
int main(int argc, char *argv[]) {
if (argc < 2) {
fprintf(stderr, "Usage: %s <binary> [args...]\n", argv[0]);
exit(EXIT_FAILURE);
}
if (prctl(PR_SET_NO_NEW_PRIVS, 1, 0, 0, 0)) {
perror("prctl(PR_SET_NO_NEW_PRIVS) failed");
exit(EXIT_FAILURE);
}
if (prctl(PR_SET_SECCOMP, SECCOMP_MODE_FILTER, &prog)) {
perror("prctl(PR_SET_SECCOMP) failed");
exit(EXIT_FAILURE);
}
printf("Seccomp whitelist filter installed. Executing %s...\n", argv[1]);
execve(argv[1], &argv[1], NULL);
perror("execve failed");
return EXIT_FAILURE;
}
Compile it gcc -O2 -Wall seccomp.c -o seccomp, then chmod +x seccomp and finally ./seccomp ./syscalls and choose 3
Syscall Menu:
1. Execve /usr/bin/ls
2. Open /etc/passwd
3. Write a message to stdout
4. Exit
Enter your choice: 3
Writing message to stdout via write syscall...
Hello from syscall write!
Segmentation fault (core dumped)
If you choose something else like 2
Syscall Menu:
1. Execve /usr/bin/ls
2. Open /etc/passwd
3. Write a message to stdout
4. Exit
Enter your choice: 2
Opening /etc/passwd via open syscall...
open syscall failed: Operation not permitted
Segmentation fault (core dumped)
Notice that we have Segmentation fault (core dumped) . Simply because we have a blocked a syscall exit_group , run strace ./seccomp ./syscalls then choose 3:
[...]
fstat(0, {st_mode=S_IFCHR|0620, st_rdev=makedev(0x88, 0x2), ...}) = 0
write(1, "Enter your choice: ", 19Enter your choice: ) = 19
read(0, 3
"3\n", 1024) = 2
write(1, "Writing message to stdout via wr"..., 47Writing message to stdout via write syscall...
) = 47
write(1, "Hello from syscall write!\n", 26Hello from syscall write!
) = 26
exit_group(0) = -1 EPERM (Operation not permitted)
--- SIGSEGV {si_signo=SIGSEGV, si_code=SI_KERNEL, si_addr=NULL} ---
+++ killed by SIGSEGV (core dumped) +++
Segmentation fault (core dumped)
We need to whitelist exit_group too in our code. Strace couldn’t record exit_group syscall first because syscall such as exit_group syscall terminates the process immediately, so there’s no return value for strace to capture. Fixing our code is just by adding exit_group to the whitelist:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <stddef.h>
#include <sys/prctl.h>
#include <linux/seccomp.h>
#include <linux/filter.h>
#include <errno.h>
#include <sys/syscall.h>
#define SYS_READ 0
#define SYS_WRITE 1
#define SYS_CLOSE 3
#define SYS_FSTAT 5
#define SYS_MMAP 9
#define SYS_MPROTECT 10
#define SYS_MUNMAP 11
#define SYS_BRK 12
#define SYS_PREAD64 17
#define SYS_ACCESS 21
#define SYS_EXECVE 59
#define SYS_ARCH_PRCTL 158
#define SYS_SET_TID_ADDRESS 218
#define SYS_OPENAT 257
#define SYS_SET_ROBUST_LIST 273
#define SYS_PRLIMIT64 302
#define SYS_GETRANDOM 318
#define SYS_RSEQ 334
#define SYS_EXIT_GROUP 231
struct sock_filter filter[] = {
BPF_STMT(BPF_LD | BPF_W | BPF_ABS, offsetof(struct seccomp_data, nr)),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_EXIT_GROUP, 19, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_READ, 18, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_WRITE, 17, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_CLOSE, 16, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_FSTAT, 15, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_MMAP, 14, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_MPROTECT, 13, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_MUNMAP, 12, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_BRK, 11, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_PREAD64, 10, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_ACCESS, 9, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_EXECVE, 8, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_ARCH_PRCTL, 7, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_SET_TID_ADDRESS, 6, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_OPENAT, 5, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_SET_ROBUST_LIST, 4, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_PRLIMIT64, 3, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_GETRANDOM, 2, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_RSEQ, 1, 0),
BPF_STMT(BPF_RET | BPF_K, SECCOMP_RET_ERRNO | (EPERM & SECCOMP_RET_DATA)),
BPF_STMT(BPF_RET | BPF_K, SECCOMP_RET_ALLOW),
};
struct sock_fprog prog = {
.len = (unsigned short)(sizeof(filter) / sizeof(filter[0])),
.filter = filter,
};
int main(int argc, char *argv[]) {
if (argc < 2) {
fprintf(stderr, "Usage: %s <binary> [args...]\n", argv[0]);
exit(EXIT_FAILURE);
}
if (prctl(PR_SET_NO_NEW_PRIVS, 1, 0, 0, 0)) {
perror("prctl(PR_SET_NO_NEW_PRIVS) failed");
exit(EXIT_FAILURE);
}
if (prctl(PR_SET_SECCOMP, SECCOMP_MODE_FILTER, &prog)) {
perror("prctl(PR_SET_SECCOMP) failed");
exit(EXIT_FAILURE);
}
printf("Seccomp whitelist filter installed. Executing %s...\n", argv[1]);
execve(argv[1], &argv[1], NULL);
perror("execve failed");
return EXIT_FAILURE;
}
In the following part, we will explain the LSM kernel framework, a well-defined interface to enforce Mandatory Access Control (MAC) policies in a modular way.
2 - Linux Security Module (LSM)
LSM is a framework built into the Linux kernel that provides a set of hooks—well-defined points in the kernel code—where security modules can enforce access control and other security policies. These hooks are statically integrated into the kernel, meaning that a given security module (such as SELinux, AppArmor, or Smack) is selected at build or boot time via configuration options. Once active, the LSM framework directs security-relevant decisions (like permission checks, file access, or process operations) through these hooks so that the chosen security policy is applied consistently throughout the system.
LSM with eBPF Hooks
Traditionally, LSM hooks require the security policy to be built into the kernel, and modifying policies often involves a kernel rebuild or reboot. With the rise of eBPF, it is now possible to attach eBPF programs to certain LSM hooks dynamically starting from kernel version 5.7. This modern approach allows for:
- Dynamic Policy Updates: eBPF programs can be loaded, updated, or removed at runtime without rebooting the system.
- Fine-Grained Control: LSM with eBPF can potentially provide more granular visibility and control over kernel behavior. It can monitor system calls, intercept kernel functions, and enforce policies with a level of detail that is hard to achieve with static hooks alone.
- Flexibility and Experimentation: Administrators and security professionals can quickly test and deploy new security policies, fine-tune behavior, or respond to emerging threats without lengthy kernel recompilations.
- Runtime Enforcement: eBPF programs attached to LSM hooks (using the BPF_PROG_TYPE_LSM) can inspect the kernel context and actively enforce security decisions (such as logging events or rejecting operations).
In short, while traditional LSM modules (such as SELinux) enforce security policies statically at build time, LSM with eBPF hooks introduces dynamic, runtime adaptability to kernel security. This hybrid approach leverages the robustness of the LSM framework and the operational agility of eBPF. The LSM interface triggers immediately before the kernel acts on a data structure, and at each hook point, a callback function determines whether to permit the action.
Let’s explore together LSM with eBPF. First, we need to check if BPF LSM is supported by the kernel:
cat /boot/config-$(uname -r) | grep BPF_LSM
If the output is CONFIG_BPF_LSM=y then the BPF LSM is supported. Then we check if BPF LSM is enabled:
cat /sys/kernel/security/lsm
if the output contains bpf then the module is enabled like the following:
lockdown,capability,landlock,yama,apparmor,tomoyo,bpf,ipe,ima,evm
If the output includes ndlock, lockdown, yama, integrity, and apparmor along with bpf, add GRUB_CMDLINE_LINUX="lsm=ndlock,lockdown,yama,integrity,apparmor,bpf" to the /etc/default/grub file, update GRUB using sudo update-grub2, and reboot.
The list of all LSM hooks are defined in include/linux/lsm_hook_defs.h, the following is just an example of it:
LSM_HOOK(int, 0, path_chmod, const struct path *path, umode_t mode)
LSM_HOOK(int, 0, path_chown, const struct path *path, kuid_t uid, kgid_t gid)
LSM_HOOK(int, 0, path_chroot, const struct path *path)
LSM hooks documentation which has descriptive documentation for most of LSM hooks such as:
* @path_chmod:
* Check for permission to change a mode of the file @path. The new
* mode is specified in @mode.
* @path contains the path structure of the file to change the mode.
* @mode contains the new DAC's permission, which is a bitmask of
* constants from <include/uapi/linux/stat.h>.
* Return 0 if permission is granted.
* @path_chown:
* Check for permission to change owner/group of a file or directory.
* @path contains the path structure.
* @uid contains new owner's ID.
* @gid contains new group's ID.
* Return 0 if permission is granted.
* @path_chroot:
* Check for permission to change root directory.
* @path contains the path structure.
* Return 0 if permission is granted.
Let’s explore LSM with path_mkdir LSM hook which described as the following:
* @path_mkdir:
* Check permissions to create a new directory in the existing directory
* associated with path structure @path.
* @dir contains the path structure of parent of the directory
* to be created.
* @dentry contains the dentry structure of new directory.
* @mode contains the mode of new directory.
* Return 0 if permission is granted.
path_mkdir is defined in LSM as the following:
LSM_HOOK(int, 0, path_mkdir, const struct path *dir, struct dentry *dentry, umode_t mode)
#include "vmlinux.h"
#include <bpf/bpf_core_read.h>
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
#define FULL_PATH_LEN 256
char _license[] SEC("license") = "GPL";
SEC("lsm/path_mkdir")
int BPF_PROG(path_mkdir, const struct path *dir, struct dentry *dentry, umode_t mode, int ret)
{
char full_path[FULL_PATH_LEN] = {};
u64 uid_gid = bpf_get_current_uid_gid();
u32 uid = (u32) uid_gid;
const char *dname = (const char *)BPF_CORE_READ(dentry, d_name.name);
bpf_path_d_path((struct path *)dir, full_path, sizeof(full_path));
bpf_printk("LSM: mkdir '%s' in directory '%s' with mode %d, UID %d\n", dname, full_path, mode, uid);
return 0;
}
struct path is data structure used by the VFS (Virtual Filesystem) layer to represent a location in the filesystem. struct path is defined in include/linux/path.h as the following
struct path {
struct vfsmount *mnt;
struct dentry *dentry;
}
struct dentry directory entry data structure which is responsible for making links between inodes and filename. struct dentry is defined in include/linux/dcache.h as the following:
struct dentry {
unsigned int d_flags;
seqcount_spinlock_t d_seq;
struct hlist_bl_node d_hash;
struct dentry *d_parent;
struct qstr d_name;
struct inode *d_inode;
unsigned char d_iname[DNAME_INLINE_LEN];
const struct dentry_operations *d_op;
struct super_block *d_sb;
unsigned long d_time;
void *d_fsdata;
struct lockref d_lockref;
union {
struct list_head d_lru;
wait_queue_head_t *d_wait;
};
struct hlist_node d_sib;
struct hlist_head d_children;
union {
struct hlist_node d_alias;
struct hlist_bl_node d_in_lookup_hash;
struct rcu_head d_rcu;
} d_u;
};
struct dentry data structure has a member struct qstr data structure that contains information about the name (a pointer to the actual character array containing the name) defined in include/linux/dcache.h as the following:
struct qstr {
union {
struct {
HASH_LEN_DECLARE;
};
u64 hash_len;
};
const unsigned char *name;
};
That’s how you extract the filename: by reading the dentry data structure, then accessing its d_name member, and finally retrieving the name member using BPF_CORE_READ macro.
const char *dname = (const char *)BPF_CORE_READ(dentry, d_name.name);
bpf_path_d_path Kernel function i used to extract the path name for the supplied path data structure defined in fs/bpf_fs_kfuncs.c in the kernel source code as the following:
__bpf_kfunc int bpf_path_d_path(struct path *path, char *buf, size_t buf__sz)
{
int len;
char *ret;
if (!buf__sz)
return -EINVAL;
ret = d_path(path, buf, buf__sz);
if (IS_ERR(ret))
return PTR_ERR(ret);
len = buf + buf__sz - ret;
memmove(buf, ret, len);
return len;
}
There is a comment in the source code very descriptive about this kernel function which says:
* bpf_path_d_path - resolve the pathname for the supplied path
* @path: path to resolve the pathname for
* @buf: buffer to return the resolved pathname in
* @buf__sz: length of the supplied buffer
*
* Resolve the pathname for the supplied *path* and store it in *buf*. This BPF
* kfunc is the safer variant of the legacy bpf_d_path() helper and should be
* used in place of bpf_d_path() whenever possible. It enforces KF_TRUSTED_ARGS
* semantics, meaning that the supplied *path* must itself hold a valid
* reference, or else the BPF program will be outright rejected by the BPF
* verifier.
*
* This BPF kfunc may only be called from BPF LSM programs.
*
* Return: A positive integer corresponding to the length of the resolved
* pathname in *buf*, including the NUL termination character. On error, a
* negative integer is returned.
bpf_get_current_uid_gid helper function to get the current UID and GID.
u64 uid_gid = bpf_get_current_uid_gid();
u32 uid = (u32) uid_gid; // the lower 32 bits are the UID
The user-space code is like the following:
#include <stdio.h>
#include <unistd.h>
#include <sys/resource.h>
#include <bpf/libbpf.h>
#include "lsm_mkdir.skel.h"
static int libbpf_print_fn(enum libbpf_print_level level, const char *format, va_list args)
{
return vfprintf(stderr, format, args);
}
int main(int argc, char **argv)
{
struct lsm_mkdir *skel;
int err;
libbpf_set_print(libbpf_print_fn);
skel = lsm_mkdir__open();
if (!skel) {
fprintf(stderr, "Failed to open BPF skeleton\n");
return 1;
}
err = lsm_mkdir__load(skel);
if (err) {
fprintf(stderr, "Failed to load and verify BPF skeleton\n");
goto cleanup;
}
err = lsm_mkdir__attach(skel);
if (err) {
fprintf(stderr, "Failed to attach BPF skeleton\n");
goto cleanup;
}
printf("Successfully started! Please run `sudo cat /sys/kernel/debug/tracing/trace_pipe` "
"to see output of the BPF programs.\n");
for (;;) {
fprintf(stderr, ".");
sleep(1);
}
cleanup:
lsm_mkdir__destroy(skel);
return -err;
}
Output:
[...] LSM: mkdir 'test1' in directory '/tmp' with mode 511, UID 1000
[...] LSM: mkdir 'test2' in directory '/tmp' with mode 511, UID 1000
eBPF LSM are classified as BPF_PROG_TYPE_LSM, sudo strace -ebpf ./loader will show similar output:
[...]
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_LSM, insn_cnt=68, insns=0x560837bfc0e0, license="GPL", log_level=0, log_size=0, log_buf=NULL, kern_version=KERNEL_VERSION(6, 12, 12), prog_flags=0, prog_name="path_mkdir", prog_ifindex=0, expected_attach_type=BPF_LSM_MAC, prog_btf_fd=4, func_info_rec_size=8, func_info=0x560837bfa650, func_info_cnt=1, line_info_rec_size=16, line_info=0x560837bfcfb0, line_info_cnt=11, attach_btf_id=58073, attach_prog_fd=0, fd_array=NULL}, 148) = 5
This is not all, LSM is not just about observability, LSM are made to take decisions, define controls and enforce them. Let’s explore another example which its main objective to block opining /etc/passwd file.
#include "vmlinux.h"
#include <errno.h>
#include <bpf/bpf_core_read.h>
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
#define FULL_PATH_LEN 256
char _license[] SEC("license") = "GPL";
SEC("lsm/file_open")
int BPF_PROG(file_open, struct file *file)
{
char full_path[FULL_PATH_LEN] = {};
int ret;
const char target[] = "/etc/passwd";
int i;
ret = bpf_path_d_path(&file->f_path, full_path, sizeof(full_path));
if (ret < 0)
return 0;
for (i = 0; i < sizeof(target) - 1; i++) {
if (full_path[i] != target[i])
break;
}
if (i == sizeof(target) - 1) {
bpf_printk("Blocking open of: %s\n", full_path);
return -EPERM;
}
return 0;
}
struct file data structure represents an instance of an open file or device within a process defined in include/linux/fs.h header file in the kernel source code as the following:
struct file {
atomic_long_t f_count;
spinlock_t f_lock;
fmode_t f_mode;
const struct file_operations *f_op;
struct address_space *f_mapping;
void *private_data;
struct inode *f_inode;
unsigned int f_flags;
unsigned int f_iocb_flags;
const struct cred *f_cred;
struct path f_path;
union {
struct mutex f_pos_lock;
u64 f_pipe;
};
loff_t f_pos;
#ifdef CONFIG_SECURITY
void *f_security;
#endif
struct fown_struct *f_owner;
errseq_t f_wb_err;
errseq_t f_sb_err;
#ifdef CONFIG_EPOLL
struct hlist_head *f_ep;
#endif
union {
struct callback_head f_task_work;
struct llist_node f_llist;
struct file_ra_state f_ra;
freeptr_t f_freeptr;
};
struct file members are described as the following:
* struct file - Represents a file
* @f_count: reference count
* @f_lock: Protects f_ep, f_flags. Must not be taken from IRQ context.
* @f_mode: FMODE_* flags often used in hotpaths
* @f_op: file operations
* @f_mapping: Contents of a cacheable, mappable object.
* @private_data: filesystem or driver specific data
* @f_inode: cached inode
* @f_flags: file flags
* @f_iocb_flags: iocb flags
* @f_cred: stashed credentials of creator/opener
* @f_path: path of the file
* @f_pos_lock: lock protecting file position
* @f_pipe: specific to pipes
* @f_pos: file position
* @f_security: LSM security context of this file
* @f_owner: file owner
* @f_wb_err: writeback error
* @f_sb_err: per sb writeback errors
* @f_ep: link of all epoll hooks for this file
* @f_task_work: task work entry point
* @f_llist: work queue entrypoint
* @f_ra: file's readahead state
* @f_freeptr: Pointer used by SLAB_TYPESAFE_BY_RCU file cache (don't touch.)
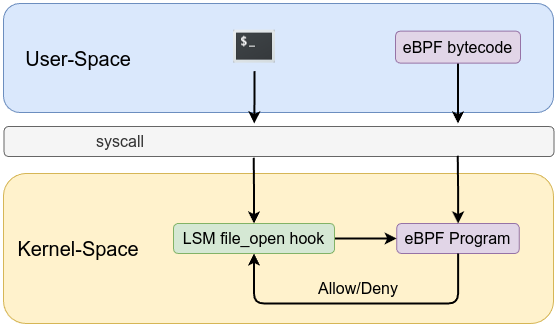
Output when opening /etc/passwd shows the following:
cat-1673 [003] ...11 262.949842: bpf_trace_printk: Blocking open of: /etc/passwd
The code can also work based on comparing the inode rather than the filename. The following example uses a hard-coded inode value for demonstration purposes only.
Note
An inode (short for “index node”) a unique inode number is assigned to Each file or directory in a filesystem. When a file is accessed, the system uses the inode to locate and retrieve its metadata and content. Inode does not store the file’s name.Note
Hard-coding an inode number in your code is not suitable for portability. Inode numbers are specific to a particular filesystem and can change across different systems. This means that relying on a fixed inode number may lead to unexpected behavior in different environments.#include "vmlinux.h"
#include <errno.h>
#include <bpf/bpf_core_read.h>
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
#define TARGET_INODE 788319
char _license[] SEC("license") = "GPL";
SEC("lsm/file_open")
int BPF_PROG(file_open, struct file *file)
{
u64 ino = BPF_CORE_READ(file, f_inode, i_ino);
if (ino == TARGET_INODE) {
bpf_printk("Blocking open: inode %llu matched TARGET_INO\n", ino);
return -EPERM;
}
return 0;
}
First we need to obtain /etc/passwd inode using ls-i /etc/passwd:
788319 /etc/passwd
Then you use that number in your code to check against the file’s inode. Let’s see another example for socket. socket_create described in the source code as the following:
* @socket_create:
* Check permissions prior to creating a new socket.
* @family contains the requested protocol family.
* @type contains the requested communications type.
* @protocol contains the requested protocol.
* @kern set to 1 if a kernel socket.
* Return 0 if permission is granted.
socket_create LSM hook look like this in the source code also:
LSM_HOOK(int, 0, socket_create, int family, int type, int protocol, int kern)
Let’s see how to prevent UID 1000 from creating a new socket:
#include "vmlinux.h"
#include <errno.h>
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
char _license[] SEC("license") = "GPL";
SEC("lsm/socket_create")
int BPF_PROG(socket_create, int family, int type, int protocol, int kern)
{
u64 uid_gid = bpf_get_current_uid_gid();
u32 uid = (u32) uid_gid;
if (uid == 1000) {
bpf_printk("Blocking socket_create for uid %d, family %d, type %d, protocol %d\n",
uid, family, type, protocol);
return -EPERM;
}
return 0;
}
When a process running as UID 1000 (for example, when a user attempts to run ping or ssh) tries to create a new socket, the LSM hook for socket creation is triggered. The eBPF program intercepts the system call and uses bpf_get_current_uid_gid() to obtain the current UID. If the UID is 1000, the program returns -EPERM (which means “Operation not permitted”). This return value causes the socket creation to fail.
ping-2197 [...] Blocking socket_create for uid 1000, family 2, type 2, protocol 1
ssh-2198 [...] Blocking socket_create for uid 1000, family 2, type 1, protocol 6
Of course—you can fine-tune your policy based on the arguments passed to the hook. For example, if you only want to block socket creation for TCP (protocol number 6), you can do something like this:
if (protocol == 6) {
return -EPERM;
}
This means that only when the protocol equals 6 (TCP) will the socket creation be blocked, while other protocols will be allowed. Socket family is defined in include/linux/socket.h, while socket type is defined in include/linux/net.h and socket protocol is defined in include/uapi/linux/in.h.
I strongly recommend exploring more LSM hooks on your own and consulting the documentation—you’ll quickly see that working with them is not hard at all. Next, we will see Landlock which allows a process to restrict its own privileges in unprivileged manner or process sandbox.
3 - Landlock
Landlock is a Linux Security Module (LSM) introduced in Linux kernel 5.13 based on eBPF that allows processes to restrict their own privileges in a fine-grained, stackable, and unprivileged manner. Unlike traditional Mandatory Access Control (MAC) systems such as SELinux and AppArmor, which require administrative setup, Landlock enables unprivileged processes to sandbox themselves. This makes it particularly useful for running potentially vulnerable applications while limiting their ability to perform unauthorized actions.
By defining specific access rules, processes can restrict themselves to only the necessary files and network operations, preventing unauthorized access or modification of sensitive data. This capability is particularly valuable in scenarios where applications handle untrusted input or where minimizing the impact of potential security breaches is critical.
A key advantage of Landlock is its layered security model. Rulesets in Landlock are stackable, meaning multiple rulesets can be enforced incrementally to tighten security restrictions over time. Once a Landlock ruleset is enforced, it cannot be relaxed or removed, ensuring that restrictions remain in place throughout the process’s lifetime. Additionally, Landlock operates at the kernel object (e.g., file, process, socket) level rather than filtering syscalls, providing minimal overhead, a stable interface for future developments and race condition free.
To check if Landlock is up and running is by executing sudo dmesg | grep landlock || journalctl -kb -g landlock
[ 0.043191] LSM: initializing lsm=lockdown,capability,landlock,yama,apparmor,tomoyo,bpf,ipe,ima,evm
[ 0.043191] landlock: Up and running.
How Landlock Works
- Ruleset Creation:
A Landlock ruleset defines what kinds of actions are handled (e.g., file read/write, TCP connect) and denies those actions by default unless they are explicitly allowed by the rules added to that ruleset. There are three types of rules in landlock defined ininclude/uapi/linux/landlock.hheader file :handled_access_fs,handled_access_netandscopedas defined in the following data structure:
struct landlock_ruleset_attr {
/**
* @handled_access_fs: Bitmask of handled filesystem actions
* (cf. `Filesystem flags`_).
*/
__u64 handled_access_fs;
/**
* @handled_access_net: Bitmask of handled network actions (cf. `Network
* flags`_).
*/
__u64 handled_access_net;
/**
* @scoped: Bitmask of scopes (cf. `Scope flags`_)
* restricting a Landlock domain from accessing outside
* resources (e.g. IPCs).
*/
__u64 scoped;
};
handled_access_fs rules to sandbox a process to a set of actions on files and directories and they are as the following:
#define LANDLOCK_ACCESS_FS_EXECUTE (1ULL << 0)
#define LANDLOCK_ACCESS_FS_WRITE_FILE (1ULL << 1)
#define LANDLOCK_ACCESS_FS_READ_FILE (1ULL << 2)
#define LANDLOCK_ACCESS_FS_READ_DIR (1ULL << 3)
#define LANDLOCK_ACCESS_FS_REMOVE_DIR (1ULL << 4)
#define LANDLOCK_ACCESS_FS_REMOVE_FILE (1ULL << 5)
#define LANDLOCK_ACCESS_FS_MAKE_CHAR (1ULL << 6)
#define LANDLOCK_ACCESS_FS_MAKE_DIR (1ULL << 7)
#define LANDLOCK_ACCESS_FS_MAKE_REG (1ULL << 8)
#define LANDLOCK_ACCESS_FS_MAKE_SOCK (1ULL << 9)
#define LANDLOCK_ACCESS_FS_MAKE_FIFO (1ULL << 10)
#define LANDLOCK_ACCESS_FS_MAKE_BLOCK (1ULL << 11)
#define LANDLOCK_ACCESS_FS_MAKE_SYM (1ULL << 12)
#define LANDLOCK_ACCESS_FS_REFER (1ULL << 13)
#define LANDLOCK_ACCESS_FS_TRUNCATE (1ULL << 14)
#define LANDLOCK_ACCESS_FS_IOCTL_DEV (1ULL << 15)
They are explained in include/uapi/linux/landlock.h as the following:
* - %LANDLOCK_ACCESS_FS_EXECUTE: Execute a file.
* - %LANDLOCK_ACCESS_FS_WRITE_FILE: Open a file with write access.
* - %LANDLOCK_ACCESS_FS_READ_FILE: Open a file with read access.
* - %LANDLOCK_ACCESS_FS_READ_DIR: Open a directory or list its content.
* - %LANDLOCK_ACCESS_FS_REMOVE_DIR: Remove an empty directory or rename one.
* - %LANDLOCK_ACCESS_FS_REMOVE_FILE: Unlink (or rename) a file.
* - %LANDLOCK_ACCESS_FS_MAKE_CHAR: Create (or rename or link) a character device.
* - %LANDLOCK_ACCESS_FS_MAKE_DIR: Create (or rename) a directory.
* - %LANDLOCK_ACCESS_FS_MAKE_REG: Create (or rename or link) a regular file.
* - %LANDLOCK_ACCESS_FS_MAKE_SOCK: Create (or rename or link) a UNIX domain socket.
* - %LANDLOCK_ACCESS_FS_MAKE_FIFO: Create (or rename or link) a named pipe.
* - %LANDLOCK_ACCESS_FS_MAKE_BLOCK: Create (or rename or link) a block device.
* - %LANDLOCK_ACCESS_FS_MAKE_SYM: Create (or rename or link) a symbolic link.
* - %LANDLOCK_ACCESS_FS_REFER: Link or rename a file from or to a different directory (i.e. reparent a file hierarchy).
* - %LANDLOCK_ACCESS_FS_TRUNCATE: Truncate a file with:truncate(2), ftruncate(2), creat(2), or open(2) with O_TRUNC.
* - %LANDLOCK_ACCESS_FS_IOCTL_DEV: Invoke :manpage:`ioctl(2)` commands on an opened character or block device.
handled_access_net rules to sandbox a process to a set of network actions and they are defined as the following:
#define LANDLOCK_ACCESS_NET_BIND_TCP (1ULL << 0)
#define LANDLOCK_ACCESS_NET_CONNECT_TCP (1ULL << 1)
handled_access_net rules are explained as the following:
* - %LANDLOCK_ACCESS_NET_BIND_TCP: Bind a TCP socket to a local port.
* - %LANDLOCK_ACCESS_NET_CONNECT_TCP: Connect an active TCP socket to
scoped rules to sandbox a process from a set of IPC (inter-process communication) actions or sending signals and they are defined as the following:
#define LANDLOCK_SCOPE_ABSTRACT_UNIX_SOCKET (1ULL << 0)
#define LANDLOCK_SCOPE_SIGNAL (1ULL << 1)
scoped rules are explained as the following:
* - %LANDLOCK_SCOPE_ABSTRACT_UNIX_SOCKET: Restrict a sandboxed process from connecting to an abstract UNIX socket created by a process outside the related Landlock domain (e.g. a parent domain or a non-sandboxed process).
* - %LANDLOCK_SCOPE_SIGNAL: Restrict a sandboxed process from sending a signal to another process outside the domain
Ruleset Creation is done using landlock_create_ruleset() syscall.
- Adding Rules:
Define access rights since the defaults actions is deny. Define access rights can be done using data structures which arelandlock_path_beneath_attrandlandlock_net_port_attr. For example, block access to entire file system except read files, read directories and execute on/usr/bin/.landlock_path_beneath_attrdata structure is defined ininclude/uapi/linux/landlock.hheader file as the following:
struct landlock_path_beneath_attr {
/**
* @allowed_access: Bitmask of allowed actions for this file hierarchy
* (cf. `Filesystem flags`_).
*/
__u64 allowed_access;
/**
* @parent_fd: File descriptor, preferably opened with ``O_PATH``,
* which identifies the parent directory of a file hierarchy, or just a
* file.
*/
__s32 parent_fd;
/*
* This struct is packed to avoid trailing reserved members.
* Cf. security/landlock/syscalls.c:build_check_abi()
*/
} __attribute__((packed));
landlock_net_port_attr data structure is defined in include/uapi/linux/landlock.h header file as the following:
struct landlock_net_port_attr {
/**
* @allowed_access: Bitmask of allowed network actions for a port
* (cf. `Network flags`_).
*/
__u64 allowed_access;
/**
* @port: Network port in host endianness.
*
* It should be noted that port 0 passed to :manpage:`bind(2)` will bind
* to an available port from the ephemeral port range. This can be
* configured with the ``/proc/sys/net/ipv4/ip_local_port_range`` sysctl
* (also used for IPv6).
*
* A Landlock rule with port 0 and the ``LANDLOCK_ACCESS_NET_BIND_TCP``
* right means that requesting to bind on port 0 is allowed and it will
* automatically translate to binding on the related port range.
*/
__u64 port;
};
Adding rules can be done using landlock_add_rule() syscall.
- Restricting Self:
Once a ruleset is created and populated, a thread (withno_new_privsset, or withCAP_SYS_ADMINin its namespace) can calllandlock_restrict_self()syscall to enforce it on itself and all child processes. After enforcement, the process can still add more restrictions later, but cannot remove existing ones.
Note
Each time you calllandlock_restrict_self() syscall will add a new layer, and you can stack up to 16 layers (rulesets). If layers exceed 16, it will return E2BIG (Argument list too long).
ABI Versions and Compatibility
When you call landlock_create_ruleset() with attr = NULL and size = 0, it returns the highest supported ABI. A recommended practice is to do a best-effort approach: detect the system’s ABI, then disable features that are not supported, so your program runs consistently on different kernels.
ABI < 2: Did not allow renaming/linking across directories.ABI < 3: File truncation could not be restricted.ABI < 4: No network restriction support.ABI < 5: Could not restrictioctl(2)on devices.ABI < 6: No scope restrictions for signals or abstract Unix sockets.
It’s recommended to detect Landlock ABI version to maintain compatibility across different kernel versions as stated in the kernel manual:
int abi;
abi = landlock_create_ruleset(NULL, 0, LANDLOCK_CREATE_RULESET_VERSION);
if (abi < 0) {
/* Degrades gracefully if Landlock is not handled. */
perror("The running kernel does not enable to use Landlock");
return 0;
}
switch (abi) {
case 1:
/* Removes LANDLOCK_ACCESS_FS_REFER for ABI < 2 */
ruleset_attr.handled_access_fs &= ~LANDLOCK_ACCESS_FS_REFER;
__attribute__((fallthrough));
case 2:
/* Removes LANDLOCK_ACCESS_FS_TRUNCATE for ABI < 3 */
ruleset_attr.handled_access_fs &= ~LANDLOCK_ACCESS_FS_TRUNCATE;
__attribute__((fallthrough));
case 3:
/* Removes network support for ABI < 4 */
ruleset_attr.handled_access_net &=
~(LANDLOCK_ACCESS_NET_BIND_TCP |
LANDLOCK_ACCESS_NET_CONNECT_TCP);
__attribute__((fallthrough));
case 4:
/* Removes LANDLOCK_ACCESS_FS_IOCTL_DEV for ABI < 5 */
ruleset_attr.handled_access_fs &= ~LANDLOCK_ACCESS_FS_IOCTL_DEV;
__attribute__((fallthrough));
case 5:
/* Removes LANDLOCK_SCOPE_* for ABI < 6 */
ruleset_attr.scoped &= ~(LANDLOCK_SCOPE_ABSTRACT_UNIX_SOCKET |
LANDLOCK_SCOPE_SIGNAL);
}
Let’s see a simple example to sandbox a process from communicating through TCP.
#define _GNU_SOURCE
#include <linux/landlock.h>
#include <sys/prctl.h>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include <errno.h>
#include <string.h>
#include <sys/syscall.h>
static inline int landlock_create_ruleset(const struct landlock_ruleset_attr *attr, size_t size, __u32 flags) {
return syscall(__NR_landlock_create_ruleset, attr, size, flags);
}
static inline int landlock_restrict_self(int ruleset_fd) {
return syscall(__NR_landlock_restrict_self, ruleset_fd, 0);
}
int main(int argc, char **argv) {
if (argc < 2) {
fprintf(stderr, "Usage: %s <binary> [args...]\n", argv[0]);
return 1;
}
int abi = landlock_create_ruleset(NULL, 0, LANDLOCK_CREATE_RULESET_VERSION);
if (abi < 4) {
fprintf(stderr, "Landlock network restrictions are not supported (need ABI >= 4).\n");
fprintf(stderr, "Running %s without Landlock.\n", argv[1]);
execvp(argv[1], &argv[1]);
perror("execvp");
return 1;
}
struct landlock_ruleset_attr ruleset_attr = {
.handled_access_net = LANDLOCK_ACCESS_NET_CONNECT_TCP | LANDLOCK_ACCESS_NET_BIND_TCP
};
int ruleset_fd = landlock_create_ruleset(&ruleset_attr, sizeof(ruleset_attr), 0);
if (ruleset_fd < 0) {
perror("landlock_create_ruleset");
return 1;
}
if (prctl(PR_SET_NO_NEW_PRIVS, 1, 0, 0, 0)) {
perror("prctl(PR_SET_NO_NEW_PRIVS)");
close(ruleset_fd);
return 1;
}
if (landlock_restrict_self(ruleset_fd)) {
perror("landlock_restrict_self");
close(ruleset_fd);
return 1;
}
close(ruleset_fd);
execvp(argv[1], &argv[1]);
perror("execvp failed");
return 1;
}
First, we define inline helper functions to provide a simplified interface for the landlock_create_ruleset and landlock_restrict_self system calls.
static inline int landlock_create_ruleset(const struct landlock_ruleset_attr *attr, size_t size, __u32 flags) {
return syscall(__NR_landlock_create_ruleset, attr, size, flags);
}
static inline int landlock_restrict_self(int ruleset_fd) {
return syscall(__NR_landlock_restrict_self, ruleset_fd, 0);
}
Then, check Landlock ABI support (version >=4 supports network restrictions):
int abi = landlock_create_ruleset(NULL, 0, LANDLOCK_CREATE_RULESET_VERSION);
if (abi < 4) {
fprintf(stderr, "Landlock network restrictions are not supported (need ABI >= 4).\n");
fprintf(stderr, "Running %s without Landlock.\n", argv[1]);
execvp(argv[1], &argv[1]);
perror("execvp");
return 1;
}
Then, define rules using landlock_ruleset_attr data structure:
struct landlock_ruleset_attr ruleset_attr = {
.handled_access_net = LANDLOCK_ACCESS_NET_CONNECT_TCP | LANDLOCK_ACCESS_NET_BIND_TCP
};
Next, Ruleset creation using landlock_create_ruleset() syscall and get ruleset_fd as return value:
int ruleset_fd = landlock_create_ruleset(&ruleset_attr, sizeof(ruleset_attr), 0);
if (ruleset_fd < 0) {
perror("landlock_create_ruleset");
return 1;
}
Then, prevent the process from gaining new privileges using prctl:
if (prctl(PR_SET_NO_NEW_PRIVS, 1, 0, 0, 0)) {
perror("prctl(PR_SET_NO_NEW_PRIVS)");
close(ruleset_fd);
return 1;
}
Finally, enforce rules using landlock_restrict_self() syscall:
if (landlock_restrict_self(ruleset_fd)) {
perror("landlock_restrict_self");
close(ruleset_fd);
return 1;
}
Compile the code gcc -Wall landlock_no_tcp.c -o landlock_no_tcp, then, let’s test it ./landlock_no_tcp ssh 192.168.1.2
ssh: connect to host 192.168.1.2 port 22: Permission denied
We can see why this happened using strace ./landlock_no_tcp ssh 192.168.1.2:
[...]
socket(AF_INET, SOCK_STREAM, IPPROTO_TCP) = 3
fcntl(3, F_SETFD, FD_CLOEXEC) = 0
getsockname(3, {sa_family=AF_INET, sin_port=htons(0), sin_addr=inet_addr("0.0.0.0")}, [128 => 16]) = 0
setsockopt(3, SOL_IP, IP_TOS, [16], 4) = 0
connect(3, {sa_family=AF_INET, sin_port=htons(22), sin_addr=inet_addr("192.168.1.2")}, 16) = -1 EACCES (Permission denied)
close(3) = 0
getpid() = 2245
write(2, "ssh: connect to host 192.168.1.2"..., 61ssh: connect to host 192.168.1.2 port 22: Permission denied
) = 61
munmap(0x7f9c722d3000, 135168) = 0
exit_group(255) = ?
+++ exited with 255 +++
We can see what is going to happen if we use sudo strace ./landlock_no_tcp sudo ssh 192.168.1.2
[...]
read(3, "", 4096) = 0
close(3) = 0
geteuid() = 1000
prctl(PR_GET_NO_NEW_PRIVS, 0, 0, 0, 0) = 1
openat(AT_FDCWD, "/usr/share/locale/locale.alias", O_RDONLY|O_CLOEXEC) = 3
fstat(3, {st_mode=S_IFREG|0644, st_size=2996, ...}) = 0
read(3, "# Locale name alias data base.\n#"..., 4096) = 2996
read(3, "", 4096) = 0
close(3) = 0
write(2, "sudo", 4sudo) = 4
write(2, ": ", 2: ) = 2
write(2, "The \"no new privileges\" flag is "..., 78The "no new privileges" flag is set, which prevents sudo from running as root.) = 78
[...]
The output should look like the following:
sudo: The "no new privileges" flag is set, which prevents sudo from running as root.
sudo: If sudo is running in a container, you may need to adjust the container configuration to disable the flag.
Below another simplified example illustrating how to use Landlock to allow read-only access to /usr and /etc/ssl/certs while permitting only TCP port 443 connections, and denying all other filesystem and TCP actions:
#define _GNU_SOURCE
#include <linux/landlock.h>
#include <sys/prctl.h>
#include <sys/syscall.h>
#include <fcntl.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <errno.h>
static inline int landlock_create_ruleset(const struct landlock_ruleset_attr *attr, size_t size, __u32 flags) {
return syscall(__NR_landlock_create_ruleset, attr, size, flags);
}
static inline int landlock_add_rule(int ruleset_fd, enum landlock_rule_type rule_type, const void *rule_attr, __u32 flags) {
return syscall(__NR_landlock_add_rule, ruleset_fd, rule_type, rule_attr, flags);
}
static inline int landlock_restrict_self(int ruleset_fd, __u32 flags) {
return syscall(__NR_landlock_restrict_self, ruleset_fd, flags);
}
int main(int argc, char *argv[]) {
if (argc < 2) {
fprintf(stderr, "Usage: %s <binary-to-sandbox> [args...]\n", argv[0]);
return 1;
}
int abi = landlock_create_ruleset(NULL, 0, LANDLOCK_CREATE_RULESET_VERSION);
if (abi < 0) {
fprintf(stderr, "Landlock not available. Running %s without restrictions.\n", argv[1]);
execvp(argv[1], &argv[1]);
perror("execvp");
return 1;
}
struct landlock_ruleset_attr ruleset_attr = {
.handled_access_fs =
LANDLOCK_ACCESS_FS_EXECUTE |
LANDLOCK_ACCESS_FS_READ_FILE |
LANDLOCK_ACCESS_FS_READ_DIR,
.handled_access_net = LANDLOCK_ACCESS_NET_BIND_TCP | LANDLOCK_ACCESS_NET_CONNECT_TCP,
};
int ruleset_fd = landlock_create_ruleset(&ruleset_attr, sizeof(ruleset_attr), 0);
if (ruleset_fd < 0) {
perror("landlock_create_ruleset");
return 1;
}
struct landlock_path_beneath_attr usr_attr = {
.allowed_access = LANDLOCK_ACCESS_FS_READ_FILE | LANDLOCK_ACCESS_FS_READ_DIR | LANDLOCK_ACCESS_FS_EXECUTE
};
usr_attr.parent_fd = open("/usr", O_PATH | O_CLOEXEC);
if (usr_attr.parent_fd < 0) {
perror("open /usr");
close(ruleset_fd);
return 1;
}
if (landlock_add_rule(ruleset_fd, LANDLOCK_RULE_PATH_BENEATH, &usr_attr, 0) < 0) {
perror("landlock_add_rule (/usr)");
close(usr_attr.parent_fd);
close(ruleset_fd);
return 1;
}
close(usr_attr.parent_fd);
struct landlock_path_beneath_attr ssl_attr = {
.allowed_access = LANDLOCK_ACCESS_FS_READ_FILE | LANDLOCK_ACCESS_FS_READ_DIR
};
ssl_attr.parent_fd = open("/etc/ssl/certs", O_PATH | O_CLOEXEC);
if (ssl_attr.parent_fd < 0) {
perror("open /etc/ssl/certs");
close(ruleset_fd);
return 1;
}
if (landlock_add_rule(ruleset_fd, LANDLOCK_RULE_PATH_BENEATH, &ssl_attr, 0) < 0) {
perror("landlock_add_rule (/etc/ssl/certs)");
close(ssl_attr.parent_fd);
close(ruleset_fd);
return 1;
}
close(ssl_attr.parent_fd);
if (abi >= 4) {
struct landlock_net_port_attr net_attr = {
.allowed_access = LANDLOCK_ACCESS_NET_CONNECT_TCP,
.port = 443
};
if (landlock_add_rule(ruleset_fd, LANDLOCK_RULE_NET_PORT, &net_attr, 0) < 0) {
perror("landlock_add_rule (HTTPS only)");
close(ruleset_fd);
return 1;
}
}
if (prctl(PR_SET_NO_NEW_PRIVS, 1, 0, 0, 0)) {
perror("prctl(PR_SET_NO_NEW_PRIVS)");
close(ruleset_fd);
return 1;
}
if (landlock_restrict_self(ruleset_fd, 0)) {
perror("landlock_restrict_self");
close(ruleset_fd);
return 1;
}
close(ruleset_fd);
execvp(argv[1], &argv[1]);
perror("execvp failed");
return 1;
}
Here we defined rules for file access and network access then ruleset creation :
struct landlock_ruleset_attr ruleset_attr = {
.handled_access_fs =
LANDLOCK_ACCESS_FS_EXECUTE |
LANDLOCK_ACCESS_FS_READ_FILE |
LANDLOCK_ACCESS_FS_READ_DIR,
.handled_access_net = LANDLOCK_ACCESS_NET_BIND_TCP | LANDLOCK_ACCESS_NET_CONNECT_TCP,
};
int ruleset_fd = landlock_create_ruleset(&ruleset_attr, sizeof(ruleset_attr), 0);
if (ruleset_fd < 0) {
perror("landlock_create_ruleset");
return 1;
}
Then, allow read-only and execute rights to /usr:
struct landlock_path_beneath_attr usr_attr = {
.allowed_access = LANDLOCK_ACCESS_FS_READ_FILE | LANDLOCK_ACCESS_FS_READ_DIR | LANDLOCK_ACCESS_FS_EXECUTE
};
usr_attr.parent_fd = open("/usr", O_PATH | O_CLOEXEC);
if (usr_attr.parent_fd < 0) {
perror("open /usr");
close(ruleset_fd);
return 1;
}
if (landlock_add_rule(ruleset_fd, LANDLOCK_RULE_PATH_BENEATH, &usr_attr, 0) < 0) {
perror("landlock_add_rule (/usr)");
close(usr_attr.parent_fd);
close(ruleset_fd);
return 1;
}
close(usr_attr.parent_fd);
Then, allow read-only access to /etc/ssl/certs:
struct landlock_path_beneath_attr ssl_attr = {
.allowed_access = LANDLOCK_ACCESS_FS_READ_FILE | LANDLOCK_ACCESS_FS_READ_DIR
};
ssl_attr.parent_fd = open("/etc/ssl/certs", O_PATH | O_CLOEXEC);
if (ssl_attr.parent_fd < 0) {
perror("open /etc/ssl/certs");
close(ruleset_fd);
return 1;
}
if (landlock_add_rule(ruleset_fd, LANDLOCK_RULE_PATH_BENEATH, &ssl_attr, 0) < 0) {
perror("landlock_add_rule (/etc/ssl/certs)");
close(ssl_attr.parent_fd);
close(ruleset_fd);
return 1;
}
close(ssl_attr.parent_fd);
Next, ensure network control is supported by the kernel then allow only TCP port 443:
if (abi >= 4) {
struct landlock_net_port_attr net_attr = {
.allowed_access = LANDLOCK_ACCESS_NET_CONNECT_TCP,
.port = 443
};
if (landlock_add_rule(ruleset_fd, LANDLOCK_RULE_NET_PORT, &net_attr, 0) < 0) {
perror("landlock_add_rule (HTTPS only)");
close(ruleset_fd);
return 1;
}
}
Running ./landlock_tcp_bin curl https://8.8.8.8 TCP port 443:
<HTML><HEAD><meta http-equiv="content-type" content="text/html;charset=utf-8">
<TITLE>302 Moved</TITLE></HEAD><BODY>
<H1>302 Moved</H1>
The document has moved
<A HREF="https://dns.google/">here</A>.
</BODY></HTML>
Running ./landlock_tcp_bin curl http://1.1.1.1 TCP port 80:
curl: (7) Failed to connect to 1.1.1.1 port 80 after 0 ms: Could not connect to server
Running ./landlock_tcp_bin ls /etc
ls: cannot open directory '/etc': Permission denied
Let’s move on to some tools that can help with advanced monitoring and control or a kind of next-level firewalling.
4 - bpf_send_signal
bpf_send_signal() is a helper function that allows a eBPF program to send a Unix signal (e.g., SIGUSR1, SIGKILL, etc.) to the current process (the process that triggered execution of the BPF program). If an anomaly is detected (e.g., unauthorized file access, network connections, or excessive resource usage), the eBPF program can send a signal to terminate the offending process. bpf_send_signal_thread() helper function is similar to bpf_send_signal() except it will send a signal to thread corresponding to the current task.
bpf_send_signal has the following prototype:
static long (* const bpf_send_signal)(__u32 sig) = (void *) 109;
sys_ptrace is a system call in Linux and other Unix-like operating systems that allows one process (the tracer) to observe and control the execution of another process (the tracee). The following example, we attached kprobe to sys_ptrace syscall and monitor this call to only allow root (UID = 0) to call this syscall. If UID not zero (non-root user) hen the process will be terminated using bpf_send_signal() helper function.
#define __TARGET_ARCH_x86
#include <linux/bpf.h>
#include <bpf/bpf_helpers.h>
#define ALLOWED_UID 0
char LICENSE[] SEC("license") = "GPL";
SEC("kprobe/__x64_sys_ptrace")
int BPF_KPROBE__x64_sys_ptrace(void)
{
__u64 uid_gid = bpf_get_current_uid_gid();
__u32 uid = (__u32)uid_gid;
if (uid != ALLOWED_UID) {
bpf_printk("Unauthorized ptrace attempt by uid %d\n", uid);
bpf_send_signal(9);
}
return 0;
}
User-space code
#include <stdio.h>
#include <unistd.h>
#include <sys/resource.h>
#include <bpf/libbpf.h>
#include "signal_ptrace.skel.h"
static int libbpf_print_fn(enum libbpf_print_level level, const char *format, va_list args)
{
return vfprintf(stderr, format, args);
}
int main(int argc, char **argv)
{
struct signal_ptrace *skel;
int err;
libbpf_set_print(libbpf_print_fn);
skel = signal_ptrace__open();
if (!skel) {
fprintf(stderr, "Failed to open BPF skeleton\n");
return 1;
}
err = signal_ptrace__load(skel);
if (err) {
fprintf(stderr, "Failed to load and verify BPF skeleton\n");
goto cleanup;
}
err = signal_ptrace__attach(skel);
if (err) {
fprintf(stderr, "Failed to attach BPF skeleton\n");
goto cleanup;
}
printf("Successfully started! Please run `sudo cat /sys/kernel/debug/tracing/trace_pipe` "
"to see output of the BPF programs.\n");
for (;;) {
fprintf(stderr, ".");
sleep(1);
}
cleanup:
signal_ptrace__destroy(skel);
return -err;
}
Compile the code, then generate skeleton file , then compile the loader code. When trying to trigger ptrace syscall with a tool like strace
strace /usr/bin/ls
Killed
Viewing the trace pipe file sudo cat /sys/kernel/debug/tracing/trace_pipe will give similar output:
strace-3402 [001] ...21 16100.793628: bpf_trace_printk: Unauthorized ptrace attempt by uid 1000
Below is an example write-up that describes an imaginary privilege escalation scenario and shows the eBPF code that detects the specific syscall sequence (fork, setuid(0), and execve) to terminate the process.
Imagine an attacker attempts a privilege escalation by using the following assembly code to fork, set UID to 0, and finally execute /bin/bash to spawn a root shell:
section .data
cmd db "/bin/bash", 0
section .text
global _start
_start:
; Fork syscall
mov eax, 57
xor edi, edi
syscall
test eax, eax
jz child_process
; Parent process
; Setuid syscall
mov eax, 105
xor edi, edi
syscall
cmp eax, 0
jne exit_program
; Execve syscall
mov eax, 59
mov rdi, cmd
xor rsi, rsi
xor rdx, rdx
syscall
exit_program:
mov eax, 60
xor edi, edi
syscall
child_process:
; Child process
xor eax, eax
ret
First, we compile it using
nasm -f elf64 -o privilege_escalation.o privilege_escalation.asm
Then link it
ld -o privilege_escalation privilege_escalation.o`
We build an eBPF program that uses bpf_send_signal to monitor for a suspicious sequence of syscalls. If the program detects that a process has forked, then called setuid(0), and finally executed execve to run /bin/bash (spawning a root shell), it will immediately fire a signal to terminate that process.
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_core_read.h>
struct {
__uint(type, BPF_MAP_TYPE_HASH);
__uint(max_entries, 1024);
__type(key, u32);
__type(value, u8);
} forks SEC(".maps");
struct {
__uint(type, BPF_MAP_TYPE_HASH);
__uint(max_entries, 1024);
__type(key, u32);
__type(value, u8);
} setuid SEC(".maps");
char LICENSE[] SEC("license") = "GPL";
SEC("tracepoint/syscalls/sys_enter_fork")
int trace_fork(struct trace_event_raw_sys_enter *ctx)
{
u32 pid = bpf_get_current_pid_tgid() >> 32;
u8 val = 1;
bpf_map_update_elem(&forks, &pid, &val, BPF_ANY);
bpf_printk("Fork detected: PID %d\n", pid);
return 0;
}
SEC("tracepoint/syscalls/sys_enter_setuid")
int trace_setuid(struct trace_event_raw_sys_enter *ctx)
{
u32 uid = ctx->args[0];
if (uid == 0) {
u32 pid = bpf_get_current_pid_tgid() >> 32;
u8 val = 1;
bpf_map_update_elem(&setuid, &pid, &val, BPF_ANY);
bpf_printk("Setuid detected: PID %d\n", pid);
}
return 0;
}
SEC("tracepoint/syscalls/sys_enter_execve")
int trace_execve(struct trace_event_raw_sys_enter *ctx)
{
u32 pid = bpf_get_current_pid_tgid() >> 32;
u8 *forked = bpf_map_lookup_elem(&forks, &pid);
u8 *priv = bpf_map_lookup_elem(&setuid, &pid);
if (forked && priv) {
bpf_printk("Privilege escalation detected: fork, setuid(0), execve, PID %d\n", pid);
bpf_send_signal(9);
}
return 0;
}
sudo ./privilege_escalation
priv-3654 [...] Fork detected: PID 3654
priv-3654 [...] Setuid detected: PID 3654
priv-3654 [...] Privilege escalation detected: fork, setuid(0), execve, PID 3654
5 - Tetragon
Tetragon is an open-source tool that uses eBPF to monitor and control Linux systems. It tracks events like process execution, network connections, and file access in real time. You can write custom rules to filter these events, and it runs with very little performance impact. Although it works great with Kubernetes and container setups, it can secure any Linux system that supports eBPF. Its kernel-level enforcement can, for example, kill a process if it violates a rule, adding a strong layer of security. Tetragon can be installed from their website, consider download it to follow this part.
Tetragon works by using policies called TracingPolicies. These policies let you define exactly what kernel events to monitor and what actions to take when those events happen. You write rules in a policy that attach probes to kernel functions, filter events based on criteria like arguments or process IDs, and then enforce actions (for example, killing a process) if a rule is matched. This approach gives you fine-grained control over system security in real time. Let’s take a glimpse of what Tetragon can do.
TracingPolicy
A TracingPolicy is a YAML document that follows Kubernetes’ API conventions. Even if you’re running Tetragon on a CLI (non-Kubernetes) installation, the policy structure remains similar. At its simplest, a tracing policy must include:
API Version and Kind: This tells Tetragon which version of the API you’re using and what type of object you’re creating. For tracing policies, you typically use:
apiVersion: cilium.io/v1alpha1
kind: TracingPolicy
Metadata: Metadata includes a unique name for your policy.
metadata:
name: "example-policy"
Spec Section
Spec: The spec contains all the configuration details about what you want to trace and how. It’s where you define:
- The hook point (e.g., a kernel function to monitor)
- Which arguments you want to capture
- Selectors (in-kernel filters) to determine when the policy should trigger, and
- The actions to execute when a match occurs.
The hook point is the entry point where Tetragon attaches its BPF program. You have several options: kprobes, tracepoints, uprobes and lsmhooks.
Let’s say you want to monitor do_mkdirat kernel function. You would specify:
spec:
kprobes:
- call: "do_mkdirat"
syscall: false
args:
- index: 0
type: "int"
- index: 1
type: "filename"
- index: 2
type: "int"
What This Means:
- You are instructing Tetragon to insert a kprobe into
do_mkdiratkernel function and it’s not a syscall. - The policy tells the eBPF code to extract three arguments: the integer value (the file descriptor number), the filename structure (which include the file path) and integer value as mode.
In some cases, you want to capture the return value from a function. To do so, set the
returnflag to true, define areturnArg, and specify its type. This is useful when you want to track how a function completes.
spec:
kprobes:
- call: "do_mkdirat"
syscall: false
return: true
args:
- index: 0
type: "int"
- index: 1
type: "filename"
- index: 2
type: "int"
returnArg:
index: 0
type: "int"
Selectors
Selectors are the core of in-kernel filtering. They allow you to define conditions that must be met for the policy to apply and actions to be triggered. Within a selector, you can include one or more filters.
Filter Types
Each probe can contain up to 5 selectors and each selector can contain one or more filter. Below is a table summarizing the available filters, their definitions, and the operators they support:
| Filter Name | Definition | Operators |
|---|---|---|
| matchArgs | Filters on the value of function arguments. | Equal, NotEqual, Prefix, Postfix, Mask, GreaterThan (GT), LessThan (LT), SPort, NotSPort, SPortPriv, NotSPortPriv, DPort, NotDPort, DPortPriv, NotDPortPriv, SAddr, NotSAddr, DAddr, NotDAddr, Protocol, Family, State |
| matchReturnArgs | Filters based on the function’s return value. | Equal, NotEqual, Prefix, Postfix |
| matchPIDs | Filters on the host PID of the process. | In, NotIn |
| matchBinaries | Filters on the binary path (or name) of the process invoking the event. | In, NotIn, Prefix, NotPrefix, Postfix, NotPostfix |
| matchNamespaces | Filters based on Linux namespace values. | In, NotIn |
| matchCapabilities | Filters based on Linux capabilities in the specified set (Effective, Inheritable, or Permitted). | In, NotIn |
| matchNamespaceChanges | Filters based on changes in Linux namespaces (e.g., when a process changes its namespace). | In |
| matchCapabilityChanges | Filters based on changes in Linux capabilities (e.g., when a process’s capabilities are altered). | In |
| matchActions | Applies an action when the selector matches (executed directly in kernel BPF code or in userspace for some actions). | Not a traditional filter; supports action types such as: Sigkill, Signal, Override, FollowFD, UnfollowFD, CopyFD, GetUrl, DnsLookup, Post, NoPost, TrackSock, UntrackSock, NotifyEnforcer. |
| matchReturnActions | Applies an action based on the return value matching the selector. | Similar to matchActions; supports action types (as above) that are executed on return events. |
matchArgs: Filter on a specific argument’s value (if filename = /etc/passwd)
selectors:
- matchArgs:
- index: 1
operator: "Equal"
values:
- "/etc/shadow"
matchBinaries: Filters based on the binary path or name of the process invoking the function.
- matchBinaries:
- operator: "In"
values:
- "/usr/bin/sudo"
- "/usr/bin/su"
Imagine you want to monitor any process that tries to open the file /etc/shadow or /etc/passwd. You might set up a selector that uses matchArgs filter:
spec:
kprobes:
- call: "sys_openat"
syscall: true
args:
- index: 0
type: int
- index: 1
type: "string"
- index: 2
type: "int"
selectors:
- matchArgs:
- index: 1
operator: "Equal"
values:
- "/etc/passwd"
- "/etc/shadow"
First, filter on the second parameter (index=1), then match it with (/etc/passwd or /etc/shadow).
Note
Instead of writing the full name of syscalls such as__x64_sys_openat you can just use sys_openat and Tetragon will take care of the prefix of the syscall based on the architecture of you machine.
Actions
matchActions and matchReturnActions: These attach actions to be executed when the selector matches. They also allow you to filter based on the value of return arguments (if needed).
Actions are what your policy does when a selector matches. They allow you to enforce decisions right in the kernel. Some common actions include:
Sigkill and Signal: immediately terminates the offending process.
matchActions:
- action: Sigkill
To send a specific signal (e.g., SIGKILL which is signal 9)
matchActions:
- action: Signal
argSig:
Override: Modifies the return value of a function, which can cause the caller to receive an error code. This action uses the error injection framework.
- matchActions:
- action: Override
argError: -1
Note
Override function used for error injection. Due to security implications, override function is available only if the kernel was compiled withCONFIG_BPF_KPROBE_OVERRIDE option. There is a list of all function that support override and they are tagged with ALLOW_ERROR_INJECTION and they are located at /sys/kernel/debug/error_injection/list.
FollowFD, UnfollowFD and CopyFD: These actions help track file descriptor usage. For example, you can map a file descriptor to a file name during an open call, so that later calls (e.g., sys_write) that only have an FD can be correlated to a file path. The best example to explain FollowFD / UnfollowFD is from Tetragon documentation. This example is how to prevent write to a specific files for example /etc/passwd. sys_write only takes a file descriptor not a name and location. First we hook to fd_install kernel function.
fd_install is a kernel function that’s called when a file descriptor is being added to a process’s file descriptor table. In simpler terms, when a process opens a file (or performs a similar operation that creates a file descriptor), fd_install is invoked to associate the new file descriptor (an integer) with the corresponding file object. fd_install has the following prototype:
void fd_install(unsigned int fd, struct file *file);
Note
Tetragon is planing to removeFollowFD, UnfollowFD and CopyFD starting from Tetragon version 1.5 due to security concerns.
kprobes:
- call: "fd_install"
syscall: false
args:
- index: 0
type: int
- index: 1
type: "file"
selectors:
- matchArgs:
- index: 1
operator: "Equal"
values:
- "/etc/passwd"
matchActions:
- action: FollowFD
argFd: 0
argName: 1
- call: "sys_write"
syscall: true
args:
- index: 0
type: "fd"
- index: 1
type: "char_buf"
sizeArgIndex: 3
- index: 2
type: "size_t"
selectors:
- matchArgs:
- index: 0
operator: "Equal"
values:
- "/etc/passwd"
matchActions:
- action: Sigkill
- call: "sys_close"
syscall: true
args:
- index: 0
type: "int"
selectors:
- matchActions:
- action: UnfollowFD
argFd: 0
argName: 0
In the previous example, the second argument is defined as file type as the name of the kernel data structure struct file:
- index: 1
type: "file"
Post: Sends an event up to user space. You can also ask for kernel and user stack traces to be included, and even limit how often these events fire.
selectors:
- matchArgs:
- index: 1
operator: "Equal"
values:
- "/etc/passwd"
matchActions:
- action: Post
rateLimit: 5m
kernelStackTrace: true
userStackTrace: true
GetUrl and DnsLookup: The GetUrl action triggers an HTTP GET request to a specified URLargUrl. The DnsLookup action initiates a DNS lookup for a specified fully qualified domain name (FQDN) argFqdn.
Both actions are used to notify external systems when a specific event occurs in the kernel such as (Thinkst canaries or webhooks).
matchActions:
- action: GetUrl
argUrl: http://example.com/trigger
matchActions:
- action: DnsLookup
argFqdn: canary.example.com
Below is a complete tracing policy example that monitors when mkdir attempts to create test. When it does, the policy sends a SIGKILL signal to the offending process.
apiVersion: cilium.io/v1alpha1
kind: TracingPolicy
metadata:
name: "kill-mkdir-test"
spec:
kprobes:
- call: "do_mkdirat"
syscall: false
args:
- index: 0
type: "int"
- index: 1
type: "filename"
- index: 2
type: "int"
selectors:
- matchArgs:
- index: 1
operator: "Equal"
values:
- "test"
matchActions:
- action: Sigkill
Running this policy using sudo tetragon --tracing-policy mkdir.yaml. Output can be monitored using sudo tetra getevents -o compact
process mac-Standard-PC-Q35-ICH9-2009 /usr/bin/mkdir ../tmp/test
syscall mac-Standard-PC-Q35-ICH9-2009 /usr/bin/mkdir do_mkdirat
exit mac-Standard-PC-Q35-ICH9-2009 /usr/bin/mkdir ../tmp/test SIGKILL
Another example for blocking reading files from a specific directory using file_open hook in LSM:
apiVersion: cilium.io/v1alpha1
kind: TracingPolicy
metadata:
name: "Block-screct-files"
spec:
lsmhooks:
- hook: "file_open"
args:
- index: 0
type: "file"
selectors:
- matchArgs:
- index: 0
operator: "Prefix"
values:
- "/tmp/secret/"
matchActions:
- action: Sigkill
process mac-Standard-PC-Q35-ICH9-2009 /usr/bin/cat /tmp/secret/test1
LSM mac-Standard-PC-Q35-ICH9-2009 /usr/bin/cat file_open
exit mac-Standard-PC-Q35-ICH9-2009 /usr/bin/cat /tmp/secret/test1 SIGKILL
We can specify a specific binary to block. For example, to block only cat command:
selectors:
- matchBinaries:
- operator: "In"
values:
- "/usr/bin/cat"
matchArgs:
- index: 0
operator: "Prefix"
values:
- "/tmp/secret/"
Another example to block wget command from accessing port 443. We used DPort to define destination port:
apiVersion: cilium.io/v1alpha1
kind: TracingPolicy
metadata:
name: "block-443-for-wget"
spec:
kprobes:
- call: "tcp_connect"
syscall: false
args:
- index: 0
type: "sock"
selectors:
- matchBinaries:
- operator: "In"
values:
- "/usr/bin/wget"
matchArgs:
- index: 0
operator: "DPort"
values:
- 443
matchActions:
- action: Sigkill
wget command is blocked while curl command is working!
process mac-Standard-PC-Q35-ICH9-2009 /usr/bin/wget https://8.8.8.8
connect mac-Standard-PC-Q35-ICH9-2009 /usr/bin/wget tcp 192.168.122.215:60914 -> 8.8.8.8:443
exit mac-Standard-PC-Q35-ICH9-2009 /usr/bin/wget https://8.8.8.8 SIGKILL
process mac-Standard-PC-Q35-ICH9-2009 /usr/bin/curl https://8.8.8.8
exit mac-Standard-PC-Q35-ICH9-2009 /usr/bin/curl https://8.8.8.8 0
Example for monitoring sudo command using __sys_setresuid kernel function.
__sys_setresuid is the kernel function that implements the setresuid system call. It changes a process’s user IDs—specifically, the real, effective, and saved user IDs—in one atomic operation and it’s used to adjust process privileges.
apiVersion: cilium.io/v1alpha1
kind: TracingPolicy
metadata:
name: "detect-sudo"
spec:
kprobes:
- call: "__sys_setresuid"
syscall: false
args:
- index: 0
type: "int"
- index: 1
type: "int"
- index: 2
type: "int"
selectors:
- matchArgs:
- index: 1
operator: "Equal"
values:
- "0"
Tetragon can be configured to send metrics to Prometheus to monitor activities observed by Tetragon. It has also Elastic integration. Tetragon has policy library and many useful use cases in their documentation. It’s a powerful tool and even fun to try it.
6 - Bpfilter
bpfilter is a eBPF-based packet filtering currently maintained by meta, designed to replace or complement traditional packet filtering systems such as netfilter/iptables. It leverages the power of eBPF programs to implement filtering directly in the kernel. bpfilter is part of a broader shift towards eBPF-driven networking, moving away from older, monolithic approaches with minimal overhead.
bpfilter consists of two parts: daemon and front-ends. Font-end such as bfcli which receives firewall rules from administrators and send them to the daemon (bpfilter). bpfilter daemon parses the ruleset whether provided directly as a string or loaded from a file and then translates these high-level rules into eBPF bytecode that can be executed in the kernel.
bpfilter attaches the generated eBPF programs to specific kernel hooks such as XDP, TC (Traffic Control), or netfilter hooks (like NF_PRE_ROUTING, NF_LOCAL_IN, etc.). Each hook corresponds to a different stage in the packet processing pipeline, allowing bpfilter to intercept packets as early or as late as necessary.
Install bpfilter
Follow the following instructions to install bpfilter on ubuntu 24.04/ debian 13. Install dependencies:
sudo apt install bison clang-format clang-tidy cmake doxygen flex furo git lcov libbpf-dev libcmocka-dev libbenchmark-dev libgit2-dev libnl-3-dev python3-breathe python3-pip python3-sphinx pkgconf
Download bpfilter:
git clone https://github.com/facebook/bpfilter.git
Make bpfilter:
cd bpfilter/
export SOURCES_DIR=$(pwd)
export BUILD_DIR=$SOURCES_DIR/build
cmake -S $SOURCES_DIR -B $BUILD_DIR
make -C $BUILD_DIR
Note
bpfilter can use custom versioniptables and nftables and supply your rules in either iptables syntax or nftables syntax such dropping incoming ICMP with iptables using --bpf flag as the following:sudo ./iptables --bpf -D INPUT -p icmp -j DROP
Follow the following instructions to install the custom iptables and nftables on ubuntu 24.04
Install dependencies:
sudo apt install autoconf libtool libmnl-dev libnftnl-dev libgmp-dev libedit-dev
Make the custom iptables and nftables:
make -C $BUILD_DIR nftables iptables
bpfilter rules
A bpfilter ruleset is defined using chains and rules with the following structure:
chain $HOOK policy $POLICY
rule
$MATCHER
$VERDICT
[...]
[...]
chain $HOOK policy $POLICY
$HOOK: The kernel hook where the chain is attached. The following list is from bpfilter documentation:
BF_HOOK_XDP: XDP hook.
BF_HOOK_TC_INGRESS: ingress TC hook.
BF_HOOK_NF_PRE_ROUTING: similar to nftables and iptables prerouting hook.
BF_HOOK_NF_LOCAL_IN: similar to nftables and iptables input hook.
BF_HOOK_CGROUP_INGRESS: ingress cgroup hook.
BF_HOOK_CGROUP_EGRESS: egress cgroup hook.
BF_HOOK_NF_FORWARD: similar to nftables and iptables forward hook.
BF_HOOK_NF_LOCAL_OUT: similar to nftables and iptables output hook.
BF_HOOK_NF_POST_ROUTING: similar to nftables and iptables postrouting hook.
BF_HOOK_TC_EGRESS: egress TC hook.
$POLICY: The default action (typically ACCEPT or DROP) applied to packets that do not match any rule in the chain.
Rule: Each rule under the chain consists of one or more matchers followed by a verdict.
$MATCHER: A condition (or multiple conditions) that compares parts of the packet. For example, checking the protocol or matching an IP address.
$VERDICT: The action to take if the matchers are true. Common verdicts are:
ACCEPT: Let the packet continue through the network stack.DROP: Discard the packet.CONTINUE: Continue to the next rule (often used in conjunction with packet counting).
The following tables are from the bpfilter documentation and they contain detailed information about the various matchers used in bpfilter for filtering network traffic. Each table lists the matcher name (the field of the packet), its corresponding type in bpfilter (for example, udp.sport or tcp.sport), the operator used for comparison (such as eq, not, or range), the payload (the value or range to compare against), and additional notes that explain usage constraints or default behaviors.
Meta matchers
| Matches | Type | Operator | Payload | Notes |
|---|---|---|---|---|
| Interface index | meta.ifindex |
eq | $IFINDEX |
For chains attached to an ingress hook, $IFINDEX is the input interface index. For chains attached to an egress hook, $IFINDEX is the output interface index. |
| L3 protocol | meta.l3_proto |
eq | $PROTOCOL |
ipv4 and ipv6 are supported. |
| L4 protocol | meta.l4_proto |
eq | $PROTOCOL |
icmp, icmpv6, tcp, udp are supported. |
| Source port | meta.sport |
eq | $PORT |
$PORT is a valid port value, as a decimal integer. |
| Source port | meta.sport |
not | $PORT |
$PORT is a valid port value, as a decimal integer. (Same payload and note as above) |
| Source port | meta.sport |
range | $START-$END |
$START and $END are valid port values, as decimal integers. |
| Destination port | meta.dport |
eq | $PORT |
$PORT is a valid port value, as a decimal integer. |
| Destination port | meta.dport |
not | $PORT |
$PORT is a valid port value, as a decimal integer. (Same payload and note as above) |
| Destination port | meta.dport |
range | $START-$END |
$START and $END are valid port values, as decimal integers. |
IPv4 matchers
| Matches | Type | Operator | Payload | Notes |
|---|---|---|---|---|
| Source address | ip4.saddr |
eq | $IP/$MASK |
/$MASK is optional, /32 is used by default. |
| Source address | ip4.saddr |
not | $IP/$MASK |
/$MASK is optional, /32 is used by default. |
| Source address | ip4.saddr |
in | {$IP[,...]} |
Only support /32 mask. |
| Destination address | ip4.daddr |
eq | $IP/$MASK |
/$MASK is optional, /32 is used by default. |
| Destination address | ip4.daddr |
not | $IP/$MASK |
/$MASK is optional, /32 is used by default. |
| Destination address | ip4.daddr |
in | {$IP[,...]} |
Only support /32 mask. |
| Protocol | ip4.proto |
eq | $PROTOCOL |
Only icmp is supported for now, more protocols will be added. |
IPv6 matchers
| Matches | Type | Operator | Payload | Notes |
|---|---|---|---|---|
| Source address | ip6.saddr |
eq | $IP/$PREFIX |
/$PREFIX is optional, /128 is used by default. |
| Source address | ip6.saddr |
not | $IP/$PREFIX |
/$PREFIX is optional, /128 is used by default. |
| Destination address | ip6.daddr |
eq | $IP/$PREFIX |
/$PREFIX is optional, /128 is used by default. |
| Destination address | ip6.daddr |
not | $IP/$PREFIX |
/$PREFIX is optional, /128 is used by default. |
TCP matchers
| Matches | Type | Operator | Payload | Notes |
|---|---|---|---|---|
| Source port | tcp.sport |
eq | $PORT |
$PORT is a valid port value, as a decimal integer. |
| Source port | tcp.sport |
not | $PORT |
$PORT is a valid port value, as a decimal integer. |
| Source port | tcp.sport |
range | $START-$END |
$START and $END are valid port values, as decimal integers. |
| Destination port | tcp.dport |
eq | $PORT |
$PORT is a valid port value, as a decimal integer. |
| Destination port | tcp.dport |
not | $PORT |
$PORT is a valid port value, as a decimal integer. |
| Destination port | tcp.dport |
range | $START-$END |
$START and $END are valid port values, as decimal integers. |
| Flags | tcp.flags |
eq | $FLAGS |
$FLAGS is a comma-separated list of capitalized TCP flags (FIN, RST, ACK, ECE, SYN, PSH, URG, CWR). |
| Flags | tcp.flags |
not | $FLAGS |
$FLAGS is a comma-separated list of capitalized TCP flags (FIN, RST, ACK, ECE, SYN, PSH, URG, CWR). |
| Flags | tcp.flags |
any | $FLAGS |
$FLAGS is a comma-separated list of capitalized TCP flags (FIN, RST, ACK, ECE, SYN, PSH, URG, CWR). |
| Flags | tcp.flags |
all | $FLAGS |
$FLAGS is a comma-separated list of capitalized TCP flags (FIN, RST, ACK, ECE, SYN, PSH, URG, CWR). |
UDP matchers
| Matches | Type | Operator | Payload | Notes |
|---|---|---|---|---|
| Source port | udp.sport |
eq | $PORT |
$PORT is a valid port value, as a decimal integer. |
| Source port | udp.sport |
not | $PORT |
$PORT is a valid port value, as a decimal integer. |
| Source port | udp.sport |
range | $START-$END |
$START and $END are valid port values, as decimal integers. |
| Destination port | udp.dport |
eq | $PORT |
$PORT is a valid port value, as a decimal integer. |
| Destination port | udp.dport |
not | $PORT |
$PORT is a valid port value, as a decimal integer. |
| Destination port | udp.dport |
range | $START-$END |
$START and $END are valid port values, as decimal integers. |
Examples
Let’s explore some examples and how to write bpfilter rules. First, start the daemon:
sudo build/output/sbin/bpfilter
info : no serialized context found on disk, a new context will be created
info : waiting for requests...
Note
Flag--transient marks the bpfilter ruleset as temporary, meaning it will be removed on daemon restart.
You can use either iptables or nftables as the following:
sudo build/tools/install/sbin/./iptables --bpf {Rule}
or
sudo build/tools/install/sbin/./nft --bpf {Rule}
As the previous example which blocks ICMP with bpfilter but using custom iptables as front-end:
sudo build/tools/install/sbin/./iptables --bpf -D INPUT -p icmp -j DROP
Let’s write rules with bfcli. Let’s start with create a simple rule by creating a chain on the TC ingress hook for interface index 2 with a default ACCEPT policy, and it adds a rule to drop any packets where the IPv4 protocol is ICMP:
sudo build/output/sbin/./bfcli ruleset set --str "chain BF_HOOK_TC_INGRESS{ifindex=2} policy ACCEPT rule ip4.proto eq icmp DROP"
You can use XDP instead on the previous rule. It’s all dependent on where in the kernel you want to apply your filter:
"chain BF_HOOK_XDP{ifindex=2} policy ACCEPT rule ip4.proto eq icmp DROP"
Flushing bpfilter is by using:
sudo build/output/sbin/./bfcli ruleset flush
Blocking egress traffic to 192.168.1.24 port 22 on TC egress hook
"chain BF_HOOK_TC_EGRESS{ifindex=2} policy ACCEPT rule ip4.daddr eq 192.168.1.24 tcp.dport eq 22 DROP"
Dropping packets that have both SYN and FIN flags set that’s not normally seen in legitimate traffic as it used by attackers as part of system discovery:
"chain BF_HOOK_TC_INGRESS{ifindex=2} policy ACCEPT rule tcp.flags all SYN,FIN DROP"