Seccomp
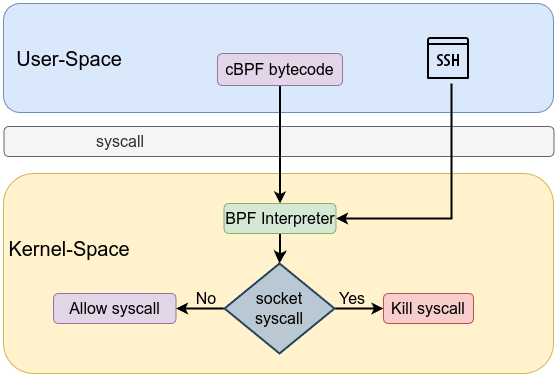
Seccomp, short for Secure Computing Mode, is a powerful kernel feature that limits the system calls a process can make, thereby reducing the exposed kernel surface and mitigating potential attacks. Seccomp is a security facility in the Linux kernel designed to be a tool for sandboxing processes by restricting the set of system calls they can use. to minimizes the kernel’s exposed interface, allowing developers to reduce the risk of kernel-level exploits. The filtering mechanism is implemented using Berkeley Packet Filter (cBPF) programs which inspect system call numbers and arguments before the system call is executed.
User-space security agents are vulnerable to TOCTOU attacks, tampering, and resource exhaustion because they depend on kernel communication to make security decisions. Seccomp addresses these issues by moving filtering into the kernel. Using a cBPF program, seccomp evaluates system call metadata atomically, eliminating the window for TOCTOU exploits and preventing tampering—since filters, once installed, become immutable and are inherited by child processes. This kernel-level enforcement ensures robust protection even if the user-space agent is compromised. Seccomp filtering is implemented as follows:
- The filter is defined as a cBPF program that evaluates each system call based on its number and its arguments. Since cBPF programs cannot dereference pointers, they operate only on the provided system call metadata, preventing time-of-check-time-of-use (TOCTOU) vulnerabilities.
- Once a process installs a seccomp filter using either the prctl() or seccomp() system call, every system call is intercepted and evaluated by the BPF program within the kernel. This means that even if the application logic is compromised, the kernel remains protected by the filter rules.
Note
cBPF’s limitations ensure that the filter logic only works with the system call metadata, making it less susceptible to common attacks that exploit pointer dereferencing.The prctl system call is used to control specific characteristics of the calling process and will be explained shortly. Using Seccomp in an application, developers typically follow these steps:
- The filter is defined using the
struct seccomp_datawhich is defined in the kernel source codeinclude/uapi/linux/seccomp.hwhich provides the metadata needed to evaluate each system call. This structure is defined as follows:
/**
* struct seccomp_data - the format the BPF program executes over.
* @nr: the system call number
* @arch: indicates system call convention as an AUDIT_ARCH_* value
* as defined in <linux/audit.h>.
* @instruction_pointer: at the time of the system call.
* @args: up to 6 system call arguments always stored as 64-bit values
* regardless of the architecture.
*/
struct seccomp_data {
int nr;
__u32 arch;
__u64 instruction_pointer;
__u64 args[6];
};
- Ensure that the process or its children cannot gain elevated privileges after the filter is installed using the following:
prctl(PR_SET_NO_NEW_PRIVS, 1);
- Use the
prctlwithPR_SET_SECCOMPto Install or activate seccomp filtering with a BPF program:
prctl(PR_SET_SECCOMP, SECCOMP_MODE_FILTER, &prog);
Here, prog is a pointer to a struct sock_fprog (defined in include/uapi/linux/filter.h) containing the BPF filter.
Seccomp Return Values
When a system call is intercepted, the BPF program returns one of several possible values. Each return value directs the kernel on how to handle the intercepted call. The actions are prioritized, meaning that if multiple filters are in place, the one with the highest precedence takes effect. The primary return values are:
SECCOMP_RET_KILL_PROCESS: Immediately terminates the entire process. The exit status indicates a SIGSYS signal.SECCOMP_RET_KILL_THREAD: Terminates only the current thread, again with a SIGSYS signal.SECCOMP_RET_TRAP: Sends a SIGSYS signal to the process, allowing the kernel to pass metadata about the blocked call (like the system call number and address) to a signal handler.SECCOMP_RET_ERRNO: Prevents execution of the system call and returns a predefined errno to the calling process.SECCOMP_RET_USER_NOTIF: Routes the system call to a user space notification handler, allowing external processes (like container managers) to decide how to handle the call.SECCOMP_RET_TRACE: If a tracer is attached (viaptrace), the tracer is notified, giving it an opportunity to modify or skip the system call.SECCOMP_RET_LOG: Logs the system call, then allows its execution. This is useful for development and debugging.SECCOMP_RET_ALLOW: Simply allows the system call to execute.
Seccomp return values are defined in include/linux/seccomp.h Kernel source code as the following:
#define SECCOMP_RET_KILL_PROCESS 0x80000000U /* kill the process */
#define SECCOMP_RET_KILL_THREAD 0x00000000U /* kill the thread */
#define SECCOMP_RET_KILL SECCOMP_RET_KILL_THREAD
#define SECCOMP_RET_TRAP 0x00030000U /* disallow and force a SIGSYS */
#define SECCOMP_RET_ERRNO 0x00050000U /* returns an errno */
#define SECCOMP_RET_USER_NOTIF 0x7fc00000U /* notifies userspace */
#define SECCOMP_RET_TRACE 0x7ff00000U /* pass to a tracer or disallow */
#define SECCOMP_RET_LOG 0x7ffc0000U /* allow after logging */
#define SECCOMP_RET_ALLOW 0x7fff0000U /* allow */
BPF Macros
Seccomp filters consist of a set of BPF macros. We will explain the most used ones:
BPF_STMT(code, k): A macro used to define a basic cBPF instruction that does not involve conditional branching. Thecodeparameter specifies the operation, andkis an immediate constant value used by the instruction.BPF_JUMP(code, k, jt, jf): A macro to define a conditional jump instruction.
code: Specifies the jump operation along with condition flags.
k: The constant value to compare against.
jt (jump true): The number of instructions to skip if the condition is met.
jf (jump false): The number of instructions to skip if the condition is not met.BPF_LD: This flag indicates a load instruction, which reads data into the accumulator.BPF_W: Specifies that the data to load is a word (typically 32 bits).BPF_ABS: Instructs the load operation to use absolute addressing—that is, load data from a fixed offset within the data structure (in this case, theseccomp_datastructure).BPF_K: Denotes that the operand (k) is an immediate constant.BPF_JMP: Indicates that the instruction is a jump (conditional or unconditional) type.BPF_JEQ: A condition flag used with jump instructions that causes a jump if the accumulator equals the constantk.
Let’s explore a simplified C code example demonstrating how to set up a seccomp filter to block socket syscall to prevent a process from initiating new network connections.
Code Example
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <stddef.h>
#include <sys/prctl.h>
#include <linux/seccomp.h>
#include <linux/filter.h>
#include <errno.h>
#define SYSCALL_SOCKET 41 // syscall number for socket
struct sock_filter filter[] = {
BPF_STMT(BPF_LD | BPF_W | BPF_ABS, offsetof(struct seccomp_data, nr)),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYSCALL_SOCKET, 0, 1),
BPF_STMT(BPF_RET | BPF_K, SECCOMP_RET_ERRNO | (EPERM & SECCOMP_RET_DATA)),
BPF_STMT(BPF_RET | BPF_K, SECCOMP_RET_ALLOW),
};
struct sock_fprog prog = {
.len = (unsigned short)(sizeof(filter) / sizeof(filter[0])),
.filter = filter,
};
int main(int argc, char *argv[]) {
if (argc < 2) {
fprintf(stderr, "Usage: %s <binary> [args...]\n", argv[0]);
exit(EXIT_FAILURE);
}
if (prctl(PR_SET_NO_NEW_PRIVS, 1, 0, 0, 0)) {
perror("prctl(PR_SET_NO_NEW_PRIVS) failed");
exit(EXIT_FAILURE);
}
if (prctl(PR_SET_SECCOMP, SECCOMP_MODE_FILTER, &prog)) {
perror("prctl(PR_SET_SECCOMP) failed");
exit(EXIT_FAILURE);
}
printf("Seccomp filter installed. Attempting socket on %s...\n", argv[1]);
execve(argv[1], &argv[1], NULL);
perror("socket");
return EXIT_FAILURE;
}
Seccomp filter is written using cBPF macros and defines a simple seccomp policy to block the socket system call. First, loads the system call number (from the nr field of the seccomp_data structure) into the accumulator
BPF_STMT(BPF_LD | BPF_W | BPF_ABS, offsetof(struct seccomp_data, nr)),
BPF_LD: Instructs the program to load data.BPF_W: Specifies that a 32-bit word should be loaded.BPF_ABS: Indicates that the data is located at an absolute offset from the beginning of theseccomp_datastructure.offsetof(struct seccomp_data, nr): Computes the offset of thenrfield (which holds the system call number) within theseccomp_datastructure.
Second, compare the syscall Number with socket. If the syscall is socket, the next instruction (which blocks the syscall) is executed. Otherwise, the filter skips over the block action and moves on.
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYSCALL_SOCKET, 0, 1),
BPF_JMP: Specifies that this is a jump instruction.BPF_JEQ: Adds the condition “jump if equal” to the operation.BPF_K: Indicates that the comparison value is an immediate constant.SYSCALL_SOCKET: The constant to compare against (i.e., the syscall number forsocket).0: If the condition is true (the syscall number equalsSYSCALL_SOCKET), do not skip any instructions (i.e., continue with the next instruction).1: If the condition is false (the syscall number does not equalSYSCALL_SOCKET), skip one instruction.
Third, Block the socket() syscall and return error code (e.g., EPERM).
BPF_STMT(BPF_RET | BPF_K, SECCOMP_RET_ERRNO | (EPERM & SECCOMP_RET_DATA)),
BPF_RET: Instructs the program to return a value immediately, effectively terminating the BPF program’s evaluation for this syscall.BPF_K: Indicates that the return value is given as an immediate constant.Return Value:SECCOMP_RET_ERRNO | (EPERM & SECCOMP_RET_DATA)
This tells the kernel to block the syscall by returning an error. Specifically, it sets the syscall’s return value to an error code (EPERM), meaning “Operation not permitted.”
Fourth, If the syscall was not socket, this instruction permits it.
BPF_STMT(BPF_RET | BPF_K, SECCOMP_RET_ALLOW),
BPF_RET | BPF_K: Again, a return instruction with a constant.Return Value:SECCOMP_RET_ALLOW. This instructs the kernel to allow the syscall to proceed.
Then, ensure that the process or its children cannot gain elevated privileges after the filter is installed
prctl(PR_SET_NO_NEW_PRIVS, 1, 0, 0, 0)
PR_SET_NO_NEW_PRIVS:This option tells the kernel to set a flag that prevents the process or its children from gaining new privileges. Finally, installing the seccomp filter.
prctl(PR_SET_SECCOMP, SECCOMP_MODE_FILTER, &prog)
Compile the code using clang -g -O2 seccomp_socket.c -o seccomp_socket, then chmod +x seccomp_socket. Next, run the code against ssh similar to the following: ./seccomp_socket /usr/bin/ssh [email protected]
Seccomp filter installed. Attempting socket on /usr/bin/ssh...
socket: Operation not permitted
ssh: connect to host 192.168.1.3 port 22: failure
We can see what is happening under the hood using strace ./seccomp_socket /usr/bin/ssh [email protected]
[...]
newfstatat(AT_FDCWD, "/etc/nsswitch.conf", {st_mode=S_IFREG|0644, st_size=569, ...}, 0) = 0
openat(AT_FDCWD, "/etc/passwd", O_RDONLY|O_CLOEXEC) = 3
fstat(3, {st_mode=S_IFREG|0644, st_size=2232, ...}) = 0
lseek(3, 0, SEEK_SET) = 0
read(3, "root:x:0:0:root:/root:/bin/bash\n"..., 4096) = 2232
close(3) = 0
socket(AF_INET, SOCK_STREAM, IPPROTO_TCP) = -1 EPERM (Operation not permitted)
getpid() = 2169
write(2, "socket: Operation not permitted\r"..., 33socket: Operation not permitted
) = 33
getpid() = 2169
write(2, "ssh: connect to host 192.168.1.3"..., 51ssh: connect to host 192.168.1.3 port 22: failure
[...]
Executing socket syscall is being blocked and a return value is showing -1 EPERM (Operation not permitted), which confirms that the filter is working as intended.
Note
The header file/include/linux/syscalls.h in the Linux kernel source code contains the prototypes for all system calls, providing the necessary declarations for the syscall interfaces. Additionally, for the x86_64 architecture, the file arch/x86/entry/syscalls/syscall_64.tbl lists all the system calls along with their corresponding syscall IDs, which are used to generate the syscall dispatch table during the kernel build process.
In the previous example we took blacklist approach by denying socket syscall for example. If we want to take the whitelist approach for a specific binary all we have to do is to record all its syscalls using something like strace. Let’s explore the whitelist approach, the following code has a menu with list of options such as running command ls which uses execve syscall , or opening /etc/passwd which uses open syscall and write syscall.
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/syscall.h>
#include <fcntl.h>
#include <string.h>
#include <errno.h>
int main(void) {
int choice;
while (1) {
printf("\nSyscall Menu:\n");
printf("1. Execve /usr/bin/ls\n");
printf("2. Open /etc/passwd\n");
printf("3. Write a message to stdout\n");
printf("4. Exit\n");
printf("Enter your choice: ");
if (scanf("%d", &choice) != 1) {
fprintf(stderr, "Invalid input.\n");
int c;
while ((c = getchar()) != '\n' && c != EOF);
continue;
}
getchar();
switch (choice) {
case 1: {
char *argv[] = { "ls", NULL };
char *envp[] = { NULL };
printf("Executing /usr/bin/ls via execve syscall...\n");
if (syscall(SYS_execve, "/usr/bin/ls", argv, envp) == -1) {
perror("execve syscall failed");
}
break;
}
case 2: {
printf("Opening /etc/passwd via open syscall...\n");
int fd = syscall(SYS_open, "/etc/passwd", O_RDONLY);
if (fd == -1) {
perror("open syscall failed");
} else {
printf("File /etc/passwd opened successfully (fd = %d).\n", fd);
if (syscall(SYS_close, fd) == -1) {
perror("close syscall failed");
}
}
exit(0);
}
case 3: {
const char *msg = "Hello from syscall write!\n";
printf("Writing message to stdout via write syscall...\n");
if (syscall(SYS_write, STDOUT_FILENO, msg, strlen(msg)) == -1) {
perror("write syscall failed");
}
exit(0);
}
case 4: {
printf("Exiting via exit_group syscall...\n");
syscall(SYS_exit_group, 0);
exit(0);
}
default:
printf("Invalid choice. Please select a number between 1 and 5.\n");
}
}
return 0;
}
Let’s compile it using gcc -O2 -Wall syscalls.c -o syscalls. Recording syscall can be done using strace. For example, we want to record write option in our code.
strace -c -f ./syscalls , then choose option 3:
Syscall Menu:
1. Execve /usr/bin/ls
2. Open /etc/passwd
3. Write a message to stdout
4. Exit
Enter your choice: 3
Writing message to stdout via write syscall...
Hello from syscall write!
The strace would look like this:
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
0.00 0.000000 0 2 read
0.00 0.000000 0 9 write
0.00 0.000000 0 2 close
0.00 0.000000 0 4 fstat
0.00 0.000000 0 8 mmap
0.00 0.000000 0 3 mprotect
0.00 0.000000 0 1 munmap
0.00 0.000000 0 3 brk
0.00 0.000000 0 2 pread64
0.00 0.000000 0 1 1 access
0.00 0.000000 0 1 execve
0.00 0.000000 0 1 arch_prctl
0.00 0.000000 0 1 set_tid_address
0.00 0.000000 0 2 openat
0.00 0.000000 0 1 set_robust_list
0.00 0.000000 0 1 prlimit64
0.00 0.000000 0 1 getrandom
0.00 0.000000 0 1 rseq
------ ----------- ----------- --------- --------- ----------------
100.00 0.000000 0 44 1 total
These are all of used syscalls to run the binary to this option:
case 3: {
const char *msg = "Hello from syscall write!\n";
printf("Writing message to stdout via write syscall...\n");
if (syscall(SYS_write, STDOUT_FILENO, msg, strlen(msg)) == -1) {
perror("write syscall failed");
}
Let’s build seccomp program to allow only these syscalls
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <stddef.h>
#include <sys/prctl.h>
#include <linux/seccomp.h>
#include <linux/filter.h>
#include <errno.h>
#include <sys/syscall.h>
#define SYS_READ 0
#define SYS_WRITE 1
#define SYS_CLOSE 3
#define SYS_FSTAT 5
#define SYS_MMAP 9
#define SYS_MPROTECT 10
#define SYS_MUNMAP 11
#define SYS_BRK 12
#define SYS_PREAD64 17
#define SYS_ACCESS 21
#define SYS_EXECVE 59
#define SYS_ARCH_PRCTL 158
#define SYS_SET_TID_ADDRESS 218
#define SYS_OPENAT 257
#define SYS_SET_ROBUST_LIST 273
#define SYS_PRLIMIT64 302
#define SYS_GETRANDOM 318
#define SYS_RSEQ 334
struct sock_filter filter[] = {
BPF_STMT(BPF_LD | BPF_W | BPF_ABS, offsetof(struct seccomp_data, nr)),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_READ, 18, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_WRITE, 17, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_CLOSE, 16, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_FSTAT, 15, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_MMAP, 14, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_MPROTECT, 13, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_MUNMAP, 12, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_BRK, 11, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_PREAD64, 10, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_ACCESS, 9, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_EXECVE, 8, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_ARCH_PRCTL, 7, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_SET_TID_ADDRESS, 6, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_OPENAT, 5, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_SET_ROBUST_LIST, 4, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_PRLIMIT64, 3, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_GETRANDOM, 2, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_RSEQ, 1, 0),
BPF_STMT(BPF_RET | BPF_K, SECCOMP_RET_ERRNO | (EPERM & SECCOMP_RET_DATA)),
BPF_STMT(BPF_RET | BPF_K, SECCOMP_RET_ALLOW),
};
struct sock_fprog prog = {
.len = (unsigned short)(sizeof(filter) / sizeof(filter[0])),
.filter = filter,
};
int main(int argc, char *argv[]) {
if (argc < 2) {
fprintf(stderr, "Usage: %s <binary> [args...]\n", argv[0]);
exit(EXIT_FAILURE);
}
if (prctl(PR_SET_NO_NEW_PRIVS, 1, 0, 0, 0)) {
perror("prctl(PR_SET_NO_NEW_PRIVS) failed");
exit(EXIT_FAILURE);
}
if (prctl(PR_SET_SECCOMP, SECCOMP_MODE_FILTER, &prog)) {
perror("prctl(PR_SET_SECCOMP) failed");
exit(EXIT_FAILURE);
}
printf("Seccomp whitelist filter installed. Executing %s...\n", argv[1]);
execve(argv[1], &argv[1], NULL);
perror("execve failed");
return EXIT_FAILURE;
}
Compile it gcc -O2 -Wall seccomp.c -o seccomp, then chmod +x seccomp and finally ./seccomp ./syscalls and choose 3
Syscall Menu:
1. Execve /usr/bin/ls
2. Open /etc/passwd
3. Write a message to stdout
4. Exit
Enter your choice: 3
Writing message to stdout via write syscall...
Hello from syscall write!
Segmentation fault (core dumped)
If you choose something else like 2
Syscall Menu:
1. Execve /usr/bin/ls
2. Open /etc/passwd
3. Write a message to stdout
4. Exit
Enter your choice: 2
Opening /etc/passwd via open syscall...
open syscall failed: Operation not permitted
Segmentation fault (core dumped)
Notice that we have Segmentation fault (core dumped) . Simply because we have a blocked a syscall exit_group , run strace ./seccomp ./syscalls then choose 3:
[...]
fstat(0, {st_mode=S_IFCHR|0620, st_rdev=makedev(0x88, 0x2), ...}) = 0
write(1, "Enter your choice: ", 19Enter your choice: ) = 19
read(0, 3
"3\n", 1024) = 2
write(1, "Writing message to stdout via wr"..., 47Writing message to stdout via write syscall...
) = 47
write(1, "Hello from syscall write!\n", 26Hello from syscall write!
) = 26
exit_group(0) = -1 EPERM (Operation not permitted)
--- SIGSEGV {si_signo=SIGSEGV, si_code=SI_KERNEL, si_addr=NULL} ---
+++ killed by SIGSEGV (core dumped) +++
Segmentation fault (core dumped)
We need to whitelist exit_group too in our code. Strace couldn’t record exit_group syscall first because syscall such as exit_group syscall terminates the process immediately, so there’s no return value for strace to capture. Fixing our code is just by adding exit_group to the whitelist:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <stddef.h>
#include <sys/prctl.h>
#include <linux/seccomp.h>
#include <linux/filter.h>
#include <errno.h>
#include <sys/syscall.h>
#define SYS_READ 0
#define SYS_WRITE 1
#define SYS_CLOSE 3
#define SYS_FSTAT 5
#define SYS_MMAP 9
#define SYS_MPROTECT 10
#define SYS_MUNMAP 11
#define SYS_BRK 12
#define SYS_PREAD64 17
#define SYS_ACCESS 21
#define SYS_EXECVE 59
#define SYS_ARCH_PRCTL 158
#define SYS_SET_TID_ADDRESS 218
#define SYS_OPENAT 257
#define SYS_SET_ROBUST_LIST 273
#define SYS_PRLIMIT64 302
#define SYS_GETRANDOM 318
#define SYS_RSEQ 334
#define SYS_EXIT_GROUP 231
struct sock_filter filter[] = {
BPF_STMT(BPF_LD | BPF_W | BPF_ABS, offsetof(struct seccomp_data, nr)),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_EXIT_GROUP, 19, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_READ, 18, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_WRITE, 17, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_CLOSE, 16, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_FSTAT, 15, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_MMAP, 14, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_MPROTECT, 13, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_MUNMAP, 12, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_BRK, 11, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_PREAD64, 10, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_ACCESS, 9, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_EXECVE, 8, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_ARCH_PRCTL, 7, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_SET_TID_ADDRESS, 6, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_OPENAT, 5, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_SET_ROBUST_LIST, 4, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_PRLIMIT64, 3, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_GETRANDOM, 2, 0),
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_RSEQ, 1, 0),
BPF_STMT(BPF_RET | BPF_K, SECCOMP_RET_ERRNO | (EPERM & SECCOMP_RET_DATA)),
BPF_STMT(BPF_RET | BPF_K, SECCOMP_RET_ALLOW),
};
struct sock_fprog prog = {
.len = (unsigned short)(sizeof(filter) / sizeof(filter[0])),
.filter = filter,
};
int main(int argc, char *argv[]) {
if (argc < 2) {
fprintf(stderr, "Usage: %s <binary> [args...]\n", argv[0]);
exit(EXIT_FAILURE);
}
if (prctl(PR_SET_NO_NEW_PRIVS, 1, 0, 0, 0)) {
perror("prctl(PR_SET_NO_NEW_PRIVS) failed");
exit(EXIT_FAILURE);
}
if (prctl(PR_SET_SECCOMP, SECCOMP_MODE_FILTER, &prog)) {
perror("prctl(PR_SET_SECCOMP) failed");
exit(EXIT_FAILURE);
}
printf("Seccomp whitelist filter installed. Executing %s...\n", argv[1]);
execve(argv[1], &argv[1], NULL);
perror("execve failed");
return EXIT_FAILURE;
}
In the following part, we will explain the LSM kernel framework, a well-defined interface to enforce Mandatory Access Control (MAC) policies in a modular way.