This is the multi-page printable view of this section. Click here to print.
Networking with eBPF
- 1: Socket Filter
- 2: Lightweight Tunnels
- 3: Traffic Control
- 4: XDP
- 5: CGroup Socket Address
1 - Socket Filter
We saw socket filter program type definition in previous chapter, a SOCKET_FILTER type program executes whenever a packet arrives at the socket it is attached to give you access to examine all packets passed through the socket and can’t give you control to modify packets and believe me, it’s easier than you think, all you have to do is to look at the the entire packet structure as we will see. Socket filter eBPF programs are classified under the program type BPF_PROG_TYPE_SOCKET_FILTER.
The socket buffer (or sk_buff) is the primary structure used within the Linux kernel to represent network packets. It stores not only the packet data itself but also various metadata such as header pointers, packet lengths, protocol information, and state flags. sk_buff is defined in include/linux/skbuff.h and it has four major pointers:
- head: A pointer to the beginning of the allocated memory buffer for the packet.
- data: A pointer to the beginning of the valid packet data within the buffer.
- tail: A pointer that marks the end of the valid data currently stored in the buffer.
- end: A pointer to the end of the allocated memory region.
These four pointers provide the framework for managing the packet data within a single contiguous memory allocation. The sk_buff’s allocated memory region divided into several logical segments that these pointers describe:
- Headroom: Space before the packet data for prepending headers.
- Data: The actual packet contents (headers and payload).
- Tailroom: Space after the packet data for appending headers or trailers.
- skb_shared_info: Metadata structure for reference counting, fragments, and other shared data.

__sk_buff data structure is a simplified version of sk_buff structure that’s exposed to eBPF programs. It provides a subset of information about a network packet that eBPF programs can use to inspect, filter, or even modify packets without needing access to all the internals of the full sk_buff.
__sk_buff used as context for eBPF programs such as in socket filter programs. __sk_buff is defined in include/uapi/linux/bpf.h as:
struct __sk_buff {
__u32 len;
__u32 pkt_type;
__u32 mark;
__u32 queue_mapping;
__u32 protocol;
__u32 vlan_present;
__u32 vlan_tci;
__u32 vlan_proto;
__u32 priority;
__u32 ingress_ifindex;
__u32 ifindex;
__u32 tc_index;
__u32 cb[5];
__u32 hash;
__u32 tc_classid;
__u32 data;
__u32 data_end;
__u32 napi_id;
__u32 family;
__u32 remote_ip4;
__u32 local_ip4;
__u32 remote_ip6[4];
__u32 local_ip6[4];
__u32 remote_port;
__u32 local_port;
__u32 data_meta;
__bpf_md_ptr(struct bpf_flow_keys *, flow_keys);
__u64 tstamp;
__u32 wire_len;
__u32 gso_segs;
__bpf_md_ptr(struct bpf_sock *, sk);
__u32 gso_size;
__u8 tstamp_type;
__u32 :24;
__u64 hwtstamp;
};
Therefore, to detect an ICMP echo request packet (as in the following example), you need to perform the following checks: first, verify that it’s an IPv4 packet. If it is, then confirm that the protocol is ICMP. Finally, check if the ICMP type is an echo request or an echo reply all of that is just by reading __sk_buff using bpf_skb_load_bytes . bpf_skb_load_bytes is a helper function which can be used to load data from a packet and it has the following prototype:
`static long (* const bpf_skb_load_bytes)(const void *skb, __u32 offset, void *to, __u32 len) = (void *) 26;`
bpf_skb_load_bytes takes a pointer to sk_buff , offset which means which part of the packet you want to load or extract, a pointer to a location where you want to store the loaded or extracted data and finally, the length you want to extract.
#include "vmlinux.h"
#include <bpf/bpf_endian.h>
#include <bpf/bpf_helpers.h>
#define ETH_TYPE 12 // EtherType
#define ETH_HLEN 14 // ETH header length
#define ICMP_LEN 34 // ICMP header start point
#define ETH_P_IP 0x0800 // Internet Protocol packet
#define IPPROTO_ICMP 1 // Echo request
char _license[] SEC("license") = "GPL";
SEC("socket")
int icmp_filter_prog(struct __sk_buff *skb)
{
__u16 eth_proto = 0;
if (bpf_skb_load_bytes(skb, ETH_TYPE, ð_proto, sizeof(eth_proto)) < 0)
return 0;
eth_proto = bpf_ntohs(eth_proto);
if (eth_proto != ETH_P_IP) {
return 0;
}
__u8 ip_version = 0;
if (bpf_skb_load_bytes(skb, ETH_HLEN, &ip_version, sizeof(ip_version)) < 0)
return 0;
ip_version = ip_version >> 4;
if (ip_version != 4) {
return 0;
}
__u8 ip_proto = 0;
if (bpf_skb_load_bytes(skb, ETH_HLEN + 9, &ip_proto, sizeof(ip_proto)) < 0)
return 0;
if (ip_proto != IPPROTO_ICMP) {
return 0;
}
__u8 icmp_type = 0;
if (bpf_skb_load_bytes(skb, ICMP_LEN, &icmp_type, sizeof(icmp_type)) < 0)
return 0;
if (icmp_type != 8) {
return 0;
}
return skb->len;
}
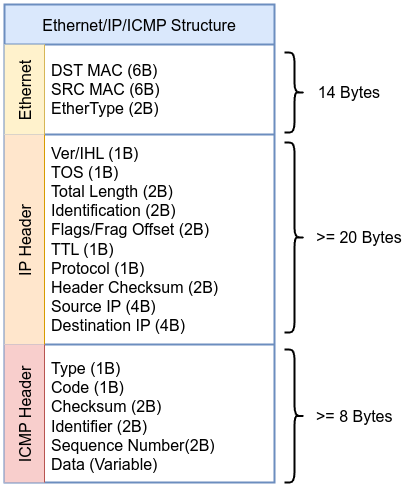
We need to keep the following diagram in front of us to understand this code:
#define ETH_TYPE 12 // EtherType
#define ETH_HLEN 14 // ETH header length
#define ICMP_LEN 34 // ICMP header start point
#define ETH_P_IP 0x0800 // Internet Protocol packet
#define IPPROTO_ICMP 1 // Echo request
char _license[] SEC("license") = "GPL";
SEC("socket")
int icmp_filter_prog(struct __sk_buff *skb)
{
int offset = 0;
__u16 eth_proto = 0;
if (bpf_skb_load_bytes(skb, ETH_TYPE, ð_proto, sizeof(eth_proto)) < 0)
return 0;
eth_proto = bpf_ntohs(eth_proto);
if (eth_proto != ETH_P_IP) {
return 0;
}
First, we defined Ethernet type , Ethernet header length which is the start point of IP header, ICMP header length (Ethernet header length + IP header length). The program is defined as socket as you can see in SEC, then __sk_buff as context.
The first thing to is extract Ethernet type to determine of the packet is IP packet or not, all we need to do is get the following place in Ethernet header

bpf_skb_load_bytes helper function will do that bpf_skb_load_bytes(skb, ETH_TYPE, ð_proto, sizeof(eth_proto)), it will extract EtherType for us and save the output in eth_proto. We define eth_proto as __u16 which is unsigned 16-bit integer and that’s why bpf_skb_load_bytes will extract in that case 2 bytes because we specified the length we need as sizeof(eth_proto).
Then we used bpf_ntohs macro which used to convert multi-byte values like EtherType, IP addresses, and port numbers from network byte order (big-endian) to host byte order, then we we perform out check if the packet is IP packet by comparing the retrieved value with 0x0800 which represent IP EtherType, as defined in the /include/uapi/linux/if_ether.h kernel source code. If the value does not match, the code will drop the packet from the socket.
The same concept goes with IP version part:
__u8 ip_version = 0;
if (bpf_skb_load_bytes(skb, ETH_HLEN, &ip_version, sizeof(ip_version)) < 0)
return 0;
ip_version = ip_version >> 4;
if (ip_version != 4) {
return 0;
}
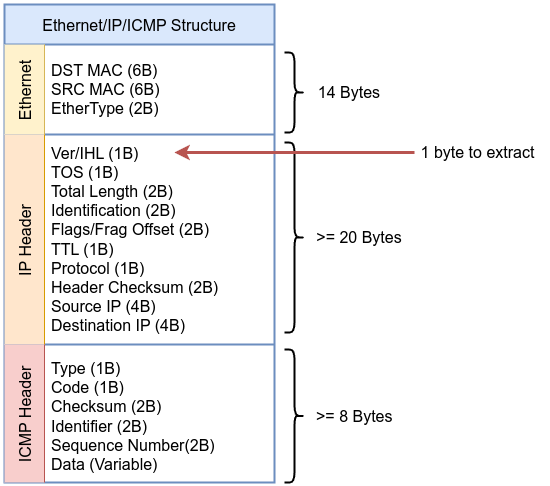
We need to extract the first 1 byte (__u8) of the IP header. The top nibble (the first 4 bits) is the version of IP ip_version = ip_version >> 4 followed by checking if the version is 4 or drop the packet from the socket. Then we need to move to Protocol field in IP header to check if the packet is ICMP by comparing the retrieved value with 1 which represents ICMP as defined in /include/uapi/linux/in.h kernel source code. If the value does not match, the code will drop the packet from the socket.
Note
We assumed that IP header has fixed size 20 byes just for the sake of simplifying, but in reality you should check IP header size from Ver/IHL first.
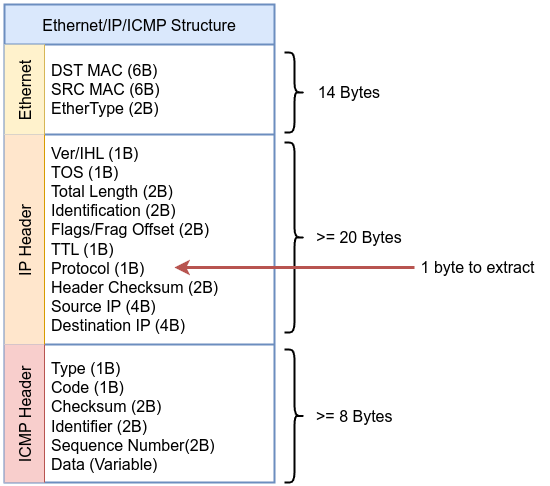
Then the last part is moving to the first byte of ICMP header and check if the packet is echo request or drop the packet from the socket. Finally, return skb->len indicated that the packet should be accepted and passed along to user space or to further processing. Let’s move to the user-space code.
#include <arpa/inet.h>
#include <errno.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/socket.h>
#include <net/ethernet.h>
#include <bpf/libbpf.h>
#include <bpf/bpf.h>
#include "icmp_socket_filter.skel.h"
int main(void)
{
struct icmp_socket_filter *skel = NULL;
int sock_fd = -1, prog_fd = -1, err;
skel = icmp_socket_filter__open();
if (!skel) {
fprintf(stderr, "Failed to open skeleton\n");
return 1;
}
err = icmp_socket_filter__load(skel);
if (err) {
fprintf(stderr, "Failed to load skeleton: %d\n", err);
goto cleanup;
}
prog_fd = bpf_program__fd(skel->progs.icmp_filter_prog);
if (prog_fd < 0) {
fprintf(stderr, "Failed to get program FD\n");
goto cleanup;
}
sock_fd = socket(AF_PACKET, SOCK_RAW, htons(ETH_P_ALL));
if (sock_fd < 0) {
fprintf(stderr, "Error creating raw socket: %d\n", errno);
goto cleanup;
}
err = setsockopt(sock_fd, SOL_SOCKET, SO_ATTACH_BPF, &prog_fd, sizeof(prog_fd));
if (err) {
fprintf(stderr, "setsockopt(SO_ATTACH_BPF) failed: %d\n", errno);
goto cleanup;
}
printf("Only ICMP Echo Requests (ping) will be seen by this raw socket.\n");
while (1) {
unsigned char buf[2048];
ssize_t n = read(sock_fd, buf, sizeof(buf));
if (n < 0) {
perror("read");
break;
}
printf("Received %zd bytes (ICMP echo request) on this socket\n", n);
}
cleanup:
if (sock_fd >= 0)
close(sock_fd);
icmp_socket_filter__destroy(skel);
return 0;
}
We made a few modifications to the user-space file , instead of attaching the eBPF program directly, we first,retrieve the file descriptor of the loaded eBPF program as shown below:
prog_fd = bpf_program__fd(skel->progs.icmp_filter_prog);
if (prog_fd < 0) {
fprintf(stderr, "Failed to get program FD\n");
goto cleanup;
}
The next step is creating a socket as shown in the following:
sock_fd = socket(AF_PACKET, SOCK_RAW, htons(ETH_P_ALL));
if (sock_fd < 0) {
fprintf(stderr, "Error creating raw socket: %d\n", errno);
goto cleanup;
}
Finally, attach the file descriptor of the loaded eBPF program to the created socket as in the following:
err = setsockopt(sock_fd, SOL_SOCKET, SO_ATTACH_BPF, &prog_fd, sizeof(prog_fd));
if (err) {
fprintf(stderr, "setsockopt(SO_ATTACH_BPF) failed: %d\n", errno);
goto cleanup;
}
Compile the eBPF program, then generate skeleton file. After that, compile the loader. Start the program and ping from the same machine or from an external machine. You should see output similar to the following:
Only ICMP Echo Requests (ping) will be seen by this raw socket.
Received 98 bytes (ICMP echo request) on this socket
Received 98 bytes (ICMP echo request) on this socket
Received 98 bytes (ICMP echo request) on this socket
Received 98 bytes (ICMP echo request) on this socket
Received 98 bytes (ICMP echo request) on this socket
Let’s demonstrate another simple example and yet has important benefits which is extracting a keyword from HTTP request by storing only 64 bytes from the request’s TCP payload in a buffer and searching that buffer. The buffer size significantly reduced so we don’t need to address IP fragmentation. By performing some checks as we did in the previous example until we get to the TCP payload and search in it by a magic word.
#include "vmlinux.h"
#include <bpf/bpf_endian.h>
#include <bpf/bpf_helpers.h>
#define ETH_TYPE 12
#define ETH_HLEN 14
#define ETH_P_IP 0x0800 // IPv4 EtherType
#define IPPROTO_TCP 6
#define TCP_LEN 34 // TCP header start point
#define HTTP_PORT 8080
#define HTTP_PAYLOAD_READ_LEN 64
static __always_inline int search_substring(const char *tcp_buff, int tcp_buff_len,
const char *magic_word, int magic_word_len)
{
if (magic_word_len == 0 || tcp_buff_len == 0 || magic_word_len > tcp_buff_len)
return 0;
for (int i = 0; i <= tcp_buff_len - magic_word_len; i++) {
int j;
for (j = 0; j < magic_word_len; j++) {
if (tcp_buff[i + j] != magic_word[j])
break;
}
if (j == magic_word_len) {
return 1;
}
}
return 0;
}
char _license[] SEC("license") = "GPL";
SEC("socket")
int http_filter_prog(struct __sk_buff *skb)
{
const char magic_word[] = "l33t";
int offset = 0;
__u16 eth_proto = 0;
if (bpf_skb_load_bytes(skb, ETH_TYPE, ð_proto, sizeof(eth_proto)) < 0)
return 0;
eth_proto = bpf_ntohs(eth_proto);
if (eth_proto != ETH_P_IP) {
return 0;
}
__u8 ip_version = 0;
if (bpf_skb_load_bytes(skb, ETH_HLEN, &ip_version, sizeof(ip_version)) < 0)
return 0;
ip_version = ip_version >> 4;
if (ip_version != 4) {
return 0;
}
__u8 ip_proto = 0;
if (bpf_skb_load_bytes(skb, ETH_HLEN + 9, &ip_proto, sizeof(ip_proto)) < 0)
return 0;
if (ip_proto != IPPROTO_TCP) {
return 0;
}
__u8 tcp_hdr_len = 0;
if (bpf_skb_load_bytes(skb, TCP_LEN + 12, &tcp_hdr_len, 1) < 0)
return 0;
tcp_hdr_len >>= 4;
tcp_hdr_len *= 4;
__u16 dport = 0;
if (bpf_skb_load_bytes(skb, TCP_LEN + 2, &dport, sizeof(dport)) < 0)
return 0;
dport = bpf_ntohs(dport);
if (dport != HTTP_PORT) {
return 0;
}
offset += tcp_hdr_len;
char http_buf[HTTP_PAYLOAD_READ_LEN] = {0};
if (bpf_skb_load_bytes(skb, TCP_LEN + tcp_hdr_len, &http_buf, sizeof(http_buf)) < 0)
return skb->len;
bpf_printk("packet \n%s",http_buf );
if (search_substring(http_buf, HTTP_PAYLOAD_READ_LEN, magic_word, sizeof(magic_word) - 1)) {
bpf_printk("ALERT: Magic Word Found in the HTTP request payload\n");
}
return skb->len;
}
Keep the following diagram in front of you to understand this code:
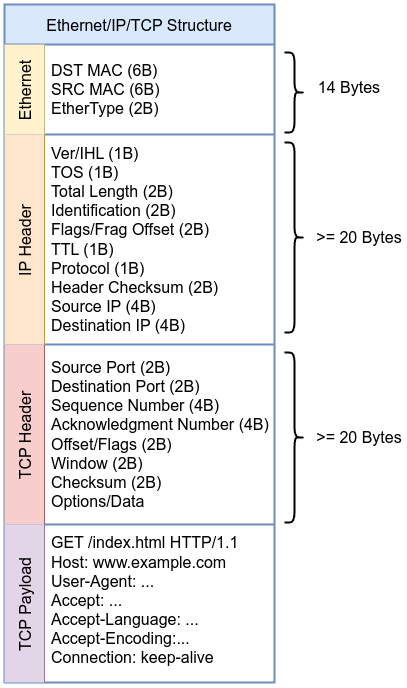
A simple search function is added to search for “l33t” in TCP payload, it can be sent via GET request such as /?id=l33t. The function, search_substring, perfroms a basic substring search algorithm. Due to its __always_inline attribute, this function offers performance benefits. The function takes the payload buffer, its length, the search term, and its length as input. It returns 1 if the search term is found within the payload, and 0 otherwise. This allows for simple pattern-based filtering of network traffic within our the eBPF program.
static __always_inline int search_substring(const char *tcp_buff, int tcp_buff_len,
const char *magic_word, int magic_word_len)
{
if (magic_word_len == 0 || tcp_buff_len == 0 || magic_word_len > tcp_buff_len)
return 0;
for (int i = 0; i <= tcp_buff_len - magic_word_len; i++) {
int j;
for (j = 0; j < magic_word_len; j++) {
if (tcp_buff[i + j] != magic_word[j])
break;
}
if (j == magic_word_len) {
return 1;
}
}
return 0;
}
Calculating TCP header size is important because we need to know where TCP payload data begins as the size of TCP header is not fixed as in the most cases of IP header due to TCP options.
__u8 tcp_hdr_len = 0;
if (bpf_skb_load_bytes(skb, TCP_LEN + 12, &tcp_hdr_len, 1) < 0)
return 0;
tcp_hdr_len >>= 4;
tcp_hdr_len *= 4;
Note
IP header has options too but in most cases the IP header size is 20 bytes, parsing IHL in IP header will give the exact size of IP header size.Let’s move to user-space code
#include <arpa/inet.h>
#include <errno.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/socket.h>
#include <net/ethernet.h>
#include <bpf/libbpf.h>
#include <bpf/bpf.h>
static const char *BPF_OBJ_FILE = "http_extract.o";
int main(void)
{
struct bpf_object *obj = NULL;
struct bpf_program *prog;
int sock_fd = -1, prog_fd = -1, err;
obj = bpf_object__open_file(BPF_OBJ_FILE, NULL);
if (!obj) {
fprintf(stderr, "Error opening BPF object file\n");
return 1;
}
err = bpf_object__load(obj);
if (err) {
fprintf(stderr, "Error loading BPF object: %d\n", err);
bpf_object__close(obj);
return 1;
}
prog = bpf_object__find_program_by_name(obj, "http_filter_prog");
if (!prog) {
fprintf(stderr, "Error finding BPF program by name.\n");
bpf_object__close(obj);
return 1;
}
prog_fd = bpf_program__fd(prog);
if (prog_fd < 0) {
fprintf(stderr, "Error getting program FD.\n");
bpf_object__close(obj);
return 1;
}
sock_fd = socket(AF_PACKET, SOCK_RAW, htons(ETH_P_ALL));
if (sock_fd < 0) {
fprintf(stderr, "Error creating raw socket: %d\n", errno);
bpf_object__close(obj);
return 1;
}
err = setsockopt(sock_fd, SOL_SOCKET, SO_ATTACH_BPF, &prog_fd, sizeof(prog_fd));
if (err) {
fprintf(stderr, "setsockopt(SO_ATTACH_BPF) failed: %d\n", errno);
close(sock_fd);
bpf_object__close(obj);
return 1;
}
printf("BPF socket filter attached. It will detect HTTP methods on port 80.\n");
while (1) {
unsigned char buf[2048];
ssize_t n = read(sock_fd, buf, sizeof(buf));
if (n < 0) {
perror("read");
break;
}
printf("Received %zd bytes on this socket\n", n);
}
close(sock_fd);
bpf_object__close(obj);
return 0;
}
The first 4 bits of Offset/Flags field in TCP header contains the size of the TCP header tcp_hdr_len >>= 4 then multiplies the value by 4 to convert the header length from 32-bit words to bytes. Compile and start the program then start HTTP server on your machine on port 8080 or change HTTP_PORT from the code, you can use python
python3 -m http.server 8080
Then curl from another box
curl http://192.168.1.2:8080/index.html?id=l33t
And you will get similar results because we entered the magic word which is l33t in our request.
GET /index.html?id=l33t HTTP/1.1
Host: 192.168.1.2:8080
sshd-session-1423 [000] ..s11 28817.447546: bpf_trace_printk: ALERT: Magic Word Found in the HTTP request payload
This program’s ability to inspect network traffic is crucial for intrusion detection and web application firewalls. Its functionality enables security tools to identify suspicious patterns or malicious content as it passes through the network, allowing for proactive threat detection with minimal performance overhead.
2 - Lightweight Tunnels
Lightweight Tunnels (LWT) in the Linux kernel provides a way to handle network tunneling defined in /net/core/lwtunnel.c. Rather than being standalone protocols like TCP or UDP, these encapsulation types are identifiers used to select a specific method of wrapping packets for tunneling. For example, MPLS encapsulation wraps packets with an MPLS label stack, while SEG6 encapsulation uses an IPv6 Segment Routing header. The code below shows how these encapsulation types are mapped to human‐readable form:
switch (encap_type) {
case LWTUNNEL_ENCAP_MPLS:
return "MPLS";
case LWTUNNEL_ENCAP_ILA:
return "ILA";
case LWTUNNEL_ENCAP_SEG6:
return "SEG6";
case LWTUNNEL_ENCAP_BPF:
return "BPF";
case LWTUNNEL_ENCAP_SEG6_LOCAL:
return "SEG6LOCAL";
case LWTUNNEL_ENCAP_RPL:
return "RPL";
case LWTUNNEL_ENCAP_IOAM6:
return "IOAM6";
case LWTUNNEL_ENCAP_XFRM:
return NULL;
case LWTUNNEL_ENCAP_IP6:
case LWTUNNEL_ENCAP_IP:
case LWTUNNEL_ENCAP_NONE:
case __LWTUNNEL_ENCAP_MAX:
WARN_ON(1);
break;
}
return NULL;
}
There are four types of programs in eBPF to handle Lightweight Tunnels. Among them, BPF_PROG_TYPE_LWT_IN and BPF_PROG_TYPE_LWT_OUT are the most important.
BPF_PROG_TYPE_LWT_IN can be attached to incoming path of Lightweight Tunnel and uses lwt_in as section definition while BPF_PROG_TYPE_LWT_OUT can be attached the outgoing path of Lightweight Tunnel and used lwt_out as section definition. Both applications can add more control to the route by allowing or dropping of traffic and also inspect the traffic on a specific route but they are not allowed to modify. Information on the full capabilities of these LWT eBPF program types is limited, making them hard to fully explore.
Note
Both LWT “in” and “out” programs run at a stage where the packet data has already been processed by the routing stack and the kernel has already stripped the Layer 2 (Ethernet) header. This means that the packet data passed to your eBPF program starts directly with the IP header.We can build a simple BPF_PROG_TYPE_LWT_OUT program for testing without the need to make Lightweight Tunnel. The idea of this program is to block outgoing 8080 connection from 10.0.0.2 to 10.0.0.3.
#include <linux/bpf.h>
#include <linux/ip.h>
#include <linux/tcp.h>
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_endian.h>
#include <linux/in.h>
char _license[] SEC("license") = "GPL";
SEC("lwt_out")
int drop_egress_port_8080(struct __sk_buff *skb) {
void *data = (void *)(long)skb->data;
void *data_end = (void *)(long)skb->data_end;
struct iphdr *iph = data;
if ((void *)iph + sizeof(*iph) > data_end)
return BPF_OK;
if (iph->protocol != IPPROTO_TCP)
return BPF_OK;
int ip_header_length = iph->ihl * 4;
struct tcphdr *tcph = data + ip_header_length;
if ((void *)tcph + sizeof(*tcph) > data_end)
return BPF_OK;
if (bpf_ntohs(tcph->dest) == 8080) {
bpf_printk("Dropping egress packet to port 8080\n");
return BPF_DROP;
}
return BPF_OK;
}
Here we utilize another technique to access packet fields without manually calculating offsets for each field. For example, we defined struct iphdr ip; from linux/ip.h header which allows us to directly access protocol fields within IP header. iphdr structure has the following definition:
struct iphdr {
#if defined(__LITTLE_ENDIAN_BITFIELD)
__u8 ihl:4,
version:4;
#elif defined (__BIG_ENDIAN_BITFIELD)
__u8 version:4,
ihl:4;
#else
#error "Please fix <asm/byteorder.h>"
#endif
__u8 tos;
__be16 tot_len;
__be16 id;
__be16 frag_off;
__u8 ttl;
__u8 protocol;
__sum16 check;
__struct_group(/* no tag */, addrs, /* no attrs */,
__be32 saddr;
__be32 daddr;
);
};
This enables us to check if the packet is TCP using if (ip.protocol != IPPROTO_TCP). If the packet is TCP, it passes the check with BPF_OK and proceeds to the next check.
tcphdrstructure has the following definition in linux/tcp.h:
struct tcphdr {
__be16 source;
__be16 dest;
__be32 seq;
__be32 ack_seq;
#if defined(__LITTLE_ENDIAN_BITFIELD)
__u16 res1:4,
doff:4,
fin:1,
syn:1,
rst:1,
psh:1,
ack:1,
urg:1,
ece:1,
cwr:1;
#elif defined(__BIG_ENDIAN_BITFIELD)
__u16 doff:4,
res1:4,
cwr:1,
ece:1,
urg:1,
ack:1,
psh:1,
rst:1,
syn:1,
fin:1;
#else
#error "Adjust your <asm/byteorder.h> defines"
#endif
__be16 window;
__sum16 check;
__be16 urg_ptr;
};
The final check is validating if the destination port is 8080 then it will drop the packet and print out message using bpf_printk.
Note
The eBPF verifier requires explicit boundary checks to ensure that any access to packet data is safe. Without these checks, the verifier will reject your program, as it can’t guarantee that your memory accesses remain within the valid packet boundaries.Compile the eBPF program and attach it to your interface or tunnel using something similar to the following:
sudo ip route add 10.0.0.3/32 encap bpf out obj drop_egress_8080.o section lwt_out dev tun0
Next, setup a web server on the remote machine
python3 -m http.server 8080
Then, from the eBPF machine run
curl http://10.0.0.3:8080/index.html
You should notice that the connection is dropped and messages in /sys/kernel/debug/tracing/trace_pipe
<idle>-0 [003] b.s21 6747.667466: bpf_trace_printk: Dropping egress packet to port 8080
<idle>-0 [003] b.s21 6748.729064: bpf_trace_printk: Dropping egress packet to port 8080
<idle>-0 [003] b.s21 6749.753690: bpf_trace_printk: Dropping egress packet to port 8080
<idle>-0 [003] b.s21 6750.777898: bpf_trace_printk: Dropping egress packet to port 8080
curl-3437 [001] b..11 8589.106765: bpf_trace_printk: Dropping egress packet to port 8080
<idle>-0 [001] b.s31 8590.112358: bpf_trace_printk: Dropping egress packet to port 8080
This program for sure can be used to inspecting or monitoring, all you need to do is to replace BPF_DROP with BPF_OK. Now let’s look at BPF_PROG_TYPE_LWT_IN programs which can be attached to incoming path of Lightweight Tunnel. Let’s use the previous example and make some changes. Modifying the code to block ingress traffic originated from 10.0.0.3 on port 8080
#include <linux/bpf.h>
#include <linux/ip.h>
#include <linux/tcp.h>
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_endian.h>
#include <linux/in.h>
#define TARGET_IP 0x0A000003 // 10.0.0.3 in hexadecimal
char _license[] SEC("license") = "GPL";
SEC("lwt_in")
int drop_ingress_port_8080(struct __sk_buff *skb) {
void *data = (void *)(long)skb->data;
void *data_end = (void *)(long)skb->data_end;
struct iphdr *iph = data;
if ((void *)iph + sizeof(*iph) > data_end)
return BPF_OK;
if (iph->protocol != IPPROTO_TCP)
return BPF_OK;
int ip_header_length = iph->ihl * 4;
struct tcphdr *tcph = data + ip_header_length;
if ((void *)tcph + sizeof(*tcph) > data_end)
return BPF_OK;
if (iph->saddr == bpf_htonl(TARGET_IP)) {
if (bpf_ntohs(tcph->dest) == 8080) {
bpf_printk("Dropping ingress packet to port 8080 for IP 10.0.0.3\n");
return BPF_DROP;
}
}
return BPF_OK;
}
Compile it then attach it using sudo ip route replace table local local 10.0.0.2/32 encap bpf headroom 14 in obj drop_ingress_8080.o section lwt_in dev tun0. Start a web server on eBPF machine , then from the other machine with IP address 10.0.0.3 run curl http://10.0.0.2:8080 and you should notice that the connection is dropped and messages in /sys/kernel/debug/tracing/trace_pipe
[000] b.s21 81.669152: bpf_trace_printk: Dropping ingress packet to port 8080 for IP 10.0.0.3
[000] b.s21 82.694440: bpf_trace_printk: Dropping ingress packet to port 8080 for IP 10.0.0.3
[000] b.s21 84.741651: bpf_trace_printk: Dropping ingress packet to port 8080 for IP 10.0.0.3
[000] b.s21 88.773985: bpf_trace_printk: Dropping ingress packet to port 8080 for IP 10.0.0.3
I hope these two examples were easy and straightforward, and that LWT is now clearer. Next, we’ll explore the Traffic Control subsystem, which can direct and manage traffic effectively.
3 - Traffic Control
Traffic Control subsystem is designed to schedule packets using a queuing system which controls the traffic direction and filtering. Traffic control can be used to filter traffic by applying rules and traffic shaping among other functions. The core of traffic control is built around qdiscs which stands for queuing disciplines, qdiscs define the rules for how packets are handled by a queuing system.
There are two types of qdiscs, classful and classless. classful qdiscs enable the creation of hierarchical queuing structures to facilitates the implementation of complex traffic management policies. Classful qdiscs consist of two parts, filters and classes. The best definition is in the man page which says the following:
Queueing Discipline: qdisc is short for ‘queueing discipline’ and it is elementary to understanding traffic control. Whenever the Kernel needs to send a packet to an interface, it is enqueued to the qdisc >configured for that interface. Immediately afterwards, the Kernel tries to get as many packets as possible from the qdisc, for giving them to the network adaptor driver.
Classes: Some qdiscs can contain classes, which contain further qdiscs,traffic may then be enqueued in any of the inner qdiscs, which are within the classes. When the kernel tries to dequeue a >packet from such a classful qdisc it can come from any of the classes. A qdisc may for example prioritize certain kinds of traffic by trying to dequeue from certain classes before others.
Filters: A filter is used by a classful qdisc to determine in which class a packet will be enqueued. Whenever traffic arrives at a class with subclasses, it needs to be classified. Various methods >may be employed to do so, one of these are the filters. All filters attached to the class are called, until one of them returns with a verdict. If no verdict was made, other crit
In essence: classful qdiscs have filters which are used to classify traffic and determine which class a packet should be placed in.
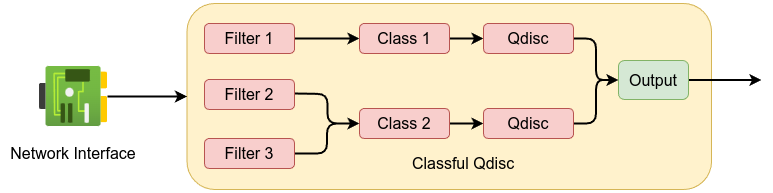
Classless qdiscs are designed to operate as standalone queuing disciplines. classless qdiscs don’t have children or classes which is impossible to attach a filters to it. eBPF filters are intended to work with classful qdiscs where they can classify packets into different classes. You can check which qdisc attached to your network devices is by using ip command or sudo tc qdisc shows the following:
qdisc noqueue 0: dev lo root refcnt 2
qdisc fq_codel 0: dev enp1s0 root refcnt 2 limit 10240p flows 1024 quantum 1514 target 5ms interval 100ms memory_limit 32Mb ecn drop_batch 64
qdisc noqueue on localhost which means no qdisc attached to the localhost which is normal.qdisc fq_codel is attached to the physical interface enp1s0. qdisc fq_codel stands for Fair Queuing Controlled Delay is queuing discipline that classifies data using a stochastic model that it uses a combination of fair queuing and delay control techniques to manage congestion to ensure the fairness of sharing the flow.
limit 10240p this is the queue size and if the limit exceeds this value, packet will start dropping.
flows 1024 this is the number of flow for the incoming packets or the qdisc can track up to 1,024 separate flows.
target 5ms which is the acceptable minimum queue delay.
memory_limit 32Mb sets a limit on the total number of bytes that can be queued in this FQ-CoDel instance.
drop_batch 64 sets the maximum number of packets to drop when limit or memory_limit is exceeded.
Traffic Control has two major components: classifiers and actions. Classifiers are used to inspect packets and decide if they match certain criteria, such as IP addresses, ports or protocols. They essentially sort packets into groups based on rules so that further processing can be applied to the appropriate packets. Actions define what happens to a packet after it has been classified. Once a packet matches a rule, an action is executed on it—such as dropping the packet, changing its priority or redirecting it to another interface.
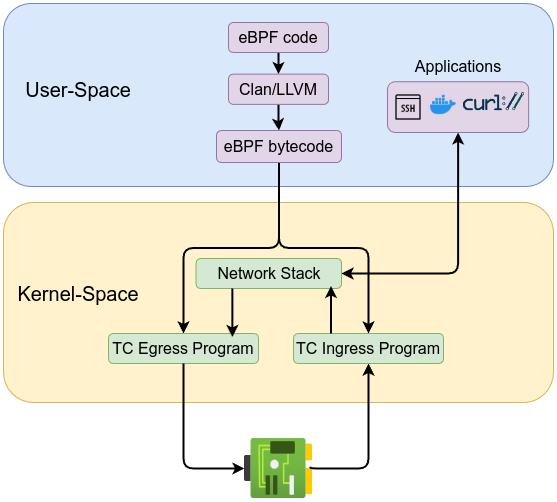
Traffic control eBPF programs are classified either as BPF_PROG_TYPE_SCHED_CLS with SEC("tc") or BPF_PROG_TYPE_SCHED_ACT with SEC("action/").
BPF_PROG_TYPE_SCHED_CLS is often preferred, as it can function as both a classifier and an action executor when used with the direct-action flag. One key advantage is that these eBPF programs can be attached to both egress (outgoing) and ingress (incoming) traffic. This ability allows administrators to inspect, modify and filter packets in both directions.
Note
A single eBPF program instance can only be attached to either egress or ingress on a given interface, but separate instances can be deployed for each direction if needed.
Actions and their corresponding values are defined in include/uapi/linux/pkt_cls.h kernel source code:
#define TC_ACT_UNSPEC (-1)
#define TC_ACT_OK 0
#define TC_ACT_RECLASSIFY 1
#define TC_ACT_SHOT 2
#define TC_ACT_PIPE 3
#define TC_ACT_STOLEN 4
#define TC_ACT_QUEUED 5
#define TC_ACT_REPEAT 6
#define TC_ACT_REDIRECT 7
#define TC_ACT_TRAP 8
Actions and direct-action are defined in this URL which states as the following:
Direct action
When attached in direct action mode, the eBPF program will act as both a classifier and an action. This mode simplifies setups for the most common use cases where we just want to always execute an action. In direct action mode the return value can be one of:
* TC_ACT_UNSPEC (-1) - Signals that the default configured action should be taken.
* TC_ACT_OK (0) - Signals that the packet should proceed.
* TC_ACT_RECLASSIFY (1) - Signals that the packet has to re-start classification from the root qdisc. This is typically used after modifying the packet so its classification might have different results.
* TC_ACT_SHOT (2) - Signals that the packet should be dropped, no other TC processing should happen.
* TC_ACT_PIPE (3) - While defined, this action should not be used and holds no particular meaning for eBPF classifiers.
* TC_ACT_STOLEN (4) - While defined, this action should not be used and holds no particular meaning for eBPF classifiers.
* TC_ACT_QUEUED (5) - While defined, this action should not be used and holds no particular meaning for eBPF classifiers.
* TC_ACT_REPEAT (6) - While defined, this action should not be used and holds no particular meaning for eBPF classifiers.
* TC_ACT_REDIRECT (7) - Signals that the packet should be redirected, the details of how and where to are set as side effects by helpers functions.
Now, let’s look at an example to fully understand the concepts discussed above. In the next example, we use BPF_PROG_TYPE_SCHED_CLS program but will allow us to take actions based on out classification using direct-action later. The code checks for packets on egress with port 8080 and drops them and send a message with bpf_printk.
#include <linux/bpf.h>
#include <linux/if_ether.h>
#include <linux/ip.h>
#include <linux/tcp.h>
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_endian.h>
#include <linux/in.h>
#include <linux/pkt_cls.h>
char _license[] SEC("license") = "GPL";
SEC("tc")
int drop_egress_port_8080(struct __sk_buff *skb) {
void *data = (void *)(long)skb->data;
void *data_end = (void *)(long)skb->data_end;
struct ethhdr *eth = data;
if ((void *)eth + sizeof(*eth) > data_end)
return TC_ACT_OK;
if (bpf_ntohs(eth->h_proto) != ETH_P_IP)
return TC_ACT_OK;
struct iphdr *iph = data + sizeof(*eth);
if ((void *)iph + sizeof(*iph) > data_end)
return TC_ACT_OK;
if (iph->protocol != IPPROTO_TCP)
return TC_ACT_OK;
int ip_header_length = iph->ihl * 4;
struct tcphdr *tcph = data + sizeof(*eth) + ip_header_length;
if ((void *)tcph + sizeof(*tcph) > data_end)
return TC_ACT_OK;
if (bpf_ntohs(tcph->dest) == 8080) {
bpf_printk("Dropping egress packet to port 8080\n");
return TC_ACT_SHOT;
}
return TC_ACT_OK;
}
As shown in the previous code, the program performs a chain of checks. For packets that are not of interest, it returns TC_ACT_OK, allowing them to proceed. However, if the final check detects that the destination port is 8080, it returns TC_ACT_SHOT, which means the packet should be dropped.
Note
When the eBPF program returnsTC_ACT_OK, it signals that the packet should continue its normal processing in the networking stack, effectively “exiting” our code without any special intervention like dropping or redirecting it.
Compile the code using LLVM/clang, then add the clsact qdisc, which enables hooking eBPF programs for both ingress (incoming) and egress (outgoing) traffic sudo tc qdisc add dev qdisc clsact
Next, attach the object file to the egress traffic with the direct-action flag: sudo tc filter add dev enp1s0 egress bpf direct-action obj tc_drop_egress.o sec tc. On a separate machine, start a web server on port 8080 using python3 -m http.server 8080. Back to the eBPF machine, executing a curl command curl http://192.168.1.6:8080/ you will notice that traffic is being dropped and you can see the debug messages using sudo cat /sys/kernel/debug/tracing/trace_pipe or you could use sudo tc exec bpf dbg to show the debug messages, which might look like:
Running! Hang up with ^C!
curl-1636 [003] b..1. 1735.290483: bpf_trace_printk: Dropping egress packet to port 8080
<idle>-0 [003] b.s3. 1736.321969: bpf_trace_printk: Dropping egress packet to port 8080
<idle>-0 [001] b.s3. 1736.834411: bpf_trace_printk: Dropping egress packet to port 8080
<idle>-0 [003] b.s3. 1737.346341: bpf_trace_printk: Dropping egress packet to port 8080
<idle>-0 [003] b.s3. 1737.858194: bpf_trace_printk: Dropping egress packet to port 8080
<idle>-0 [003] b.s3. 1738.370403: bpf_trace_printk: Dropping egress packet to port 8080
The attachment can be stopped by deleting the qdisc using sudo tc qdisc del dev enp1s0 clsact. I hope that Traffic Control is much clearer at this point.
If we want to set up a sensor to analyze traffic from a specific service or port, all we need to do is redirect that traffic using the bpf_clone_redirect helper function to a predefined interface for tapping. The cloning will allow us to monitor traffic with actively interfering or impacting performance. The redirected traffic can then be forwarded to traffic analysis tools such as Security Onion, Suricata, Snort, zeek, …etc. The bpf_clone_redirect helper function clones the packet and then redirects the clone to another interface, while the bpf_redirect helper function redirects the packet without cloning it. Both helper functions require the target interface’s ifindex, which represents the interface ID. bpf_clone_redirect helper function has a prototype as the following:
static long (* const bpf_clone_redirect)(struct __sk_buff *skb, __u32 ifindex, __u64 flags) = (void *) 13;
Cloning traffic not just for IPS/IDS , it can be also used to keep full packet capture (FPC) for later to be used in incident analysis or compromise assessment.
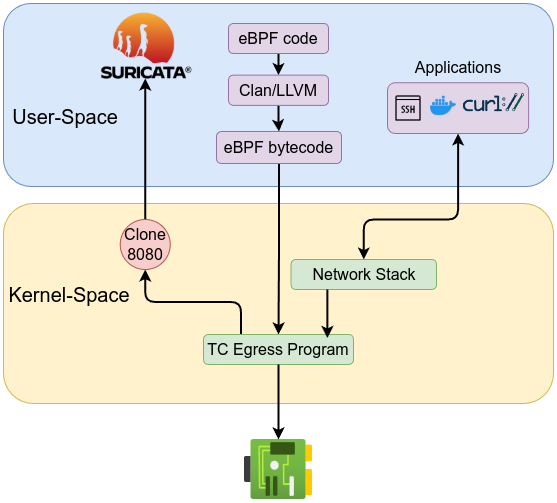
First, let’s setup the interface by creating dummy interface sudo ip link add dummy0 type dummy, then bring the interface up using sudo ip link set dummy0 up, then verify the interface ip link show dummy0 which gives similar to the following:
4: dummy0: <BROADCAST,NOARP,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/ether 16:aa:51:3c:b7:7b brd ff:ff:ff:ff:ff:ff
The interface ID is 4. Now let’s modify the previous code to allow the traffic on port 8080 while cloning it to the dummy interface with ID 4.
#include <linux/bpf.h>
#include <linux/if_ether.h>
#include <linux/ip.h>
#include <linux/tcp.h>
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_endian.h>
#include <linux/in.h>
#include <linux/pkt_cls.h>
char _license[] SEC("license") = "GPL";
SEC("tc")
int clone_egress_port_8080(struct __sk_buff *skb) {
void *data = (void *)(long)skb->data;
void *data_end = (void *)(long)skb->data_end;
struct ethhdr *eth = data;
if ((void *)eth + sizeof(*eth) > data_end)
return TC_ACT_OK;
if (bpf_ntohs(eth->h_proto) != ETH_P_IP)
return TC_ACT_OK;
struct iphdr *iph = data + sizeof(*eth);
if ((void *)iph + sizeof(*iph) > data_end)
return TC_ACT_OK;
if (iph->protocol != IPPROTO_TCP)
return TC_ACT_OK;
int ip_header_length = iph->ihl * 4;
struct tcphdr *tcph = data + sizeof(*eth) + ip_header_length;
if ((void *)tcph + sizeof(*tcph) > data_end)
return TC_ACT_OK;
if (bpf_ntohs(tcph->dest) == 8080) {
int target_ifindex = 4;
bpf_printk("Cloning packet to ifindex %d and allowing original packet\n", target_ifindex);
bpf_clone_redirect(skb, target_ifindex, 0);
return TC_ACT_OK;
}
return TC_ACT_OK;
}
Compile and attach the eBPF program then setup a web server as we did in the previous example. Next, start capturing the traffic on the dummy interface using sudo tcpdump -i dummy0 then curl http://192.168.1.6:8080/index.html You should see tcpdump output similar to the following:
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on dummy0, link-type EN10MB (Ethernet), snapshot length 262144 bytes
23:12:53.941290 IP debian.58768 > client-Standard-PC-Q35-ICH9-2009.http-alt: Flags [S], seq 1415486505, win 64240, options [mss 1460,sackOK,TS val 3409122040 ecr 0,nop,wscale 7], length 0
23:12:53.941711 IP debian.58768 > client-Standard-PC-Q35-ICH9-2009.http-alt: Flags [.], ack 1257763673, win 502, options [nop,nop,TS val 3409122040 ecr 2981277197], length 0
23:12:53.941792 IP debian.58768 > client-Standard-PC-Q35-ICH9-2009.http-alt: Flags [P.], seq 0:93, ack 1, win 502, options [nop,nop,TS val 3409122040 ecr 2981277197], length 93: HTTP: GET /index.html HTTP/1.1
23:12:53.942842 IP debian.58768 > client-Standard-PC-Q35-ICH9-2009.http-alt: Flags [.], ack 185, win 501, options [nop,nop,TS val 3409122041 ecr 2981277198], length 0
23:12:53.942980 IP debian.58768 > client-Standard-PC-Q35-ICH9-2009.http-alt: Flags [F.], seq 93, ack 188, win 501, options [nop,nop,TS val 3409122041 ecr 2981277198], length 0
The traffic captured on the dummy interface can then be analyzed by Suricata or any other network analysis and monitoring tool. The cloned traffic can also be sent to another NIC to be sent out to a sensor machine such as Security Onion server (forward nodes).
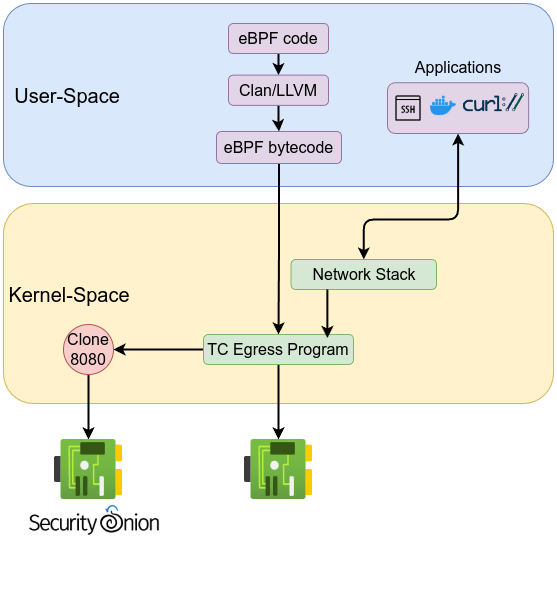
The next example demonstrates one of the capabilities of traffic control—manipulating traffic. In this example, the program will change the first 4 bytes of an HTTP response (initiated from port 8080) to ‘XXXX’. This means that instead of seeing ‘HTTP/1.0’, you would see ‘XXXX/1.0’.
The steps are as follows:
- Perform the necessary packet checks until you reach the TCP header.
- Calculate the TCP header length to determine the exact offset of the payload.
- Read the first 4 bytes of the payload.
- Replace these 4 bytes with ‘XXXX’ using the
bpf_skb_store_byteshelper function. - Recalculate the checksum using the
bpf_l4_csum_replacehelper function.
bpf_skb_store_bytes helper function has the following prototype:
static long (* const bpf_skb_store_bytes)(struct __sk_buff *skb, __u32 offset, const void *from, __u32 len, __u64 flags) = (void *) 9;
While bpf_l4_csum_replace helper function has the following prototype:
static long (* const bpf_l4_csum_replace)(struct __sk_buff *skb, __u32 offset, __u64 from, __u64 to, __u64 flags) = (void *) 11;
#include <linux/bpf.h>
#include <linux/if_ether.h>
#include <linux/ip.h>
#include <linux/tcp.h>
#include <linux/in.h>
#include <linux/pkt_cls.h>
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_endian.h>
char _license[] SEC("license") = "GPL";
SEC("tc")
int modify_http_response(struct __sk_buff *skb) {
void *data = (void *)(long)skb->data;
void *data_end = (void *)(long)skb->data_end;
struct ethhdr *eth = data;
if ((void *)eth + sizeof(*eth) > data_end)
return TC_ACT_OK;
if (bpf_ntohs(eth->h_proto) != ETH_P_IP)
return TC_ACT_OK;
struct iphdr *iph = data + sizeof(*eth);
if ((void *)iph + sizeof(*iph) > data_end)
return TC_ACT_OK;
if (iph->protocol != IPPROTO_TCP)
return TC_ACT_OK;
int ip_hdr_len = iph->ihl * 4;
struct tcphdr *tcph = data + sizeof(*eth) + ip_hdr_len;
if ((void *)tcph + sizeof(*tcph) > data_end)
return TC_ACT_OK;
if (bpf_ntohs(tcph->source) != 8080)
return TC_ACT_OK;
int tcp_hdr_len = tcph->doff * 4;
void *payload = (void *)tcph + tcp_hdr_len;
if (payload + 4 > data_end) // ensure there are at least 4 bytes in the payload
return TC_ACT_OK;
char orig_val[4];
if (bpf_skb_load_bytes(skb, (payload - data), orig_val, 4) < 0)
return TC_ACT_OK;
if (orig_val[0] == 'H' && orig_val[1] == 'T' && orig_val[2] == 'T' && orig_val[3] == 'P') {
char new_val[4] = {'X', 'X', 'X', 'X'};
if (bpf_skb_store_bytes(skb, (payload - data), new_val, 4, 0) < 0)
return TC_ACT_OK;
int tcp_csum_offset = ((void *)tcph - data) + offsetof(struct tcphdr, check);
bpf_l4_csum_replace(skb, tcp_csum_offset, *((__u32 *)orig_val), *((__u64 *)new_val), 4);
bpf_printk("Modified HTTP response header from 'HTTP' to 'XXXX'\n");
}
return TC_ACT_OK;
}
Compile the code and attach it on ingress traffic using sudo tc filter add dev enp1s0 ingress bpf direct-action obj modify_http_response.o sec tc.
Next, setup a web server on another machine. Then, from the eBPF machine, execute the following:
nc 192.168.1.6 8080
GET /index.html HTTP/1.1
Host: 192.168.1.6:8080
The output should look similar to the following:
GET /index.html HTTP/1.1
Host: 192.168.1.6:8080
XXXX/1.0 404 File not found
Server: SimpleHTTP/0.6 Python/3.12.3
Date: Thu, 06 Mar 2025 05:13:32 GMT
Connection: close
Content-Type: text/html;charset=utf-8
Content-Length: 335
HTTP/1.0 404 File not found is now replaced with XXXX/1.0 404 File not found.
Note
TC Hardware Offload allows NICs to handle specific traffic control tasks (like filtering and policing) in hardware instead of the CPU similar to how XDP offloads packet processing to reduce CPU overhead (XDP will be explained next).Next, we will talk about XDP (Express Data Path), where XDP programs are executed before packets reach the kernel network stack.
4 - XDP
XDP (eXpress Data Path) is a high-performance packet processing framework integrated directly into the Linux kernel. It leverages eBPF (extended Berkeley Packet Filter) technology to enable customizable packet processing at the earliest possible stage when packets arrive at the network driver (ingress traffic) before the kernel allocates an sk_buff for them. By operating before the kernel’s traditional networking stack processes packets, XDP dramatically reduces latency, improves throughput, and minimizes processing overhead. One of the core reasons XDP achieves such high efficiency is by avoiding traditional kernel operations, such as allocation of the socket buffer structure (sk_buff) or generic receive offload (GRO), which are expensive and unnecessary at this early stage. Unlike traditional Linux networking, XDP does not require packets to be wrapped into the kernel’s socket buffer (sk_buff). The sk_buff structure, while powerful and flexible, is relatively heavyweight and incurs significant performance costs because of the extensive metadata and management overhead it introduces. By bypassing the sk_buff, XDP can directly manipulate raw packet data significantly boosting packet processing performance. Additionally, XDP provides the capability for atomic runtime updates to its programs, offering significant operational flexibility without traffic disruption.
Note
GRO (Generic Receive Offload) is a Linux kernel feature which aggregates multiple incoming network packets into fewer larger packets before passing them up the kernel networking stack to reduces per-packet processing overhead.Each packet processed by XDP is represented by a special context structure called xdp_buff. The primary difference between the xdp_buff and traditional sk_buff is related to the processing stage and the complexity of these structures. The xdp_buff is significantly simpler and is employed much earlier in the packet-processing pipeline. XDP programs are classified as BPF_PROG_TYPE_XDP and it used xdp_buff structure which is defined in include/net/xdp.h as the following:
struct xdp_buff {
void *data;
void *data_end;
void *data_meta;
void *data_hard_start;
struct xdp_rxq_info *rxq;
struct xdp_txq_info *txq;
u32 frame_sz;
u32 flags;
};
XDP operates in three distinct modes that suit different scenarios: native XDP, offloaded XDP and generic XDP.
Native XDP is the default and most performant mode, running directly within network driver. It delivers optimal efficiency and minimal latency, supported broadly across modern NICs. Offloaded XDP leverages specialized hardware (SmartNICs) by executing XDP programs directly on NIC hardware, freeing CPU resources and pushing performance even higher, ideal for demanding high-throughput scenarios. Generic XDP is available when native support isn’t present. It executes within the kernel’s networking stack rather than the NIC driver, primarily useful for development and testing but provides lower performance due to the additional overhead.
An XDP program uses return codes which are defined in include/uapi/linux/bpf.h header file as the following:
enum xdp_action {
XDP_ABORTED = 0,
XDP_DROP,
XDP_PASS,
XDP_TX,
XDP_REDIRECT,
};
These return codes are used to instruct the network driver on how to handle incoming packets. The return codes are as follows:
XDP_DROP: Immediately drops packets at the NIC driver, ideal for quick, resource-efficient firewalling and DDoS mitigation.XDP_PASS: Forwards the packet to the kernel’s regular network stack.XDP_TX: Sends the packet back out of the same NIC it arrived on, often used in load balancing and packet rewriting scenarios.XDP_REDIRECT: Sends the packet out through a different NIC or redirects it to a different processing CPU.XDP_ABORTED: Signifies an error condition, useful during debugging and development.
The following diagram shows the basic XDP workflow:
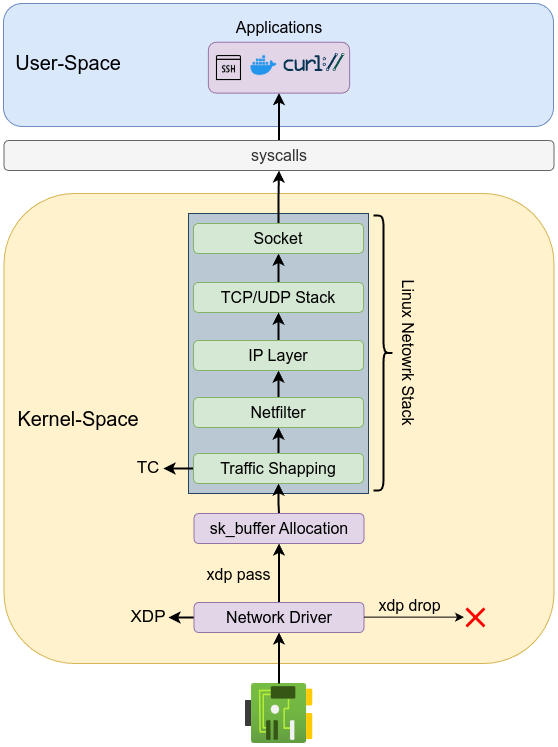
One common use case of XDP is DDoS mitigation, where it quickly identifies and drops malicious traffic with minimal processing overhead. XDP is also heavily used for advanced packet forwarding and load balancing, enabling quick header modifications and packet routing decisions directly at the driver level. Network analytics and sampling are other powerful XDP applications, where packet data can be efficiently captured and transmitted to user-space applications through memory-mapped ring buffers. Custom protocol handling, such as encapsulation or decapsulation, is easily achievable with XDP, facilitating efficient interactions with upper-layer network functions such as the GRO engine. Real-world deployments by companies like Facebook (Katran) and Cloudflare have demonstrated substantial performance improvements by integrating XDP for load balancing, firewalling, and DDoS mitigation. For more details please visit Cilium’s documentation.
The next example is explained previously. The following code performs a chain of checks to drop port 8080 on ingress traffic using XDP_DROP. The code uses xdp_md as context instead of sk_buff as previously explained.
#include <linux/bpf.h>
#include <linux/if_ether.h>
#include <linux/ip.h>
#include <linux/tcp.h>
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_endian.h>
#include <linux/in.h>
char _license[] SEC("license") = "GPL";
SEC("xdp")
int drop_ingress_port_8080(struct xdp_md *ctx) {
void *data = (void *)(long)ctx->data;
void *data_end = (void *)(long)ctx->data_end;
struct ethhdr *eth = data;
if ((void *)eth + sizeof(*eth) > data_end)
return XDP_PASS;
if (bpf_ntohs(eth->h_proto) != ETH_P_IP)
return XDP_PASS;
struct iphdr *iph = data + sizeof(*eth);
if ((void *)iph + sizeof(*iph) > data_end)
return XDP_PASS;
if (iph->protocol != IPPROTO_TCP)
return XDP_PASS;
int ip_header_length = iph->ihl * 4;
struct tcphdr *tcph = data + sizeof(*eth) + ip_header_length;
if ((void *)tcph + sizeof(*tcph) > data_end)
return XDP_PASS;
if (bpf_ntohs(tcph->dest) == 8080) {
bpf_printk("Dropping XDP egress packet port 8080\n");
return XDP_DROP;
}
return XDP_PASS;
}
Compile the code using LLVM then load it with: sudo ip link set dev enp1s0 xdp obj xdp_drop_8080.o sec xdp.
Note
xdp obj xdp_drop_8080.o This command loads an XDP program from the ELF object file named xdp_drop_8080.o. By default, the system attempts to use native driver mode if available, falling back to generic mode otherwise. You can also force a specific mode by using one of these options: xdpgeneric: Enforce generic XDP mode.
xdpdrv: Enforce native driver XDP mode. xdpoffload: Enforce offloaded XDP mode for supported hardware. For example,sudo ip link set dev enp1s0 xdpgeneric obj x.o sec xdp will enforce generic XDP mode. To unload the XDP program, run: sudo ip link set dev enp1s0 xdp off.
As we mentioned earlier, XDP can operate as an efficient load balancer. In the following example, we have an ICMP load balancer implemented using a round-robin approach connected to two backend servers. When load balancer receives ICMP echo request will dispatch it to the servers in order. The idea behind this load balancer is that it routes by re-writing the destination IP, delivering each request to the backend servers in sequential.
Note
A round-robin load balancer distributes network traffic evenly across a group of servers by sequentially forwarding each new request to the next server in a rotating list.The IP header checksum must be recalculated, RFC 1071 explaining in details how IP header checksum, but to simplify the process it has two steps: one’s complement addition and folding process. bpf_csum_diff helper function to calculate a checksum difference from the raw buffer pointed by from, of length from_size (that must be a multiple of 4), towards the raw buffer pointed by to, of size to_size (that must be a multiple of 4) and which has the following prototype:
static __s64 (* const bpf_csum_diff)(__be32 *from, __u32 from_size, __be32 *to, __u32 to_size, __wsum seed) = (void *) 28;
In this example, the XPD ICMP load balancer is configured on IP address 192.168.1.2. It has two backend servers: the first backend server has IP address 192.168.1.3 with MAC address 52:54:00:ff:ff:55, and the second backend server has IP address 192.168.1.4 with MAC address 52:54:00:5d:6e:a1. When an ICMP Echo Request reaches the load balancer, it will redirect the first request to the first backend server and the second Echo Request to the second backend server.
#include <linux/bpf.h>
#include <linux/if_ether.h>
#include <linux/ip.h>
#include <linux/in.h>
#include <linux/icmp.h>
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_endian.h>
#define LB_IP __constant_htonl(0xC0A87AEE) /* 192.168.1.2 */
char _license[] SEC("license") = "GPL";
struct backend {
__u32 ip;
unsigned char mac[ETH_ALEN];
};
struct {
__uint(type, BPF_MAP_TYPE_ARRAY);
__uint(max_entries, 1);
__type(key, __u32);
__type(value, __u32);
} rr_map SEC(".maps");
struct {
__uint(type, BPF_MAP_TYPE_ARRAY);
__uint(max_entries, 2);
__type(key, __u32);
__type(value, struct backend);
} backend_map SEC(".maps");
static __always_inline __u16 ip_recalc_csum(struct iphdr *iph)
{
iph->check = 0;
unsigned int csum = bpf_csum_diff(0, 0, (unsigned int *)iph, sizeof(*iph), 0);
for (int i = 0; i < 4; i++) {
if (csum >> 16)
csum = (csum & 0xffff) + (csum >> 16);
}
return ~csum;
}
SEC("xdp")
int icmp_lb(struct xdp_md *ctx)
{
void *data = (void *)(long)ctx->data;
void *data_end = (void *)(long)ctx->data_end;
struct ethhdr *eth = data;
if ((void*)(eth + 1) > data_end)
return XDP_PASS;
if (eth->h_proto != bpf_htons(ETH_P_IP))
return XDP_PASS;
struct iphdr *iph = data + sizeof(*eth);
if ((void*)(iph + 1) > data_end)
return XDP_PASS;
if (iph->daddr != LB_IP)
return XDP_PASS;
if (iph->protocol != IPPROTO_ICMP)
return XDP_PASS;
__u32 bk = 0;
struct backend *b_ptr = bpf_map_lookup_elem(&backend_map, &bk);
if (b_ptr && b_ptr->ip == 0) {
struct backend be0 = {
.ip = __constant_htonl(0xC0A87A58),
.mac = {0x52, 0x54, 0x00, 0xff, 0xff, 0x55}
};
bpf_map_update_elem(&backend_map, &bk, &be0, BPF_ANY);
bk = 1;
struct backend be1 = {
.ip = __constant_htonl(0xC0A87AD7),
.mac = {0x52, 0x54, 0x00, 0x5d, 0x6e, 0xa1}
};
bpf_map_update_elem(&backend_map, &bk, &be1, BPF_ANY);
}
__u32 rr_key = 0;
__u32 *p_index = bpf_map_lookup_elem(&rr_map, &rr_key);
if (!p_index)
return XDP_PASS;
__u32 index = *p_index;
*p_index = (index + 1) % 2;
__u32 backend_key = index;
struct backend *be = bpf_map_lookup_elem(&backend_map, &backend_key);
if (!be)
return XDP_PASS;
iph->daddr = be->ip;
iph->check = ip_recalc_csum(iph);
__builtin_memcpy(eth->h_dest, be->mac, ETH_ALEN);
return XDP_TX;
}
First, structure was define for backends’ IPs unsigned 32-bit integer and MAC addresses with ETH_ALEN of length which is 6 as defined in include/linux/if_ether.h. Second, define a map of type BPF_MAP_TYPE_ARRAY to track the state of our round-robin load balancer with only one entry and key 0 should be initialized to 0. Third, define a map of type BPF_MAP_TYPE_ARRAY to store backends’ IPs and MAC addresses and key 0 should be initialized to 0.
struct backend {
__u32 ip;
unsigned char mac[ETH_ALEN];
};
struct {
__uint(type, BPF_MAP_TYPE_ARRAY);
__uint(max_entries, 1);
__type(key, __u32);
__type(value, __u32);
} rr_map SEC(".maps");
struct {
__uint(type, BPF_MAP_TYPE_ARRAY);
__uint(max_entries, 2);
__type(key, __u32);
__type(value, struct backend);
} backend_map SEC(".maps");
Then, the code performs chain of checks to ensure that the code is only process ICMP packets.
/* Parse Ethernet header */
struct ethhdr *eth = data;
if ((void*)(eth + 1) > data_end)
return XDP_PASS;
if (eth->h_proto != bpf_htons(ETH_P_IP))
return XDP_PASS;
/* Parse IP header */
struct iphdr *iph = data + sizeof(*eth);
if ((void*)(iph + 1) > data_end)
return XDP_PASS;
/* Process only packets destined to LB_IP */
if (iph->daddr != LB_IP)
return XDP_PASS;
/* Process only ICMP packets */
if (iph->protocol != IPPROTO_ICMP)
return XDP_PASS;
Next, the code populates the backend_map with backend information and selects a backend using round-robin from the rr_map.
__u32 bk = 0;
struct backend *b_ptr = bpf_map_lookup_elem(&backend_map, &bk);
if (b_ptr && b_ptr->ip == 0) {
struct backend be0 = {
.ip = __constant_htonl(0xC0A87A58),
.mac = {0x52, 0x54, 0x00, 0xff, 0xff, 0x55}
};
bpf_map_update_elem(&backend_map, &bk, &be0, BPF_ANY);
bk = 1;
struct backend be1 = {
.ip = __constant_htonl(0xC0A87AD7),
.mac = {0x52, 0x54, 0x00, 0x5d, 0x6e, 0xa1}
};
bpf_map_update_elem(&backend_map, &bk, &be1, BPF_ANY);
}
__u32 rr_key = 0;
__u32 *p_index = bpf_map_lookup_elem(&rr_map, &rr_key);
if (!p_index)
return XDP_PASS;
__u32 index = *p_index;
*p_index = (index + 1) % 2;
__u32 backend_key = index;
struct backend *be = bpf_map_lookup_elem(&backend_map, &backend_key);
Then, the code rewrites the destination IP address to the chosen backend from round-robin map followed by the calculation of the IP header checksum using the following:
static __always_inline __u16 ip_recalc_csum(struct iphdr *iph)
{
iph->check = 0;
unsigned int csum = bpf_csum_diff(0, 0, (unsigned int *)iph, sizeof(*iph), 0);
for (int i = 0; i < 4; i++) {
if (csum >> 16)
csum = (csum & 0xffff) + (csum >> 16);
}
return ~csum;
}
In short, the checksum is calculated by summing all the 16-bit words of the header using one’s complement arithmetic. “Folding” means that if the sum exceeds 16 bits, any overflow (carry) from the high-order bits is added back into the lower 16 bits. Finally, the one’s complement (bitwise NOT) of that folded sum gives the checksum.
As we mentioned before,bpf_csum_diff helper function with seed of zero performs one’s complement addition. Next, the folding process which has the following in one of four iteration:
- Check that right shift by 16 bits
csum >> 16(discards the lower 4 hex digits) ofbpf_csum_diffoutput is nonzero. - Extract the lower 16 bits from the output of
bpf_csum_diffusing a bitwise AND with0xFFFF. - Shift the current checksum value right by 16 bits to extract any carry beyond the lower 16 bits, then add that carry to the lower 16 bits (obtained with
csum & 0xffff), and store the result incsum. - Repeat this process (up to 4 iterations) until no carry remains, then return the bitwise NOT of the final result.
The final step in the code is to set destination MAC address to the chosen backend’s MAC address using__builtin_memcpy. __builtin_memcpy is not a standard C library function; it’s a compiler-provided function that offers optimized memory copying and has the following prototype:
void *__builtin_memcpy(void *dest, const void *src, size_t size);
Compile the code. Then, attach the XDP program to your interface sudo ip link set dev enp1s0 xdp obj icmp_lb.o sec xdp. Next, capture ICMP traffic on both backend using sudo tcpdump -i enp1s0 icmp, then from fourth machine, send Echo request to the load balancer ping 192.168.1.2
PING 192.168.1.2 (192.168.122.238) 56(84) bytes of data.
64 bytes from 192.168.1.3: icmp_seq=1 ttl=64 time=0.442 ms (DIFFERENT ADDRESS!)
64 bytes from 192.168.1.4: icmp_seq=2 ttl=64 time=0.667 ms (DIFFERENT ADDRESS!)
64 bytes from 192.168.1.3: icmp_seq=3 ttl=64 time=0.713 ms (DIFFERENT ADDRESS!)
64 bytes from 192.168.1.4: icmp_seq=4 ttl=64 time=0.670 ms (DIFFERENT ADDRESS!)
64 bytes from 192.168.1.3: icmp_seq=5 ttl=64 time=0.570 ms (DIFFERENT ADDRESS!)
64 bytes from 192.168.1.4: icmp_seq=6 ttl=64 time=0.647 ms (DIFFERENT ADDRESS!)
64 bytes from 192.168.1.3: icmp_seq=7 ttl=64 time=0.715 ms (DIFFERENT ADDRESS!)
64 bytes from 192.168.1.4: icmp_seq=8 ttl=64 time=0.715 ms (DIFFERENT ADDRESS!)
tcpdumpfrom the first backend:
05:14:35.264928 IP _gateway > test1-Standard-PC-Q35-ICH9-2009: ICMP echo request, id 16, seq 1, length 64
05:14:35.264969 IP test1-Standard-PC-Q35-ICH9-2009 > _gateway: ICMP echo reply, id 16, seq 1, length 64
05:14:37.321642 IP _gateway > test1-Standard-PC-Q35-ICH9-2009: ICMP echo request, id 16, seq 3, length 64
05:14:37.321694 IP test1-Standard-PC-Q35-ICH9-2009 > _gateway: ICMP echo reply, id 16, seq 3, length 64
05:14:39.370002 IP _gateway > test1-Standard-PC-Q35-ICH9-2009: ICMP echo request, id 16, seq 5, length 64
05:14:39.370068 IP test1-Standard-PC-Q35-ICH9-2009 > _gateway: ICMP echo reply, id 16, seq 5, length 64
05:14:41.417230 IP _gateway > test1-Standard-PC-Q35-ICH9-2009: ICMP echo request, id 16, seq 7, length 64
05:14:41.417282 IP test1-Standard-PC-Q35-ICH9-2009 > _gateway: ICMP echo reply, id 16, seq 7, length 64
tcpdumpfrom the second backend:
05:14:36.273275 IP _gateway > test2-Standard-PC-Q35-ICH9-2009: ICMP echo request, id 16, seq 2, length 64
05:14:36.273355 IP test2-Standard-PC-Q35-ICH9-2009 > _gateway: ICMP echo reply, id 16, seq 2, length 64
05:14:38.320876 IP _gateway > test2-Standard-PC-Q35-ICH9-2009: ICMP echo request, id 16, seq 4, length 64
05:14:38.320933 IP test2-Standard-PC-Q35-ICH9-2009 > _gateway: ICMP echo reply, id 16, seq 4, length 64
05:14:40.368579 IP _gateway > test2-Standard-PC-Q35-ICH9-2009: ICMP echo request, id 16, seq 6, length 64
05:14:40.368632 IP test2-Standard-PC-Q35-ICH9-2009 > _gateway: ICMP echo reply, id 16, seq 6, length 64
05:14:42.420358 IP _gateway > test2-Standard-PC-Q35-ICH9-2009: ICMP echo request, id 16, seq 8, length 64
05:14:42.420406 IP test2-Standard-PC-Q35-ICH9-2009 > _gateway: ICMP echo reply, id 16, seq 8, length 64
Notice the sequence of ICMP packets: each Echo request is sent to a different backend server. XDP can also be used to extract metadata from packets which can then be sent to network analysis tool for further investigation, stored for logging as a flight record, or used to assist in incident investigation.
The following example extracts metadata of ingress traffic (source IP, source port, destination IP, destination port and protocol) and send the extracted metadata to ring buffer that can be accessed from user space.
#include <linux/bpf.h>
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_endian.h>
#include <linux/if_ether.h>
#include <linux/ip.h>
#include <linux/udp.h>
#include <linux/tcp.h>
#include <linux/in.h>
char _license[] SEC("license") = "GPL";
struct metadata_t {
__u32 src_ip;
__u32 dst_ip;
__u16 src_port;
__u16 dst_port;
__u8 protocol;
};
struct {
__uint(type, BPF_MAP_TYPE_RINGBUF);
__uint(max_entries, 1 << 24);
__uint(map_flags, 0);
} ringbuf SEC(".maps");
SEC("xdp")
int xdp_extract_metadata(struct xdp_md *ctx)
{
void *data_end = (void *)(long)ctx->data_end;
void *data = (void *)(long)ctx->data;
struct ethhdr *eth = data;
if ((void *)(eth + 1) > data_end)
return XDP_PASS;
if (bpf_ntohs(eth->h_proto) != ETH_P_IP)
return XDP_PASS;
struct iphdr *iph = (void *)(eth + 1);
if ((void *)(iph + 1) > data_end)
return XDP_PASS;
__u16 src_port = 0;
__u16 dst_port = 0;
if (iph->protocol == IPPROTO_TCP || iph->protocol == IPPROTO_UDP) {
__u64 ip_header_size = iph->ihl * 4;
__u64 offset = sizeof(*eth) + ip_header_size;
if (offset + sizeof(struct udphdr) > (unsigned long)(data_end - data))
return XDP_PASS;
struct udphdr *uh = data + offset;
if ((void *)(uh + 1) > data_end)
return XDP_PASS;
src_port = uh->source;
dst_port = uh->dest;
}
struct metadata_t *meta = bpf_ringbuf_reserve(&ringbuf, sizeof(*meta), 0);
if (!meta)
return XDP_PASS;
meta->src_ip = iph->saddr;
meta->dst_ip = iph->daddr;
meta->src_port = src_port;
meta->dst_port = dst_port;
meta->protocol = iph->protocol;
bpf_ringbuf_submit(meta, 0);
return XDP_PASS;
}
The code performs chain of checks to extract ports for TCP or UDP, for other protocols, leave ports as 0.
__u16 src_port = 0;
__u16 dst_port = 0;
if (iph->protocol == IPPROTO_TCP || iph->protocol == IPPROTO_UDP) {
__u64 ip_header_size = iph->ihl * 4ULL;
__u64 offset = sizeof(*eth) + ip_header_size;
if (offset + sizeof(struct udphdr) > (unsigned long)(data_end - data))
return XDP_PASS;
struct udphdr *uh = data + offset;
if ((void *)(uh + 1) > data_end)
return XDP_PASS;
src_port = uh->source;
dst_port = uh->dest;
}
Then fill out the metadata event
meta->src_ip = iph->saddr;
meta->dst_ip = iph->daddr;
meta->src_port = src_port;
meta->dst_port = dst_port;
meta->protocol = iph->protocol;
Finally, submit the metadata to the ring buffer. The following user-space program loads the XDP object file, attaches it to the required interface, and retrieves metadata from the ring buffer.
#include <stdio.h>
#include <stdlib.h>
#include <signal.h>
#include <unistd.h>
#include <arpa/inet.h>
#include <string.h>
#include <net/if.h>
#include <errno.h>
#include <linux/if_link.h>
#include <bpf/libbpf.h>
#include <bpf/bpf.h>
#include <netinet/in.h>
#ifndef XDP_FLAGS_DRV
#define XDP_FLAGS_DRV (1U << 0)
#endif
struct metadata_t {
__u32 src_ip;
__u32 dst_ip;
__u16 src_port;
__u16 dst_port;
__u8 protocol;
};
static int handle_event(void *ctx, void *data, size_t data_sz)
{
if (data_sz < sizeof(struct metadata_t)) {
fprintf(stderr, "Ring buffer event too small\n");
return 0;
}
struct metadata_t *md = data;
char src_str[INET_ADDRSTRLEN];
char dst_str[INET_ADDRSTRLEN];
inet_ntop(AF_INET, &md->src_ip, src_str, sizeof(src_str));
inet_ntop(AF_INET, &md->dst_ip, dst_str, sizeof(dst_str));
const char *proto_name;
switch (md->protocol) {
case IPPROTO_TCP:
proto_name = "TCP";
break;
case IPPROTO_UDP:
proto_name = "UDP";
break;
case IPPROTO_ICMP:
proto_name = "ICMP";
break;
default:
proto_name = "UNKNOWN";
break;
}
printf("Packet: %s:%u -> %s:%u, protocol: %s\n",
src_str, ntohs(md->src_port),
dst_str, ntohs(md->dst_port),
proto_name);
return 0;
}
int main(int argc, char **argv)
{
struct bpf_object *obj = NULL;
struct bpf_program *prog = NULL;
struct bpf_map *map = NULL;
struct ring_buffer *rb = NULL;
int prog_fd, map_fd, err, ifindex;
char pin_path[256];
if (argc < 2) {
fprintf(stderr, "Usage: %s <ifname>\n", argv[0]);
return 1;
}
ifindex = if_nametoindex(argv[1]);
if (!ifindex) {
fprintf(stderr, "Invalid interface name: %s\n", argv[1]);
return 1;
}
libbpf_set_strict_mode(LIBBPF_STRICT_ALL);
obj = bpf_object__open_file("xdp_extract_metadata.o", NULL);
if (!obj) {
fprintf(stderr, "ERROR: bpf_object__open_file() failed\n");
return 1;
}
err = bpf_object__load(obj);
if (err) {
fprintf(stderr, "ERROR: bpf_object__load() failed %d\n", err);
goto cleanup;
}
prog = bpf_object__find_program_by_name(obj, "xdp_extract_metadata");
if (!prog) {
fprintf(stderr, "ERROR: couldn't find xdp program in ELF\n");
goto cleanup;
}
prog_fd = bpf_program__fd(prog);
if (prog_fd < 0) {
fprintf(stderr, "ERROR: couldn't get file descriptor for XDP program\n");
goto cleanup;
}
err = bpf_xdp_attach(ifindex, prog_fd, XDP_FLAGS_DRV, NULL);
if (err) {
fprintf(stderr, "ERROR: bpf_xdp_attach(ifindex=%d) failed (err=%d): %s\n",
ifindex, err, strerror(-err));
goto cleanup;
}
printf("Attached XDP program on ifindex %d\n", ifindex);
map = bpf_object__find_map_by_name(obj, "ringbuf");
if (!map) {
fprintf(stderr, "ERROR: couldn't find ringbuf map in ELF\n");
goto cleanup;
}
map_fd = bpf_map__fd(map);
if (map_fd < 0) {
fprintf(stderr, "ERROR: couldn't get ringbuf map fd\n");
goto cleanup;
}
rb = ring_buffer__new(map_fd, handle_event, NULL, NULL);
if (!rb) {
fprintf(stderr, "ERROR: ring_buffer__new() failed\n");
goto cleanup;
}
printf("Listening for events...\n");
while (1) {
err = ring_buffer__poll(rb, 100);
if (err < 0) {
fprintf(stderr, "ERROR: ring_buffer__poll() err=%d\n", err);
break;
}
}
cleanup:
ring_buffer__free(rb);
bpf_xdp_detach(ifindex, XDP_FLAGS_DRV, NULL);
if (obj)
bpf_object__close(obj);
return 0;
}
INET_ADDRSTRLEN is defined in /include/linux/inet.h the kernel source code as 16 bytes which represents the maximum size, in bytes, of a string that can hold an IPv4 address in presentation format. inet_ntop function converts IPv4 and IPv6 addresses from binary to text and it’s a part of standard C library defined in arpa/inet.h and has the following prototype:
const char *inet_ntop(int af, const void *restrict src, char dst[restrict .size], socklen_t size);
AF_INET: Specifies the address family (IPv4).&md->src_ip: A pointer to the binary IPv4 address. src_str: The destination buffer where the converted string will be stored. sizeof(src_str): The size of the destination buffer.
Then the code uses a new approach by opening the object file directly instead of using a skeleton header file. The steps are as follows:
- open the eBPF object file.
- Load the eBPF program.
- Find XDP program by name which is
xdp_extract_metadataand load its file descriptor. - Attach the program to the interface.
- Look up the ringbuf map by name and load its file descriptor.
// Open BPF object file
obj = bpf_object__open_file("xdp_extract_metadata.o", NULL);
if (!obj) {
fprintf(stderr, "ERROR: bpf_object__open_file() failed\n");
return 1;
}
// Load (verify) BPF program
err = bpf_object__load(obj);
if (err) {
fprintf(stderr, "ERROR: bpf_object__load() failed %d\n", err);
goto cleanup;
}
// Find XDP program by name (we used "xdp_extract_metadata")
prog = bpf_object__find_program_by_name(obj, "xdp_extract_metadata");
if (!prog) {
fprintf(stderr, "ERROR: couldn't find xdp program in ELF\n");
goto cleanup;
}
prog_fd = bpf_program__fd(prog);
if (prog_fd < 0) {
fprintf(stderr, "ERROR: couldn't get file descriptor for XDP program\n");
goto cleanup;
}
// Attach the program to the interface (using driver mode as an example)
err = bpf_xdp_attach(ifindex, prog_fd, XDP_FLAGS_DRV, NULL);
if (err) {
fprintf(stderr, "ERROR: bpf_xdp_attach(ifindex=%d) failed (err=%d): %s\n",
ifindex, err, strerror(-err));
goto cleanup;
}
printf("Attached XDP program on ifindex %d\n", ifindex);
// Look up the ringbuf map by name or by index
map = bpf_object__find_map_by_name(obj, "ringbuf");
if (!map) {
fprintf(stderr, "ERROR: couldn't find ringbuf map in ELF\n");
goto cleanup;
}
map_fd = bpf_map__fd(map);
if (map_fd < 0) {
fprintf(stderr, "ERROR: couldn't get ringbuf map fd\n");
goto cleanup;
bpf_xdp_attach is a user-space API function (typically provided by libbpf) that attaches an XDP program to a network interface. defined in tools/lib/bpf/libbpf.h with the following prototype:
int bpf_xdp_attach(int ifindex, int prog_fd, __u32 flags, const struct bpf_xdp_attach_opts *opts);
ifindex: Represents the interface ID and ifindex is obtained by
ifindex = if_nametoindex(argv[1]);
prog_fd: Represents the program file descriptor.
flags: Can take one of three values and they are defined in include/uapi/linux/if_link.h as the following:
#define XDP_FLAGS_SKB_MODE (1U << 1)
#define XDP_FLAGS_DRV_MODE (1U << 2)
#define XDP_FLAGS_HW_MODE (1U << 3)
XDP_FLAGS_SKB_MODE (1U « 1): This flag attaches the XDP program in generic mode.
XDP_FLAGS_DRV_MODE (1U « 2): This flag attaches the XDP program in native driver mode.
XDP_FLAGS_HW_MODE (1U « 3): This flag is used for offloading the XDP program to supported hardware (NICs that support XDP offload).
Finally, the ring buffer is created, and the metadata is then polled from it. Compile the user-space using: clang -o loader loader.c -lbpf. Then, run the code using sudo ./loader enp1s0. Example output:
Attached XDP program on ifindex 2
Listening for events...
Packet: 192.168.1.1:53 -> 192.168.1.2:46313, protocol: UDP
Packet: 192.168.1.1:53 -> 192.168.1.2:46313, protocol: UDP
Packet: 82.65.248.56:123 -> 192.168.1.2:53121, protocol: UDP
Packet: 192.168.1.4:0 -> 192.168.1.2:0, protocol: ICMP
Packet: 192.168.1.4:0 -> 192.168.1.2:0, protocol: ICMP
Packet: 192.168.1.4:0 -> 192.168.1.2:0, protocol: ICMP
Packet: 192.168.1.3:35668 -> 192.168.1.2:22, protocol: TCP
Packet: 192.168.1.3:35668 -> 192.168.1.2:22, protocol: TCP
Packet: 192.168.1.3:35668 -> 192.168.1.2:22, protocol: TCP
Packet: 192.168.1.3:35668 -> 192.168.1.2:22, protocol: TCP
Packet: 192.168.1.3:35668 -> 192.168.1.2:22, protocol: TCP
Packet: 192.168.1.3:35668 -> 192.168.1.2:22, protocol: TCP
Packet: 192.168.1.3:35668 -> 192.168.1.2:22, protocol: TCP
5 - CGroup Socket Address
BPF_PROG_TYPE_CGROUP_SOCK_ADDR is a BPF program type designed to attach to control groups (cgroups) and intercept socket address operations, such as connect() calls. It enables administrators to enforce network connection policies—like allowing or blocking connections based on destination IPs and ports—at the cgroup level. This makes it a powerful tool for implementing network security controls within containerized or multi-tenant environments. There are many types of BPF_PROG_TYPE_CGROUP_SOCK_ADDR programs or ELF section such as:
- cgroup/bind4: Attaches to IPv4 bind operations. Programs in this section intercept bind() calls on IPv4 sockets, allowing you to control or modify how sockets bind to local addresses.
- cgroup/connect4: Attaches to IPv4 connect operations. This section is used to filter or modify outgoing connect() attempts on IPv4 sockets—for example, to allow only connections to certain destination addresses or ports.
- cgroup/recvmsg4: Attaches to IPv4 UDP receive message operations with eBPF attache type of
BPF_CGROUP_UDP4_RECVMSG. Programs in this section can intervene in recvmsg() calls on UDP sockets, enabling inspection or filtering of incoming datagrams. - cgroup/sendmsg4: Attaches to IPv4 UDP send message operations with eBPF attache type of
BPF_CGROUP_UDP4_SENDMSG. This section lets you apply filters or modifications to sendmsg() calls on UDP sockets, potentially controlling which messages are sent.
BPF_PROG_TYPE_CGROUP_SOCK_ADDR programs receive a pointer to a struct bpf_sock_addr as their context. This structure contains the socket’s address information (such as the destination IP and port, along with other details), which the BPF program can inspect or modify during operations like connect() or bind().
struct bpf_sock_addr is defined in include/uapi/linux/bpf.h:
struct bpf_sock_addr {
__u32 user_family;
__u32 user_ip4;
__u32 user_ip6[4];
__u32 user_port;
__u32 family;
__u32 type;
__u32 protocol;
__u32 msg_src_ip4;
__u32 msg_src_ip6[4];
__bpf_md_ptr(struct bpf_sock *, sk);
};
If we have a container connected to the internet without any policy.
BPF_PROG_TYPE_CGROUP_SOCK_ADDR eBPF can be used to make a policy and enforce it. For example, to only port 80 and attach it cgroup associated with that container.
eBPF program:
#include <linux/bpf.h>
#include <linux/in.h>
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_endian.h>
char _license[] SEC("license") = "GPL";
SEC("cgroup/connect4")
int cgroup_connect(struct bpf_sock_addr *ctx)
{
__u16 allowed_port = __bpf_htons(80);
if (ctx->user_port == allowed_port) {
return 1; //===> Allow connection
}
return 0; //===> Block connection
}
User-space code:
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <unistd.h>
#include <bpf/libbpf.h>
#include "cgroup_connect.skel.h"
int main(int argc, char **argv)
{
struct cgroup_connect *skel;
int cgroup_fd;
int err;
if (argc != 2) {
fprintf(stderr, "Usage: %s <cgroup_path>\n", argv[0]);
return EXIT_FAILURE;
}
cgroup_fd = open(argv[1], O_DIRECTORY | O_RDONLY);
if (cgroup_fd < 0) {
perror("Failed to open cgroup");
return EXIT_FAILURE;
}
skel = cgroup_connect__open();
if (!skel) {
fprintf(stderr, "Failed to open BPF skeleton\n");
close(cgroup_fd);
return EXIT_FAILURE;
}
err = cgroup_connect__load(skel);
if (err) {
fprintf(stderr, "Failed to load BPF skeleton: %d\n", err);
cgroup_connect__destroy(skel);
close(cgroup_fd);
return EXIT_FAILURE;
}
skel->links.cgroup_connect = bpf_program__attach_cgroup(skel->progs.cgroup_connect, cgroup_fd);
if (!skel->links.cgroup_connect) {
fprintf(stderr, "Failed to attach BPF program to cgroup\n");
cgroup_connect__destroy(skel);
close(cgroup_fd);
return EXIT_FAILURE;
}
printf("BPF program attached successfully to cgroup: %s\n", argv[1]);
while (1)
sleep(1);
cgroup_connect__destroy(skel);
close(cgroup_fd);
return EXIT_SUCCESS;
}
We have a container with name test.
docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
34ca63d499df debian:latest "/bin/bash" About an hour ago Up About an hour test
The container PID can be obtained using docker inspect -f '{{.State.Pid}}' test. Let’s get cgroup associated with that container using
cat /proc/3283/cgroup
0::/system.slice/docker-34ca63d499df1071c9d0512aafe7f4a1e73464edc6b40a9b97fdd087542d1930.scope
Then, we can link our eBPF program to our container using:
sudo ./loader /sys/fs/cgroup/system.slice/docker-34ca63d499df1071c9d0512aafe7f4a1e73464edc6b40a9b97fdd087542d1930.scope
The link can be tested to make sure that the policy is applied on our container. From inside our container
curl http://172.17.0.1:8080
curl: (7) Failed to connect to 172.17.0.1 port 8080 after 0 ms: Couldn't connect to server
In this chapter, we explored various networking capabilities in eBPF. We began with socket filter programs, demonstrating how they can detect specific traffic patterns and extract particular strings from network traffic—capabilities that are useful in security applications such as intrusion detection. Next, we examined Traffic Control (TC), which can manage both egress and ingress traffic, and we experimented with its features for firewalling and traffic manipulation. We then discussed Lightweight Tunnel applications, which can also serve as firewalls for tunneled traffic. Then, we explored XDP, which operates on ingress traffic, and tested its potential for firewalling, load balancing, and extracting packet metadata for analysis or logging. Finally, we discussed control group socket address, allows us to apply policies on a cgroup as we did earlier by attaching policies to a container’s cgroup. In the next chapter, we will dive deeper into eBPF security, exploring advanced techniques and strategies for enhancing system protection and monitoring using eBPF.