CGroup Socket Address
BPF_PROG_TYPE_CGROUP_SOCK_ADDR is a BPF program type designed to attach to control groups (cgroups) and intercept socket address operations, such as connect() calls. It enables administrators to enforce network connection policies—like allowing or blocking connections based on destination IPs and ports—at the cgroup level. This makes it a powerful tool for implementing network security controls within containerized or multi-tenant environments. There are many types of BPF_PROG_TYPE_CGROUP_SOCK_ADDR programs or ELF section such as:
- cgroup/bind4: Attaches to IPv4 bind operations. Programs in this section intercept bind() calls on IPv4 sockets, allowing you to control or modify how sockets bind to local addresses.
- cgroup/connect4: Attaches to IPv4 connect operations. This section is used to filter or modify outgoing connect() attempts on IPv4 sockets—for example, to allow only connections to certain destination addresses or ports.
- cgroup/recvmsg4: Attaches to IPv4 UDP receive message operations with eBPF attache type of
BPF_CGROUP_UDP4_RECVMSG. Programs in this section can intervene in recvmsg() calls on UDP sockets, enabling inspection or filtering of incoming datagrams. - cgroup/sendmsg4: Attaches to IPv4 UDP send message operations with eBPF attache type of
BPF_CGROUP_UDP4_SENDMSG. This section lets you apply filters or modifications to sendmsg() calls on UDP sockets, potentially controlling which messages are sent.
BPF_PROG_TYPE_CGROUP_SOCK_ADDR programs receive a pointer to a struct bpf_sock_addr as their context. This structure contains the socket’s address information (such as the destination IP and port, along with other details), which the BPF program can inspect or modify during operations like connect() or bind().
struct bpf_sock_addr is defined in include/uapi/linux/bpf.h:
struct bpf_sock_addr {
__u32 user_family;
__u32 user_ip4;
__u32 user_ip6[4];
__u32 user_port;
__u32 family;
__u32 type;
__u32 protocol;
__u32 msg_src_ip4;
__u32 msg_src_ip6[4];
__bpf_md_ptr(struct bpf_sock *, sk);
};
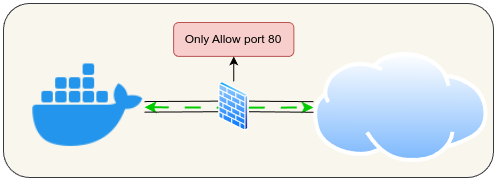
If we have a container connected to the internet without any policy.
BPF_PROG_TYPE_CGROUP_SOCK_ADDR eBPF can be used to make a policy and enforce it. For example, to only port 80 and attach it cgroup associated with that container.
eBPF program:
#include <linux/bpf.h>
#include <linux/in.h>
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_endian.h>
char _license[] SEC("license") = "GPL";
SEC("cgroup/connect4")
int cgroup_connect(struct bpf_sock_addr *ctx)
{
__u16 allowed_port = __bpf_htons(80);
if (ctx->user_port == allowed_port) {
return 1; //===> Allow connection
}
return 0; //===> Block connection
}
User-space code:
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <unistd.h>
#include <bpf/libbpf.h>
#include "cgroup_connect.skel.h"
int main(int argc, char **argv)
{
struct cgroup_connect *skel;
int cgroup_fd;
int err;
if (argc != 2) {
fprintf(stderr, "Usage: %s <cgroup_path>\n", argv[0]);
return EXIT_FAILURE;
}
cgroup_fd = open(argv[1], O_DIRECTORY | O_RDONLY);
if (cgroup_fd < 0) {
perror("Failed to open cgroup");
return EXIT_FAILURE;
}
skel = cgroup_connect__open();
if (!skel) {
fprintf(stderr, "Failed to open BPF skeleton\n");
close(cgroup_fd);
return EXIT_FAILURE;
}
err = cgroup_connect__load(skel);
if (err) {
fprintf(stderr, "Failed to load BPF skeleton: %d\n", err);
cgroup_connect__destroy(skel);
close(cgroup_fd);
return EXIT_FAILURE;
}
skel->links.cgroup_connect = bpf_program__attach_cgroup(skel->progs.cgroup_connect, cgroup_fd);
if (!skel->links.cgroup_connect) {
fprintf(stderr, "Failed to attach BPF program to cgroup\n");
cgroup_connect__destroy(skel);
close(cgroup_fd);
return EXIT_FAILURE;
}
printf("BPF program attached successfully to cgroup: %s\n", argv[1]);
while (1)
sleep(1);
cgroup_connect__destroy(skel);
close(cgroup_fd);
return EXIT_SUCCESS;
}
We have a container with name test.
docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
34ca63d499df debian:latest "/bin/bash" About an hour ago Up About an hour test
The container PID can be obtained using docker inspect -f '{{.State.Pid}}' test. Let’s get cgroup associated with that container using
cat /proc/3283/cgroup
0::/system.slice/docker-34ca63d499df1071c9d0512aafe7f4a1e73464edc6b40a9b97fdd087542d1930.scope
Then, we can link our eBPF program to our container using:
sudo ./loader /sys/fs/cgroup/system.slice/docker-34ca63d499df1071c9d0512aafe7f4a1e73464edc6b40a9b97fdd087542d1930.scope
The link can be tested to make sure that the policy is applied on our container. From inside our container
curl http://172.17.0.1:8080
curl: (7) Failed to connect to 172.17.0.1 port 8080 after 0 ms: Couldn't connect to server
In this chapter, we explored various networking capabilities in eBPF. We began with socket filter programs, demonstrating how they can detect specific traffic patterns and extract particular strings from network traffic—capabilities that are useful in security applications such as intrusion detection. Next, we examined Traffic Control (TC), which can manage both egress and ingress traffic, and we experimented with its features for firewalling and traffic manipulation. We then discussed Lightweight Tunnel applications, which can also serve as firewalls for tunneled traffic. Then, we explored XDP, which operates on ingress traffic, and tested its potential for firewalling, load balancing, and extracting packet metadata for analysis or logging. Finally, we discussed control group socket address, allows us to apply policies on a cgroup as we did earlier by attaching policies to a container’s cgroup. In the next chapter, we will dive deeper into eBPF security, exploring advanced techniques and strategies for enhancing system protection and monitoring using eBPF.