XDP
XDP (eXpress Data Path) is a high-performance packet processing framework integrated directly into the Linux kernel. It leverages eBPF (extended Berkeley Packet Filter) technology to enable customizable packet processing at the earliest possible stage when packets arrive at the network driver (ingress traffic) before the kernel allocates an sk_buff for them. By operating before the kernel’s traditional networking stack processes packets, XDP dramatically reduces latency, improves throughput, and minimizes processing overhead. One of the core reasons XDP achieves such high efficiency is by avoiding traditional kernel operations, such as allocation of the socket buffer structure (sk_buff) or generic receive offload (GRO), which are expensive and unnecessary at this early stage. Unlike traditional Linux networking, XDP does not require packets to be wrapped into the kernel’s socket buffer (sk_buff). The sk_buff structure, while powerful and flexible, is relatively heavyweight and incurs significant performance costs because of the extensive metadata and management overhead it introduces. By bypassing the sk_buff, XDP can directly manipulate raw packet data significantly boosting packet processing performance. Additionally, XDP provides the capability for atomic runtime updates to its programs, offering significant operational flexibility without traffic disruption.
Note
GRO (Generic Receive Offload) is a Linux kernel feature which aggregates multiple incoming network packets into fewer larger packets before passing them up the kernel networking stack to reduces per-packet processing overhead.Each packet processed by XDP is represented by a special context structure called xdp_buff. The primary difference between the xdp_buff and traditional sk_buff is related to the processing stage and the complexity of these structures. The xdp_buff is significantly simpler and is employed much earlier in the packet-processing pipeline. XDP programs are classified as BPF_PROG_TYPE_XDP and it used xdp_buff structure which is defined in include/net/xdp.h as the following:
struct xdp_buff {
void *data;
void *data_end;
void *data_meta;
void *data_hard_start;
struct xdp_rxq_info *rxq;
struct xdp_txq_info *txq;
u32 frame_sz;
u32 flags;
};
XDP operates in three distinct modes that suit different scenarios: native XDP, offloaded XDP and generic XDP.
Native XDP is the default and most performant mode, running directly within network driver. It delivers optimal efficiency and minimal latency, supported broadly across modern NICs. Offloaded XDP leverages specialized hardware (SmartNICs) by executing XDP programs directly on NIC hardware, freeing CPU resources and pushing performance even higher, ideal for demanding high-throughput scenarios. Generic XDP is available when native support isn’t present. It executes within the kernel’s networking stack rather than the NIC driver, primarily useful for development and testing but provides lower performance due to the additional overhead.
An XDP program uses return codes which are defined in include/uapi/linux/bpf.h header file as the following:
enum xdp_action {
XDP_ABORTED = 0,
XDP_DROP,
XDP_PASS,
XDP_TX,
XDP_REDIRECT,
};
These return codes are used to instruct the network driver on how to handle incoming packets. The return codes are as follows:
XDP_DROP: Immediately drops packets at the NIC driver, ideal for quick, resource-efficient firewalling and DDoS mitigation.XDP_PASS: Forwards the packet to the kernel’s regular network stack.XDP_TX: Sends the packet back out of the same NIC it arrived on, often used in load balancing and packet rewriting scenarios.XDP_REDIRECT: Sends the packet out through a different NIC or redirects it to a different processing CPU.XDP_ABORTED: Signifies an error condition, useful during debugging and development.
The following diagram shows the basic XDP workflow:
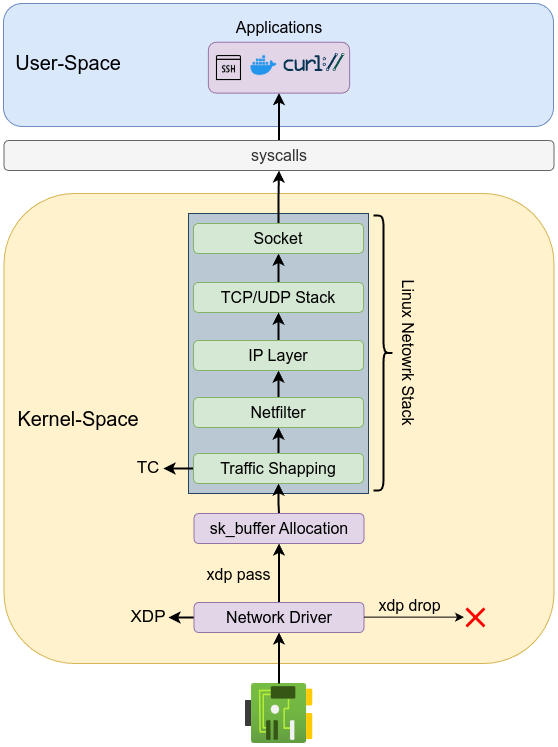
One common use case of XDP is DDoS mitigation, where it quickly identifies and drops malicious traffic with minimal processing overhead. XDP is also heavily used for advanced packet forwarding and load balancing, enabling quick header modifications and packet routing decisions directly at the driver level. Network analytics and sampling are other powerful XDP applications, where packet data can be efficiently captured and transmitted to user-space applications through memory-mapped ring buffers. Custom protocol handling, such as encapsulation or decapsulation, is easily achievable with XDP, facilitating efficient interactions with upper-layer network functions such as the GRO engine. Real-world deployments by companies like Facebook (Katran) and Cloudflare have demonstrated substantial performance improvements by integrating XDP for load balancing, firewalling, and DDoS mitigation. For more details please visit Cilium’s documentation.
The next example is explained previously. The following code performs a chain of checks to drop port 8080 on ingress traffic using XDP_DROP. The code uses xdp_md as context instead of sk_buff as previously explained.
#include <linux/bpf.h>
#include <linux/if_ether.h>
#include <linux/ip.h>
#include <linux/tcp.h>
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_endian.h>
#include <linux/in.h>
char _license[] SEC("license") = "GPL";
SEC("xdp")
int drop_ingress_port_8080(struct xdp_md *ctx) {
void *data = (void *)(long)ctx->data;
void *data_end = (void *)(long)ctx->data_end;
struct ethhdr *eth = data;
if ((void *)eth + sizeof(*eth) > data_end)
return XDP_PASS;
if (bpf_ntohs(eth->h_proto) != ETH_P_IP)
return XDP_PASS;
struct iphdr *iph = data + sizeof(*eth);
if ((void *)iph + sizeof(*iph) > data_end)
return XDP_PASS;
if (iph->protocol != IPPROTO_TCP)
return XDP_PASS;
int ip_header_length = iph->ihl * 4;
struct tcphdr *tcph = data + sizeof(*eth) + ip_header_length;
if ((void *)tcph + sizeof(*tcph) > data_end)
return XDP_PASS;
if (bpf_ntohs(tcph->dest) == 8080) {
bpf_printk("Dropping XDP egress packet port 8080\n");
return XDP_DROP;
}
return XDP_PASS;
}
Compile the code using LLVM then load it with: sudo ip link set dev enp1s0 xdp obj xdp_drop_8080.o sec xdp.
Note
xdp obj xdp_drop_8080.o This command loads an XDP program from the ELF object file named xdp_drop_8080.o. By default, the system attempts to use native driver mode if available, falling back to generic mode otherwise. You can also force a specific mode by using one of these options: xdpgeneric: Enforce generic XDP mode.
xdpdrv: Enforce native driver XDP mode. xdpoffload: Enforce offloaded XDP mode for supported hardware. For example,sudo ip link set dev enp1s0 xdpgeneric obj x.o sec xdp will enforce generic XDP mode. To unload the XDP program, run: sudo ip link set dev enp1s0 xdp off.
As we mentioned earlier, XDP can operate as an efficient load balancer. In the following example, we have an ICMP load balancer implemented using a round-robin approach connected to two backend servers. When load balancer receives ICMP echo request will dispatch it to the servers in order. The idea behind this load balancer is that it routes by re-writing the destination IP, delivering each request to the backend servers in sequential.
Note
A round-robin load balancer distributes network traffic evenly across a group of servers by sequentially forwarding each new request to the next server in a rotating list.The IP header checksum must be recalculated, RFC 1071 explaining in details how IP header checksum, but to simplify the process it has two steps: one’s complement addition and folding process. bpf_csum_diff helper function to calculate a checksum difference from the raw buffer pointed by from, of length from_size (that must be a multiple of 4), towards the raw buffer pointed by to, of size to_size (that must be a multiple of 4) and which has the following prototype:
static __s64 (* const bpf_csum_diff)(__be32 *from, __u32 from_size, __be32 *to, __u32 to_size, __wsum seed) = (void *) 28;
In this example, the XPD ICMP load balancer is configured on IP address 192.168.1.2. It has two backend servers: the first backend server has IP address 192.168.1.3 with MAC address 52:54:00:ff:ff:55, and the second backend server has IP address 192.168.1.4 with MAC address 52:54:00:5d:6e:a1. When an ICMP Echo Request reaches the load balancer, it will redirect the first request to the first backend server and the second Echo Request to the second backend server.
#include <linux/bpf.h>
#include <linux/if_ether.h>
#include <linux/ip.h>
#include <linux/in.h>
#include <linux/icmp.h>
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_endian.h>
#define LB_IP __constant_htonl(0xC0A87AEE) /* 192.168.1.2 */
char _license[] SEC("license") = "GPL";
struct backend {
__u32 ip;
unsigned char mac[ETH_ALEN];
};
struct {
__uint(type, BPF_MAP_TYPE_ARRAY);
__uint(max_entries, 1);
__type(key, __u32);
__type(value, __u32);
} rr_map SEC(".maps");
struct {
__uint(type, BPF_MAP_TYPE_ARRAY);
__uint(max_entries, 2);
__type(key, __u32);
__type(value, struct backend);
} backend_map SEC(".maps");
static __always_inline __u16 ip_recalc_csum(struct iphdr *iph)
{
iph->check = 0;
unsigned int csum = bpf_csum_diff(0, 0, (unsigned int *)iph, sizeof(*iph), 0);
for (int i = 0; i < 4; i++) {
if (csum >> 16)
csum = (csum & 0xffff) + (csum >> 16);
}
return ~csum;
}
SEC("xdp")
int icmp_lb(struct xdp_md *ctx)
{
void *data = (void *)(long)ctx->data;
void *data_end = (void *)(long)ctx->data_end;
struct ethhdr *eth = data;
if ((void*)(eth + 1) > data_end)
return XDP_PASS;
if (eth->h_proto != bpf_htons(ETH_P_IP))
return XDP_PASS;
struct iphdr *iph = data + sizeof(*eth);
if ((void*)(iph + 1) > data_end)
return XDP_PASS;
if (iph->daddr != LB_IP)
return XDP_PASS;
if (iph->protocol != IPPROTO_ICMP)
return XDP_PASS;
__u32 bk = 0;
struct backend *b_ptr = bpf_map_lookup_elem(&backend_map, &bk);
if (b_ptr && b_ptr->ip == 0) {
struct backend be0 = {
.ip = __constant_htonl(0xC0A87A58),
.mac = {0x52, 0x54, 0x00, 0xff, 0xff, 0x55}
};
bpf_map_update_elem(&backend_map, &bk, &be0, BPF_ANY);
bk = 1;
struct backend be1 = {
.ip = __constant_htonl(0xC0A87AD7),
.mac = {0x52, 0x54, 0x00, 0x5d, 0x6e, 0xa1}
};
bpf_map_update_elem(&backend_map, &bk, &be1, BPF_ANY);
}
__u32 rr_key = 0;
__u32 *p_index = bpf_map_lookup_elem(&rr_map, &rr_key);
if (!p_index)
return XDP_PASS;
__u32 index = *p_index;
*p_index = (index + 1) % 2;
__u32 backend_key = index;
struct backend *be = bpf_map_lookup_elem(&backend_map, &backend_key);
if (!be)
return XDP_PASS;
iph->daddr = be->ip;
iph->check = ip_recalc_csum(iph);
__builtin_memcpy(eth->h_dest, be->mac, ETH_ALEN);
return XDP_TX;
}
First, structure was define for backends’ IPs unsigned 32-bit integer and MAC addresses with ETH_ALEN of length which is 6 as defined in include/linux/if_ether.h. Second, define a map of type BPF_MAP_TYPE_ARRAY to track the state of our round-robin load balancer with only one entry and key 0 should be initialized to 0. Third, define a map of type BPF_MAP_TYPE_ARRAY to store backends’ IPs and MAC addresses and key 0 should be initialized to 0.
struct backend {
__u32 ip;
unsigned char mac[ETH_ALEN];
};
struct {
__uint(type, BPF_MAP_TYPE_ARRAY);
__uint(max_entries, 1);
__type(key, __u32);
__type(value, __u32);
} rr_map SEC(".maps");
struct {
__uint(type, BPF_MAP_TYPE_ARRAY);
__uint(max_entries, 2);
__type(key, __u32);
__type(value, struct backend);
} backend_map SEC(".maps");
Then, the code performs chain of checks to ensure that the code is only process ICMP packets.
/* Parse Ethernet header */
struct ethhdr *eth = data;
if ((void*)(eth + 1) > data_end)
return XDP_PASS;
if (eth->h_proto != bpf_htons(ETH_P_IP))
return XDP_PASS;
/* Parse IP header */
struct iphdr *iph = data + sizeof(*eth);
if ((void*)(iph + 1) > data_end)
return XDP_PASS;
/* Process only packets destined to LB_IP */
if (iph->daddr != LB_IP)
return XDP_PASS;
/* Process only ICMP packets */
if (iph->protocol != IPPROTO_ICMP)
return XDP_PASS;
Next, the code populates the backend_map with backend information and selects a backend using round-robin from the rr_map.
__u32 bk = 0;
struct backend *b_ptr = bpf_map_lookup_elem(&backend_map, &bk);
if (b_ptr && b_ptr->ip == 0) {
struct backend be0 = {
.ip = __constant_htonl(0xC0A87A58),
.mac = {0x52, 0x54, 0x00, 0xff, 0xff, 0x55}
};
bpf_map_update_elem(&backend_map, &bk, &be0, BPF_ANY);
bk = 1;
struct backend be1 = {
.ip = __constant_htonl(0xC0A87AD7),
.mac = {0x52, 0x54, 0x00, 0x5d, 0x6e, 0xa1}
};
bpf_map_update_elem(&backend_map, &bk, &be1, BPF_ANY);
}
__u32 rr_key = 0;
__u32 *p_index = bpf_map_lookup_elem(&rr_map, &rr_key);
if (!p_index)
return XDP_PASS;
__u32 index = *p_index;
*p_index = (index + 1) % 2;
__u32 backend_key = index;
struct backend *be = bpf_map_lookup_elem(&backend_map, &backend_key);
Then, the code rewrites the destination IP address to the chosen backend from round-robin map followed by the calculation of the IP header checksum using the following:
static __always_inline __u16 ip_recalc_csum(struct iphdr *iph)
{
iph->check = 0;
unsigned int csum = bpf_csum_diff(0, 0, (unsigned int *)iph, sizeof(*iph), 0);
for (int i = 0; i < 4; i++) {
if (csum >> 16)
csum = (csum & 0xffff) + (csum >> 16);
}
return ~csum;
}
In short, the checksum is calculated by summing all the 16-bit words of the header using one’s complement arithmetic. “Folding” means that if the sum exceeds 16 bits, any overflow (carry) from the high-order bits is added back into the lower 16 bits. Finally, the one’s complement (bitwise NOT) of that folded sum gives the checksum.
As we mentioned before,bpf_csum_diff helper function with seed of zero performs one’s complement addition. Next, the folding process which has the following in one of four iteration:
- Check that right shift by 16 bits
csum >> 16(discards the lower 4 hex digits) ofbpf_csum_diffoutput is nonzero. - Extract the lower 16 bits from the output of
bpf_csum_diffusing a bitwise AND with0xFFFF. - Shift the current checksum value right by 16 bits to extract any carry beyond the lower 16 bits, then add that carry to the lower 16 bits (obtained with
csum & 0xffff), and store the result incsum. - Repeat this process (up to 4 iterations) until no carry remains, then return the bitwise NOT of the final result.
The final step in the code is to set destination MAC address to the chosen backend’s MAC address using__builtin_memcpy. __builtin_memcpy is not a standard C library function; it’s a compiler-provided function that offers optimized memory copying and has the following prototype:
void *__builtin_memcpy(void *dest, const void *src, size_t size);
Compile the code. Then, attach the XDP program to your interface sudo ip link set dev enp1s0 xdp obj icmp_lb.o sec xdp. Next, capture ICMP traffic on both backend using sudo tcpdump -i enp1s0 icmp, then from fourth machine, send Echo request to the load balancer ping 192.168.1.2
PING 192.168.1.2 (192.168.122.238) 56(84) bytes of data.
64 bytes from 192.168.1.3: icmp_seq=1 ttl=64 time=0.442 ms (DIFFERENT ADDRESS!)
64 bytes from 192.168.1.4: icmp_seq=2 ttl=64 time=0.667 ms (DIFFERENT ADDRESS!)
64 bytes from 192.168.1.3: icmp_seq=3 ttl=64 time=0.713 ms (DIFFERENT ADDRESS!)
64 bytes from 192.168.1.4: icmp_seq=4 ttl=64 time=0.670 ms (DIFFERENT ADDRESS!)
64 bytes from 192.168.1.3: icmp_seq=5 ttl=64 time=0.570 ms (DIFFERENT ADDRESS!)
64 bytes from 192.168.1.4: icmp_seq=6 ttl=64 time=0.647 ms (DIFFERENT ADDRESS!)
64 bytes from 192.168.1.3: icmp_seq=7 ttl=64 time=0.715 ms (DIFFERENT ADDRESS!)
64 bytes from 192.168.1.4: icmp_seq=8 ttl=64 time=0.715 ms (DIFFERENT ADDRESS!)
tcpdumpfrom the first backend:
05:14:35.264928 IP _gateway > test1-Standard-PC-Q35-ICH9-2009: ICMP echo request, id 16, seq 1, length 64
05:14:35.264969 IP test1-Standard-PC-Q35-ICH9-2009 > _gateway: ICMP echo reply, id 16, seq 1, length 64
05:14:37.321642 IP _gateway > test1-Standard-PC-Q35-ICH9-2009: ICMP echo request, id 16, seq 3, length 64
05:14:37.321694 IP test1-Standard-PC-Q35-ICH9-2009 > _gateway: ICMP echo reply, id 16, seq 3, length 64
05:14:39.370002 IP _gateway > test1-Standard-PC-Q35-ICH9-2009: ICMP echo request, id 16, seq 5, length 64
05:14:39.370068 IP test1-Standard-PC-Q35-ICH9-2009 > _gateway: ICMP echo reply, id 16, seq 5, length 64
05:14:41.417230 IP _gateway > test1-Standard-PC-Q35-ICH9-2009: ICMP echo request, id 16, seq 7, length 64
05:14:41.417282 IP test1-Standard-PC-Q35-ICH9-2009 > _gateway: ICMP echo reply, id 16, seq 7, length 64
tcpdumpfrom the second backend:
05:14:36.273275 IP _gateway > test2-Standard-PC-Q35-ICH9-2009: ICMP echo request, id 16, seq 2, length 64
05:14:36.273355 IP test2-Standard-PC-Q35-ICH9-2009 > _gateway: ICMP echo reply, id 16, seq 2, length 64
05:14:38.320876 IP _gateway > test2-Standard-PC-Q35-ICH9-2009: ICMP echo request, id 16, seq 4, length 64
05:14:38.320933 IP test2-Standard-PC-Q35-ICH9-2009 > _gateway: ICMP echo reply, id 16, seq 4, length 64
05:14:40.368579 IP _gateway > test2-Standard-PC-Q35-ICH9-2009: ICMP echo request, id 16, seq 6, length 64
05:14:40.368632 IP test2-Standard-PC-Q35-ICH9-2009 > _gateway: ICMP echo reply, id 16, seq 6, length 64
05:14:42.420358 IP _gateway > test2-Standard-PC-Q35-ICH9-2009: ICMP echo request, id 16, seq 8, length 64
05:14:42.420406 IP test2-Standard-PC-Q35-ICH9-2009 > _gateway: ICMP echo reply, id 16, seq 8, length 64
Notice the sequence of ICMP packets: each Echo request is sent to a different backend server. XDP can also be used to extract metadata from packets which can then be sent to network analysis tool for further investigation, stored for logging as a flight record, or used to assist in incident investigation.
The following example extracts metadata of ingress traffic (source IP, source port, destination IP, destination port and protocol) and send the extracted metadata to ring buffer that can be accessed from user space.
#include <linux/bpf.h>
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_endian.h>
#include <linux/if_ether.h>
#include <linux/ip.h>
#include <linux/udp.h>
#include <linux/tcp.h>
#include <linux/in.h>
char _license[] SEC("license") = "GPL";
struct metadata_t {
__u32 src_ip;
__u32 dst_ip;
__u16 src_port;
__u16 dst_port;
__u8 protocol;
};
struct {
__uint(type, BPF_MAP_TYPE_RINGBUF);
__uint(max_entries, 1 << 24);
__uint(map_flags, 0);
} ringbuf SEC(".maps");
SEC("xdp")
int xdp_extract_metadata(struct xdp_md *ctx)
{
void *data_end = (void *)(long)ctx->data_end;
void *data = (void *)(long)ctx->data;
struct ethhdr *eth = data;
if ((void *)(eth + 1) > data_end)
return XDP_PASS;
if (bpf_ntohs(eth->h_proto) != ETH_P_IP)
return XDP_PASS;
struct iphdr *iph = (void *)(eth + 1);
if ((void *)(iph + 1) > data_end)
return XDP_PASS;
__u16 src_port = 0;
__u16 dst_port = 0;
if (iph->protocol == IPPROTO_TCP || iph->protocol == IPPROTO_UDP) {
__u64 ip_header_size = iph->ihl * 4;
__u64 offset = sizeof(*eth) + ip_header_size;
if (offset + sizeof(struct udphdr) > (unsigned long)(data_end - data))
return XDP_PASS;
struct udphdr *uh = data + offset;
if ((void *)(uh + 1) > data_end)
return XDP_PASS;
src_port = uh->source;
dst_port = uh->dest;
}
struct metadata_t *meta = bpf_ringbuf_reserve(&ringbuf, sizeof(*meta), 0);
if (!meta)
return XDP_PASS;
meta->src_ip = iph->saddr;
meta->dst_ip = iph->daddr;
meta->src_port = src_port;
meta->dst_port = dst_port;
meta->protocol = iph->protocol;
bpf_ringbuf_submit(meta, 0);
return XDP_PASS;
}
The code performs chain of checks to extract ports for TCP or UDP, for other protocols, leave ports as 0.
__u16 src_port = 0;
__u16 dst_port = 0;
if (iph->protocol == IPPROTO_TCP || iph->protocol == IPPROTO_UDP) {
__u64 ip_header_size = iph->ihl * 4ULL;
__u64 offset = sizeof(*eth) + ip_header_size;
if (offset + sizeof(struct udphdr) > (unsigned long)(data_end - data))
return XDP_PASS;
struct udphdr *uh = data + offset;
if ((void *)(uh + 1) > data_end)
return XDP_PASS;
src_port = uh->source;
dst_port = uh->dest;
}
Then fill out the metadata event
meta->src_ip = iph->saddr;
meta->dst_ip = iph->daddr;
meta->src_port = src_port;
meta->dst_port = dst_port;
meta->protocol = iph->protocol;
Finally, submit the metadata to the ring buffer. The following user-space program loads the XDP object file, attaches it to the required interface, and retrieves metadata from the ring buffer.
#include <stdio.h>
#include <stdlib.h>
#include <signal.h>
#include <unistd.h>
#include <arpa/inet.h>
#include <string.h>
#include <net/if.h>
#include <errno.h>
#include <linux/if_link.h>
#include <bpf/libbpf.h>
#include <bpf/bpf.h>
#include <netinet/in.h>
#ifndef XDP_FLAGS_DRV
#define XDP_FLAGS_DRV (1U << 0)
#endif
struct metadata_t {
__u32 src_ip;
__u32 dst_ip;
__u16 src_port;
__u16 dst_port;
__u8 protocol;
};
static int handle_event(void *ctx, void *data, size_t data_sz)
{
if (data_sz < sizeof(struct metadata_t)) {
fprintf(stderr, "Ring buffer event too small\n");
return 0;
}
struct metadata_t *md = data;
char src_str[INET_ADDRSTRLEN];
char dst_str[INET_ADDRSTRLEN];
inet_ntop(AF_INET, &md->src_ip, src_str, sizeof(src_str));
inet_ntop(AF_INET, &md->dst_ip, dst_str, sizeof(dst_str));
const char *proto_name;
switch (md->protocol) {
case IPPROTO_TCP:
proto_name = "TCP";
break;
case IPPROTO_UDP:
proto_name = "UDP";
break;
case IPPROTO_ICMP:
proto_name = "ICMP";
break;
default:
proto_name = "UNKNOWN";
break;
}
printf("Packet: %s:%u -> %s:%u, protocol: %s\n",
src_str, ntohs(md->src_port),
dst_str, ntohs(md->dst_port),
proto_name);
return 0;
}
int main(int argc, char **argv)
{
struct bpf_object *obj = NULL;
struct bpf_program *prog = NULL;
struct bpf_map *map = NULL;
struct ring_buffer *rb = NULL;
int prog_fd, map_fd, err, ifindex;
char pin_path[256];
if (argc < 2) {
fprintf(stderr, "Usage: %s <ifname>\n", argv[0]);
return 1;
}
ifindex = if_nametoindex(argv[1]);
if (!ifindex) {
fprintf(stderr, "Invalid interface name: %s\n", argv[1]);
return 1;
}
libbpf_set_strict_mode(LIBBPF_STRICT_ALL);
obj = bpf_object__open_file("xdp_extract_metadata.o", NULL);
if (!obj) {
fprintf(stderr, "ERROR: bpf_object__open_file() failed\n");
return 1;
}
err = bpf_object__load(obj);
if (err) {
fprintf(stderr, "ERROR: bpf_object__load() failed %d\n", err);
goto cleanup;
}
prog = bpf_object__find_program_by_name(obj, "xdp_extract_metadata");
if (!prog) {
fprintf(stderr, "ERROR: couldn't find xdp program in ELF\n");
goto cleanup;
}
prog_fd = bpf_program__fd(prog);
if (prog_fd < 0) {
fprintf(stderr, "ERROR: couldn't get file descriptor for XDP program\n");
goto cleanup;
}
err = bpf_xdp_attach(ifindex, prog_fd, XDP_FLAGS_DRV, NULL);
if (err) {
fprintf(stderr, "ERROR: bpf_xdp_attach(ifindex=%d) failed (err=%d): %s\n",
ifindex, err, strerror(-err));
goto cleanup;
}
printf("Attached XDP program on ifindex %d\n", ifindex);
map = bpf_object__find_map_by_name(obj, "ringbuf");
if (!map) {
fprintf(stderr, "ERROR: couldn't find ringbuf map in ELF\n");
goto cleanup;
}
map_fd = bpf_map__fd(map);
if (map_fd < 0) {
fprintf(stderr, "ERROR: couldn't get ringbuf map fd\n");
goto cleanup;
}
rb = ring_buffer__new(map_fd, handle_event, NULL, NULL);
if (!rb) {
fprintf(stderr, "ERROR: ring_buffer__new() failed\n");
goto cleanup;
}
printf("Listening for events...\n");
while (1) {
err = ring_buffer__poll(rb, 100);
if (err < 0) {
fprintf(stderr, "ERROR: ring_buffer__poll() err=%d\n", err);
break;
}
}
cleanup:
ring_buffer__free(rb);
bpf_xdp_detach(ifindex, XDP_FLAGS_DRV, NULL);
if (obj)
bpf_object__close(obj);
return 0;
}
INET_ADDRSTRLEN is defined in /include/linux/inet.h the kernel source code as 16 bytes which represents the maximum size, in bytes, of a string that can hold an IPv4 address in presentation format. inet_ntop function converts IPv4 and IPv6 addresses from binary to text and it’s a part of standard C library defined in arpa/inet.h and has the following prototype:
const char *inet_ntop(int af, const void *restrict src, char dst[restrict .size], socklen_t size);
AF_INET: Specifies the address family (IPv4).&md->src_ip: A pointer to the binary IPv4 address. src_str: The destination buffer where the converted string will be stored. sizeof(src_str): The size of the destination buffer.
Then the code uses a new approach by opening the object file directly instead of using a skeleton header file. The steps are as follows:
- open the eBPF object file.
- Load the eBPF program.
- Find XDP program by name which is
xdp_extract_metadataand load its file descriptor. - Attach the program to the interface.
- Look up the ringbuf map by name and load its file descriptor.
// Open BPF object file
obj = bpf_object__open_file("xdp_extract_metadata.o", NULL);
if (!obj) {
fprintf(stderr, "ERROR: bpf_object__open_file() failed\n");
return 1;
}
// Load (verify) BPF program
err = bpf_object__load(obj);
if (err) {
fprintf(stderr, "ERROR: bpf_object__load() failed %d\n", err);
goto cleanup;
}
// Find XDP program by name (we used "xdp_extract_metadata")
prog = bpf_object__find_program_by_name(obj, "xdp_extract_metadata");
if (!prog) {
fprintf(stderr, "ERROR: couldn't find xdp program in ELF\n");
goto cleanup;
}
prog_fd = bpf_program__fd(prog);
if (prog_fd < 0) {
fprintf(stderr, "ERROR: couldn't get file descriptor for XDP program\n");
goto cleanup;
}
// Attach the program to the interface (using driver mode as an example)
err = bpf_xdp_attach(ifindex, prog_fd, XDP_FLAGS_DRV, NULL);
if (err) {
fprintf(stderr, "ERROR: bpf_xdp_attach(ifindex=%d) failed (err=%d): %s\n",
ifindex, err, strerror(-err));
goto cleanup;
}
printf("Attached XDP program on ifindex %d\n", ifindex);
// Look up the ringbuf map by name or by index
map = bpf_object__find_map_by_name(obj, "ringbuf");
if (!map) {
fprintf(stderr, "ERROR: couldn't find ringbuf map in ELF\n");
goto cleanup;
}
map_fd = bpf_map__fd(map);
if (map_fd < 0) {
fprintf(stderr, "ERROR: couldn't get ringbuf map fd\n");
goto cleanup;
bpf_xdp_attach is a user-space API function (typically provided by libbpf) that attaches an XDP program to a network interface. defined in tools/lib/bpf/libbpf.h with the following prototype:
int bpf_xdp_attach(int ifindex, int prog_fd, __u32 flags, const struct bpf_xdp_attach_opts *opts);
ifindex: Represents the interface ID and ifindex is obtained by
ifindex = if_nametoindex(argv[1]);
prog_fd: Represents the program file descriptor.
flags: Can take one of three values and they are defined in include/uapi/linux/if_link.h as the following:
#define XDP_FLAGS_SKB_MODE (1U << 1)
#define XDP_FLAGS_DRV_MODE (1U << 2)
#define XDP_FLAGS_HW_MODE (1U << 3)
XDP_FLAGS_SKB_MODE (1U « 1): This flag attaches the XDP program in generic mode.
XDP_FLAGS_DRV_MODE (1U « 2): This flag attaches the XDP program in native driver mode.
XDP_FLAGS_HW_MODE (1U « 3): This flag is used for offloading the XDP program to supported hardware (NICs that support XDP offload).
Finally, the ring buffer is created, and the metadata is then polled from it. Compile the user-space using: clang -o loader loader.c -lbpf. Then, run the code using sudo ./loader enp1s0. Example output:
Attached XDP program on ifindex 2
Listening for events...
Packet: 192.168.1.1:53 -> 192.168.1.2:46313, protocol: UDP
Packet: 192.168.1.1:53 -> 192.168.1.2:46313, protocol: UDP
Packet: 82.65.248.56:123 -> 192.168.1.2:53121, protocol: UDP
Packet: 192.168.1.4:0 -> 192.168.1.2:0, protocol: ICMP
Packet: 192.168.1.4:0 -> 192.168.1.2:0, protocol: ICMP
Packet: 192.168.1.4:0 -> 192.168.1.2:0, protocol: ICMP
Packet: 192.168.1.3:35668 -> 192.168.1.2:22, protocol: TCP
Packet: 192.168.1.3:35668 -> 192.168.1.2:22, protocol: TCP
Packet: 192.168.1.3:35668 -> 192.168.1.2:22, protocol: TCP
Packet: 192.168.1.3:35668 -> 192.168.1.2:22, protocol: TCP
Packet: 192.168.1.3:35668 -> 192.168.1.2:22, protocol: TCP
Packet: 192.168.1.3:35668 -> 192.168.1.2:22, protocol: TCP
Packet: 192.168.1.3:35668 -> 192.168.1.2:22, protocol: TCP