Traffic Control
Traffic Control subsystem is designed to schedule packets using a queuing system which controls the traffic direction and filtering. Traffic control can be used to filter traffic by applying rules and traffic shaping among other functions. The core of traffic control is built around qdiscs which stands for queuing disciplines, qdiscs define the rules for how packets are handled by a queuing system.
There are two types of qdiscs, classful and classless. classful qdiscs enable the creation of hierarchical queuing structures to facilitates the implementation of complex traffic management policies. Classful qdiscs consist of two parts, filters and classes. The best definition is in the man page which says the following:
Queueing Discipline: qdisc is short for ‘queueing discipline’ and it is elementary to understanding traffic control. Whenever the Kernel needs to send a packet to an interface, it is enqueued to the qdisc >configured for that interface. Immediately afterwards, the Kernel tries to get as many packets as possible from the qdisc, for giving them to the network adaptor driver.
Classes: Some qdiscs can contain classes, which contain further qdiscs,traffic may then be enqueued in any of the inner qdiscs, which are within the classes. When the kernel tries to dequeue a >packet from such a classful qdisc it can come from any of the classes. A qdisc may for example prioritize certain kinds of traffic by trying to dequeue from certain classes before others.
Filters: A filter is used by a classful qdisc to determine in which class a packet will be enqueued. Whenever traffic arrives at a class with subclasses, it needs to be classified. Various methods >may be employed to do so, one of these are the filters. All filters attached to the class are called, until one of them returns with a verdict. If no verdict was made, other crit
In essence: classful qdiscs have filters which are used to classify traffic and determine which class a packet should be placed in.
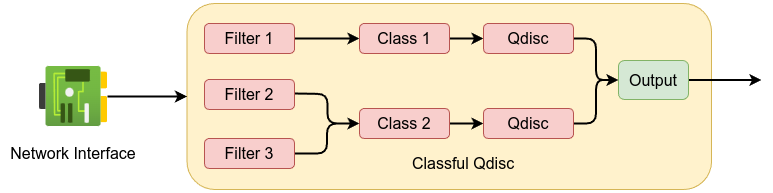
Classless qdiscs are designed to operate as standalone queuing disciplines. classless qdiscs don’t have children or classes which is impossible to attach a filters to it. eBPF filters are intended to work with classful qdiscs where they can classify packets into different classes. You can check which qdisc attached to your network devices is by using ip command or sudo tc qdisc shows the following:
qdisc noqueue 0: dev lo root refcnt 2
qdisc fq_codel 0: dev enp1s0 root refcnt 2 limit 10240p flows 1024 quantum 1514 target 5ms interval 100ms memory_limit 32Mb ecn drop_batch 64
qdisc noqueue on localhost which means no qdisc attached to the localhost which is normal.qdisc fq_codel is attached to the physical interface enp1s0. qdisc fq_codel stands for Fair Queuing Controlled Delay is queuing discipline that classifies data using a stochastic model that it uses a combination of fair queuing and delay control techniques to manage congestion to ensure the fairness of sharing the flow.
limit 10240p this is the queue size and if the limit exceeds this value, packet will start dropping.
flows 1024 this is the number of flow for the incoming packets or the qdisc can track up to 1,024 separate flows.
target 5ms which is the acceptable minimum queue delay.
memory_limit 32Mb sets a limit on the total number of bytes that can be queued in this FQ-CoDel instance.
drop_batch 64 sets the maximum number of packets to drop when limit or memory_limit is exceeded.
Traffic Control has two major components: classifiers and actions. Classifiers are used to inspect packets and decide if they match certain criteria, such as IP addresses, ports or protocols. They essentially sort packets into groups based on rules so that further processing can be applied to the appropriate packets. Actions define what happens to a packet after it has been classified. Once a packet matches a rule, an action is executed on it—such as dropping the packet, changing its priority or redirecting it to another interface.
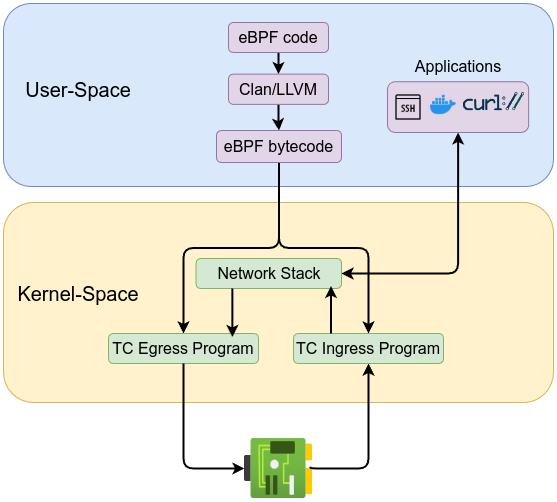
Traffic control eBPF programs are classified either as BPF_PROG_TYPE_SCHED_CLS with SEC("tc") or BPF_PROG_TYPE_SCHED_ACT with SEC("action/").
BPF_PROG_TYPE_SCHED_CLS is often preferred, as it can function as both a classifier and an action executor when used with the direct-action flag. One key advantage is that these eBPF programs can be attached to both egress (outgoing) and ingress (incoming) traffic. This ability allows administrators to inspect, modify and filter packets in both directions.
Note
A single eBPF program instance can only be attached to either egress or ingress on a given interface, but separate instances can be deployed for each direction if needed.
Actions and their corresponding values are defined in include/uapi/linux/pkt_cls.h kernel source code:
#define TC_ACT_UNSPEC (-1)
#define TC_ACT_OK 0
#define TC_ACT_RECLASSIFY 1
#define TC_ACT_SHOT 2
#define TC_ACT_PIPE 3
#define TC_ACT_STOLEN 4
#define TC_ACT_QUEUED 5
#define TC_ACT_REPEAT 6
#define TC_ACT_REDIRECT 7
#define TC_ACT_TRAP 8
Actions and direct-action are defined in this URL which states as the following:
Direct action
When attached in direct action mode, the eBPF program will act as both a classifier and an action. This mode simplifies setups for the most common use cases where we just want to always execute an action. In direct action mode the return value can be one of:
* TC_ACT_UNSPEC (-1) - Signals that the default configured action should be taken.
* TC_ACT_OK (0) - Signals that the packet should proceed.
* TC_ACT_RECLASSIFY (1) - Signals that the packet has to re-start classification from the root qdisc. This is typically used after modifying the packet so its classification might have different results.
* TC_ACT_SHOT (2) - Signals that the packet should be dropped, no other TC processing should happen.
* TC_ACT_PIPE (3) - While defined, this action should not be used and holds no particular meaning for eBPF classifiers.
* TC_ACT_STOLEN (4) - While defined, this action should not be used and holds no particular meaning for eBPF classifiers.
* TC_ACT_QUEUED (5) - While defined, this action should not be used and holds no particular meaning for eBPF classifiers.
* TC_ACT_REPEAT (6) - While defined, this action should not be used and holds no particular meaning for eBPF classifiers.
* TC_ACT_REDIRECT (7) - Signals that the packet should be redirected, the details of how and where to are set as side effects by helpers functions.
Now, let’s look at an example to fully understand the concepts discussed above. In the next example, we use BPF_PROG_TYPE_SCHED_CLS program but will allow us to take actions based on out classification using direct-action later. The code checks for packets on egress with port 8080 and drops them and send a message with bpf_printk.
#include <linux/bpf.h>
#include <linux/if_ether.h>
#include <linux/ip.h>
#include <linux/tcp.h>
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_endian.h>
#include <linux/in.h>
#include <linux/pkt_cls.h>
char _license[] SEC("license") = "GPL";
SEC("tc")
int drop_egress_port_8080(struct __sk_buff *skb) {
void *data = (void *)(long)skb->data;
void *data_end = (void *)(long)skb->data_end;
struct ethhdr *eth = data;
if ((void *)eth + sizeof(*eth) > data_end)
return TC_ACT_OK;
if (bpf_ntohs(eth->h_proto) != ETH_P_IP)
return TC_ACT_OK;
struct iphdr *iph = data + sizeof(*eth);
if ((void *)iph + sizeof(*iph) > data_end)
return TC_ACT_OK;
if (iph->protocol != IPPROTO_TCP)
return TC_ACT_OK;
int ip_header_length = iph->ihl * 4;
struct tcphdr *tcph = data + sizeof(*eth) + ip_header_length;
if ((void *)tcph + sizeof(*tcph) > data_end)
return TC_ACT_OK;
if (bpf_ntohs(tcph->dest) == 8080) {
bpf_printk("Dropping egress packet to port 8080\n");
return TC_ACT_SHOT;
}
return TC_ACT_OK;
}
As shown in the previous code, the program performs a chain of checks. For packets that are not of interest, it returns TC_ACT_OK, allowing them to proceed. However, if the final check detects that the destination port is 8080, it returns TC_ACT_SHOT, which means the packet should be dropped.
Note
When the eBPF program returnsTC_ACT_OK, it signals that the packet should continue its normal processing in the networking stack, effectively “exiting” our code without any special intervention like dropping or redirecting it.
Compile the code using LLVM/clang, then add the clsact qdisc, which enables hooking eBPF programs for both ingress (incoming) and egress (outgoing) traffic sudo tc qdisc add dev qdisc clsact
Next, attach the object file to the egress traffic with the direct-action flag: sudo tc filter add dev enp1s0 egress bpf direct-action obj tc_drop_egress.o sec tc. On a separate machine, start a web server on port 8080 using python3 -m http.server 8080. Back to the eBPF machine, executing a curl command curl http://192.168.1.6:8080/ you will notice that traffic is being dropped and you can see the debug messages using sudo cat /sys/kernel/debug/tracing/trace_pipe or you could use sudo tc exec bpf dbg to show the debug messages, which might look like:
Running! Hang up with ^C!
curl-1636 [003] b..1. 1735.290483: bpf_trace_printk: Dropping egress packet to port 8080
<idle>-0 [003] b.s3. 1736.321969: bpf_trace_printk: Dropping egress packet to port 8080
<idle>-0 [001] b.s3. 1736.834411: bpf_trace_printk: Dropping egress packet to port 8080
<idle>-0 [003] b.s3. 1737.346341: bpf_trace_printk: Dropping egress packet to port 8080
<idle>-0 [003] b.s3. 1737.858194: bpf_trace_printk: Dropping egress packet to port 8080
<idle>-0 [003] b.s3. 1738.370403: bpf_trace_printk: Dropping egress packet to port 8080
The attachment can be stopped by deleting the qdisc using sudo tc qdisc del dev enp1s0 clsact. I hope that Traffic Control is much clearer at this point.
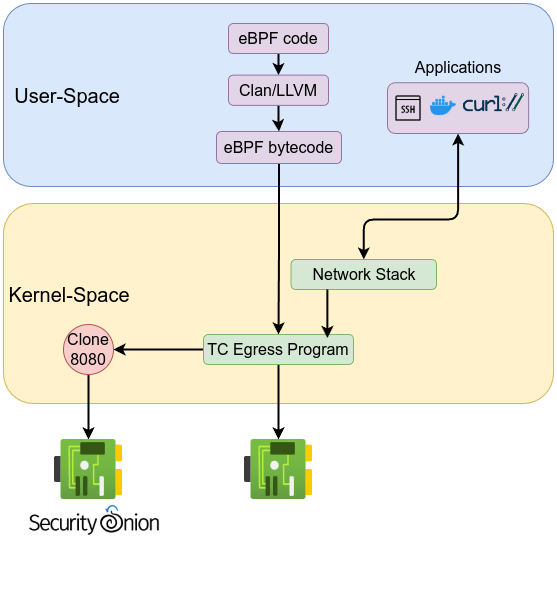
If we want to set up a sensor to analyze traffic from a specific service or port, all we need to do is redirect that traffic using the bpf_clone_redirect helper function to a predefined interface for tapping. The cloning will allow us to monitor traffic with actively interfering or impacting performance. The redirected traffic can then be forwarded to traffic analysis tools such as Security Onion, Suricata, Snort, zeek, …etc. The bpf_clone_redirect helper function clones the packet and then redirects the clone to another interface, while the bpf_redirect helper function redirects the packet without cloning it. Both helper functions require the target interface’s ifindex, which represents the interface ID. bpf_clone_redirect helper function has a prototype as the following:
static long (* const bpf_clone_redirect)(struct __sk_buff *skb, __u32 ifindex, __u64 flags) = (void *) 13;
Cloning traffic not just for IPS/IDS , it can be also used to keep full packet capture (FPC) for later to be used in incident analysis or compromise assessment.
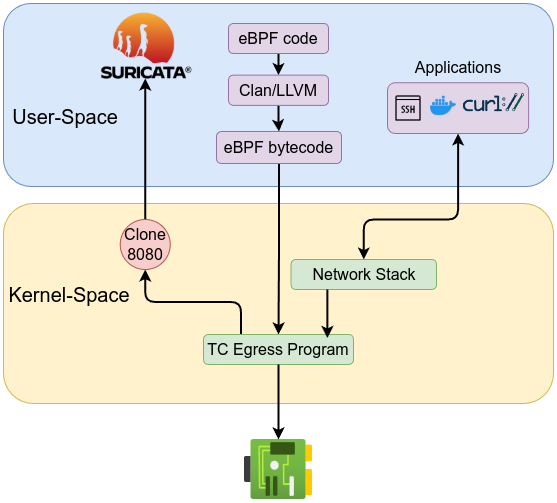
First, let’s setup the interface by creating dummy interface sudo ip link add dummy0 type dummy, then bring the interface up using sudo ip link set dummy0 up, then verify the interface ip link show dummy0 which gives similar to the following:
4: dummy0: <BROADCAST,NOARP,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/ether 16:aa:51:3c:b7:7b brd ff:ff:ff:ff:ff:ff
The interface ID is 4. Now let’s modify the previous code to allow the traffic on port 8080 while cloning it to the dummy interface with ID 4.
#include <linux/bpf.h>
#include <linux/if_ether.h>
#include <linux/ip.h>
#include <linux/tcp.h>
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_endian.h>
#include <linux/in.h>
#include <linux/pkt_cls.h>
char _license[] SEC("license") = "GPL";
SEC("tc")
int clone_egress_port_8080(struct __sk_buff *skb) {
void *data = (void *)(long)skb->data;
void *data_end = (void *)(long)skb->data_end;
struct ethhdr *eth = data;
if ((void *)eth + sizeof(*eth) > data_end)
return TC_ACT_OK;
if (bpf_ntohs(eth->h_proto) != ETH_P_IP)
return TC_ACT_OK;
struct iphdr *iph = data + sizeof(*eth);
if ((void *)iph + sizeof(*iph) > data_end)
return TC_ACT_OK;
if (iph->protocol != IPPROTO_TCP)
return TC_ACT_OK;
int ip_header_length = iph->ihl * 4;
struct tcphdr *tcph = data + sizeof(*eth) + ip_header_length;
if ((void *)tcph + sizeof(*tcph) > data_end)
return TC_ACT_OK;
if (bpf_ntohs(tcph->dest) == 8080) {
int target_ifindex = 4;
bpf_printk("Cloning packet to ifindex %d and allowing original packet\n", target_ifindex);
bpf_clone_redirect(skb, target_ifindex, 0);
return TC_ACT_OK;
}
return TC_ACT_OK;
}
Compile and attach the eBPF program then setup a web server as we did in the previous example. Next, start capturing the traffic on the dummy interface using sudo tcpdump -i dummy0 then curl http://192.168.1.6:8080/index.html You should see tcpdump output similar to the following:
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on dummy0, link-type EN10MB (Ethernet), snapshot length 262144 bytes
23:12:53.941290 IP debian.58768 > client-Standard-PC-Q35-ICH9-2009.http-alt: Flags [S], seq 1415486505, win 64240, options [mss 1460,sackOK,TS val 3409122040 ecr 0,nop,wscale 7], length 0
23:12:53.941711 IP debian.58768 > client-Standard-PC-Q35-ICH9-2009.http-alt: Flags [.], ack 1257763673, win 502, options [nop,nop,TS val 3409122040 ecr 2981277197], length 0
23:12:53.941792 IP debian.58768 > client-Standard-PC-Q35-ICH9-2009.http-alt: Flags [P.], seq 0:93, ack 1, win 502, options [nop,nop,TS val 3409122040 ecr 2981277197], length 93: HTTP: GET /index.html HTTP/1.1
23:12:53.942842 IP debian.58768 > client-Standard-PC-Q35-ICH9-2009.http-alt: Flags [.], ack 185, win 501, options [nop,nop,TS val 3409122041 ecr 2981277198], length 0
23:12:53.942980 IP debian.58768 > client-Standard-PC-Q35-ICH9-2009.http-alt: Flags [F.], seq 93, ack 188, win 501, options [nop,nop,TS val 3409122041 ecr 2981277198], length 0
The traffic captured on the dummy interface can then be analyzed by Suricata or any other network analysis and monitoring tool. The cloned traffic can also be sent to another NIC to be sent out to a sensor machine such as Security Onion server (forward nodes).
The next example demonstrates one of the capabilities of traffic control—manipulating traffic. In this example, the program will change the first 4 bytes of an HTTP response (initiated from port 8080) to ‘XXXX’. This means that instead of seeing ‘HTTP/1.0’, you would see ‘XXXX/1.0’.
The steps are as follows:
- Perform the necessary packet checks until you reach the TCP header.
- Calculate the TCP header length to determine the exact offset of the payload.
- Read the first 4 bytes of the payload.
- Replace these 4 bytes with ‘XXXX’ using the
bpf_skb_store_byteshelper function. - Recalculate the checksum using the
bpf_l4_csum_replacehelper function.
bpf_skb_store_bytes helper function has the following prototype:
static long (* const bpf_skb_store_bytes)(struct __sk_buff *skb, __u32 offset, const void *from, __u32 len, __u64 flags) = (void *) 9;
While bpf_l4_csum_replace helper function has the following prototype:
static long (* const bpf_l4_csum_replace)(struct __sk_buff *skb, __u32 offset, __u64 from, __u64 to, __u64 flags) = (void *) 11;
#include <linux/bpf.h>
#include <linux/if_ether.h>
#include <linux/ip.h>
#include <linux/tcp.h>
#include <linux/in.h>
#include <linux/pkt_cls.h>
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_endian.h>
char _license[] SEC("license") = "GPL";
SEC("tc")
int modify_http_response(struct __sk_buff *skb) {
void *data = (void *)(long)skb->data;
void *data_end = (void *)(long)skb->data_end;
struct ethhdr *eth = data;
if ((void *)eth + sizeof(*eth) > data_end)
return TC_ACT_OK;
if (bpf_ntohs(eth->h_proto) != ETH_P_IP)
return TC_ACT_OK;
struct iphdr *iph = data + sizeof(*eth);
if ((void *)iph + sizeof(*iph) > data_end)
return TC_ACT_OK;
if (iph->protocol != IPPROTO_TCP)
return TC_ACT_OK;
int ip_hdr_len = iph->ihl * 4;
struct tcphdr *tcph = data + sizeof(*eth) + ip_hdr_len;
if ((void *)tcph + sizeof(*tcph) > data_end)
return TC_ACT_OK;
if (bpf_ntohs(tcph->source) != 8080)
return TC_ACT_OK;
int tcp_hdr_len = tcph->doff * 4;
void *payload = (void *)tcph + tcp_hdr_len;
if (payload + 4 > data_end) // ensure there are at least 4 bytes in the payload
return TC_ACT_OK;
char orig_val[4];
if (bpf_skb_load_bytes(skb, (payload - data), orig_val, 4) < 0)
return TC_ACT_OK;
if (orig_val[0] == 'H' && orig_val[1] == 'T' && orig_val[2] == 'T' && orig_val[3] == 'P') {
char new_val[4] = {'X', 'X', 'X', 'X'};
if (bpf_skb_store_bytes(skb, (payload - data), new_val, 4, 0) < 0)
return TC_ACT_OK;
int tcp_csum_offset = ((void *)tcph - data) + offsetof(struct tcphdr, check);
bpf_l4_csum_replace(skb, tcp_csum_offset, *((__u32 *)orig_val), *((__u64 *)new_val), 4);
bpf_printk("Modified HTTP response header from 'HTTP' to 'XXXX'\n");
}
return TC_ACT_OK;
}
Compile the code and attach it on ingress traffic using sudo tc filter add dev enp1s0 ingress bpf direct-action obj modify_http_response.o sec tc.
Next, setup a web server on another machine. Then, from the eBPF machine, execute the following:
nc 192.168.1.6 8080
GET /index.html HTTP/1.1
Host: 192.168.1.6:8080
The output should look similar to the following:
GET /index.html HTTP/1.1
Host: 192.168.1.6:8080
XXXX/1.0 404 File not found
Server: SimpleHTTP/0.6 Python/3.12.3
Date: Thu, 06 Mar 2025 05:13:32 GMT
Connection: close
Content-Type: text/html;charset=utf-8
Content-Length: 335
HTTP/1.0 404 File not found is now replaced with XXXX/1.0 404 File not found.
Note
TC Hardware Offload allows NICs to handle specific traffic control tasks (like filtering and policing) in hardware instead of the CPU similar to how XDP offloads packet processing to reduce CPU overhead (XDP will be explained next).Next, we will talk about XDP (Express Data Path), where XDP programs are executed before packets reach the kernel network stack.