This is the multi-page printable view of this section. Click here to print.
eBPF Probes
- 1: Kprobe and Kretprobe
- 2: Uprobes and Uretprobes
- 3: Tracepoints
- 4: Raw Tracepoints
- 5: Fentry and Fexit
1 - Kprobe and Kretprobe
Writing eBPF Code
When writing eBPF code, you typically need to write two separate parts: one for kernel-space and the other for user-space.
Kernel Space Code:
The kernel-space code is responsible for performing specific tasks, such as tracing, monitoring network packets, filtering system calls, or attaching to kprobes, tracepoints, etc. This code interacts directly with the kernel and can access kernel data structures or events. The kernel space is highly sensitive, so the code running there must be safe and efficient. The kernel-space code is written in a special eBPF-compatible language (with a C-like syntax) and is loaded into the kernel using helper libraries (such as libbpf) or system calls (like bpf()).
User Space Code: User-space code is responsible for loading the eBPF program into the kernel, attaching it to specific hooks or events, and managing communication between user space and kernel space. It also handles tasks like retrieving data from the kernel (e.g., using maps for data storage). User-space code is written in a regular programming language (such as C or Python) and runs outside the kernel, as a user-space application.
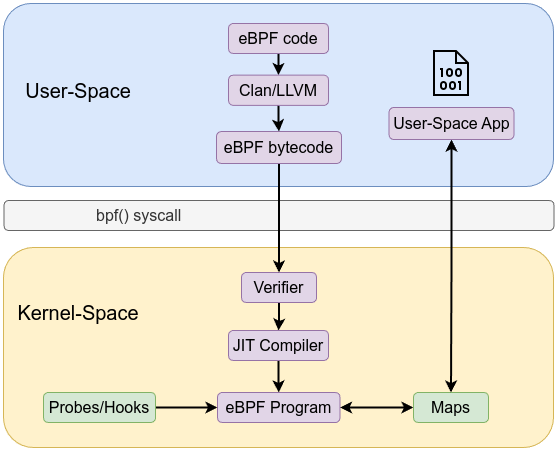
libbpf
libbpf is a C-based library designed to facilitate interaction with the eBPF subsystem in the Linux kernel. It provides a set of high-level and low-level APIs that simplify of loading, verifying, and managing eBPF programs. By handling the complexities of working with the kernel, libbpf enables developers to focus more on optimizing their eBPF code’s performance and correctness, rather than managing the details of user-space and kernel-space interactions.
libbpf includes a variety of BPF helper functions that ease development. These helpers allow eBPF programs to interact with the system more effectively, providing functions for tasks like debugging, manipulating network packets, and working with eBPF maps. This reduces the amount of code developers need to write, enabling them to focus on the logic of their BPF programs.
One of the most significant benefits of libbpf is its support for eBPF CO-RE (Compile Once, Run Everywhere), a mechanism that enhances the portability of eBPF programs. By leveraging BTF (BPF Type Format)—a metadata format that describes kernel data types such as data structures, unions, enums, and function prototypes—libbpf allows developers to write eBPF programs that can be compiled once and run across multiple kernel versions. CO-RE produces an ELF file with precompiled eBPF bytecode that can run across different kernel versions, eliminating the need for recompiling or modifying eBPF code for different systems. BTF information can be generated via
sudo bpftool btf dump file /sys/kernel/btf/vmlinux format c > vmlinux.h
Simply, libbpf uses BTF information to align or modify the types and fields in the eBPF program with the current running kernel. For more information about eBPF CO-RE, please refer to this post.
As stated in kernel documentation
libbpf provides APIs that user space programs can use to manipulate the BPF programs by triggering different phases of a BPF application lifecycle.
The following section provides a brief overview of each phase in the BPF life cycle:
Open phase: In this phase, libbpf parses the BPF object file and discovers BPF maps, BPF programs, and global variables. After a BPF app is opened, user space apps can make additional adjustments (setting BPF program types, if necessary; pre-setting initial values for global variables, etc.) before all the entities are created and loaded.
Load phase: In the load phase, libbpf creates BPF maps, resolves various relocations, and verifies and loads BPF programs into the kernel. At this point, libbpf validates all the parts of a BPF application and loads the BPF program into the kernel, but no BPF program has yet been executed. After the load phase, it’s possible to set up the initial BPF map state without racing with the BPF program code execution.
Attachment phase: In this phase, libbpf attaches BPF programs to various BPF hook points (e.g., tracepoints, kprobes, cgroup hooks, network packet processing pipeline, etc.). During this phase, BPF programs perform useful work such as processing packets, or updating BPF maps and global variables that can be read from user space.
Tear down phase: In the tear down phase, libbpf detaches BPF programs and unloads them from the kernel. BPF maps are destroyed, and all the resources used by the BPF app are freed.
A BPF Object Skeleton File is a C header file (.skel.h) generated using bpftool from a compiled eBPF object file. This header file provides a structured interface for interacting with the eBPF program, simplifying its management from user space. For developers seeking simplicity, the eBPF skeleton provides a more abstracted interface for interacting with eBPF programs. The skeleton generates functions such as <name>__open(), <name>__load(), <name>__attach(), and <name>__destroy(), which automate key steps in the eBPF lifecycle, allowing developers to manage eBPF programs with less effort. The skeleton also provides access to global variables and maps, which are directly accessible as structured fields in the user-space program, making it easier to manipulate these elements without relying on string-based lookups.
eBPF Probes
eBPF probes are mechanisms used to attach eBPF programs to specific events within the kernel or user-space. These probes allow developers to dynamically hook into various parts of the system and execute eBPF programs when those events or locations are triggered, enabling data collection, behavior monitoring, or influencing execution.
eBPF probes allow attaching to various points in the kernel’s execution flow to observe and sometimes modify behavior. Each type of eBPF probe corresponds to a particular attachment point. Some common probe types include:
- kprobe: Attaches to almost any kernel instruction address.
- kretprobe (return probe): Attaches to the return point of a kernel function.
- uprobe and uretprobe: Attach to user-space functions and their returns.
- tracepoint and raw_tracepoint: Attach to static kernel tracepoints for predefined events.
- fentry: Attached to the entry point of a kernel function using an enhanced, lower-overhead mechanism.
- fexit: Attached to the return of a kernel function using an enhanced, lower-overhead mechanism.
kprobe-kretprobe
Kprobes
A kprobe is a dynamic instrumentation mechanism that allows you to attach a custom handler at almost any kernel instruction address, often used at the start of a kernel function. When the CPU executes this probed instruction, it triggers the kprobe handler. This handler can inspect CPU registers, function arguments, and kernel memory state before the original instruction executes. kprobe-based eBPF programs are classified under the program type BPF_PROG_TYPE_KPROBE.
You can list all of the kernel exported symbols using sudo cat /proc/kallsyms and we are only interested in T which represents globally visible text symbols (Code) and they can be attached.
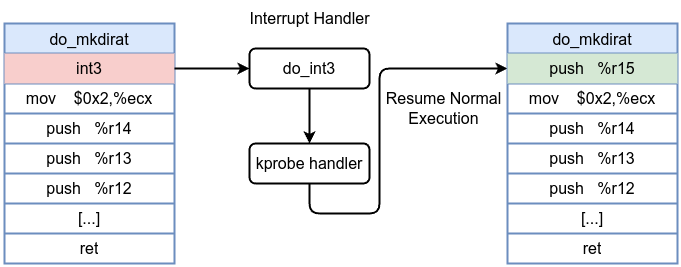
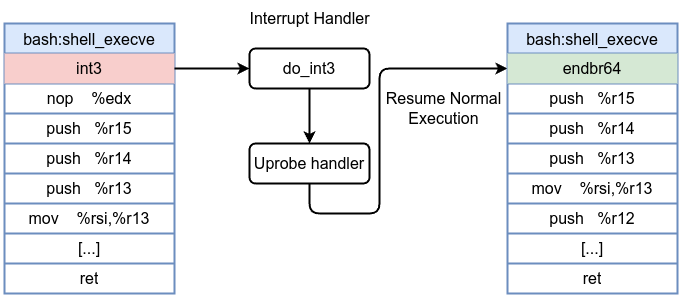
How Kprobes Work Under the Hood
- When you register a kprobe on a kernel function (e.g.,
do_mkdirat), the kernel replaces the first instruction bytes at that function’s entry with a breakpoint instructionint3. - When the function is called, the CPU hits the breakpoint instruction, a trap occurs.
- The kernel’s kprobe infrastructure intercepts this exception and calls your eBPF program’s handler. Your eBPF code then has access to the function arguments and can perform any allowed eBPF operations (e.g., reading fields, printing debug information).
- After the handler completes its task, instruction flow resumes by single-stepping the original instruction. If the kprobe is no longer needed, the original instruction is restored in place of the breakpoint.
Before kprobe:

After kprobe insertion:
Note
kprobes can be attached to nearly any kernel instruction. However, certain functions—such as those involved in kprobe handling itself—cannot be probed, as doing so would trigger recursive traps and potentially destabilize the kernel.As stated in eBPF Docs
The context passed to kprobe programs is `struct pt_regs`. This structure is different for each CPU architecture since it contains a copy of the CPU registers at the time the kprobe was invoked.
It is common for kprobe programs to use the macros from the Libbpf `bpf_tracing.h` header file, which defines `PT_REGS_PARM1` ... `PT_REGS_PARM5` as well as a number of others. These macros will translate to the correct field in `struct pt_regs` depending on the current architecture. Communicating the architecture you are compiling the BPF program for is done by defining one of the `__TARGET_ARCH_*` values in your program or via the command line while compiling.
PT_REGS_PARMX macros are defined in bpf_tracing.h
#define PT_REGS_PARM1(x) (__PT_REGS_CAST(x)->__PT_PARM1_REG)
#define PT_REGS_PARM2(x) (__PT_REGS_CAST(x)->__PT_PARM2_REG)
#define PT_REGS_PARM3(x) (__PT_REGS_CAST(x)->__PT_PARM3_REG)
#define PT_REGS_PARM4(x) (__PT_REGS_CAST(x)->__PT_PARM4_REG)
#define PT_REGS_PARM5(x) (__PT_REGS_CAST(x)->__PT_PARM5_REG)
#define PT_REGS_PARM6(x) (__PT_REGS_CAST(x)->__PT_PARM6_REG)
#define PT_REGS_PARM7(x) (__PT_REGS_CAST(x)->__PT_PARM7_REG)
#define PT_REGS_PARM8(x) (__PT_REGS_CAST(x)->__PT_PARM8_REG)
struct pt_regs is defined in /arch/x86/include/uapi/asm/ptrace.h for the x86-64 architecture:
struct pt_regs {
unsigned long r15;
unsigned long r14;
unsigned long r13;
unsigned long r12;
unsigned long rbp;
unsigned long rbx;
unsigned long r11;
unsigned long r10;
unsigned long r9;
unsigned long r8;
unsigned long rax;
unsigned long rcx;
unsigned long rdx;
unsigned long rsi;
unsigned long rdi;
unsigned long orig_rax;
unsigned long rip;
unsigned long cs;
unsigned long eflags;
unsigned long rsp;
unsigned long ss;
};
The struct pt_regs stores the CPU’s register state at the time of an interrupt, system call, or exception, enabling the kernel to save and restore the execution context of a process. By capturing the state of general-purpose registers, segment registers, and special registers (such as the instruction pointer and stack pointer).
In the next example we will attach a kprobe to start of of do_mkdirat syscall which is used to create a new directory.
do_mkdirat prototype is int do_mkdirat(int dfd, struct filename *name, umode_t mode); and it has 3 parameters dfd, struct filename, mode.
dfd: stands for “directory file descriptor.” It specifies the directory relative to which the new directory should be created.
struct filename is a kernel data structure defined in /include/linux/fs.h
struct filename {
const char *name; /* pointer to actual string */
const __user char *uptr; /* original userland pointer */
atomic_t refcnt;
struct audit_names *aname;
const char iname[];
};
mode represents file permissions for the created directory.
Now let’s start with eBPF kernel code
#define __TARGET_ARCH_x86
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
#include <bpf/bpf_core_read.h>
char LICENSE[] SEC("license") = "GPL";
SEC("kprobe/do_mkdirat")
int kprobe_mkdir(struct pt_regs *ctx)
{
pid_t pid;
const char *filename;
umode_t mode;
pid = bpf_get_current_pid_tgid() >> 32;
struct filename *name = (struct filename *)PT_REGS_PARM2(ctx);
filename = BPF_CORE_READ(name, name);
mode = PT_REGS_PARM3(ctx);
bpf_printk("KPROBE ENTRY pid = %d, filename = %s, mode = %u\n", pid, filename,mode);
return 0;
}
First, as we just explained that we need to define __TARGET_ARCH__XX according to your architecture then include vmlinux.h
#define __TARGET_ARCH_x86
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
#include <bpf/bpf_core_read.h>
bpf_core_read.h header file provides macros for reading data from kernel or user space in a way that is compatible with BPF CO-RE (Compile Once, Run Everywhere) such as BPF_CORE_READ macro.
char LICENSE[] SEC("license") = "GPL";
Then we added license we we discussed in the previous chapter
SEC("kprobe/do_mkdirat")
int kprobe_mkdir(struct pt_regs *ctx)
SEC It tells the compile what ELF section to put which is kprobe and where to attach it which is do_mkdirat. Then kprobe handler kprobe_mkdir that gets executed when do_mkdirat entry point is triggered.
struct pt_regs *ctx is the context passed to the eBPF program by the kernel. It contains information about the registers at the time the function was invoked, including the function arguments, return addresses. The ctx pointer will be used to extract these values.
pid = bpf_get_current_pid_tgid() >> 32;
bpf_get_current_pid_tgid() is an eBPF helper function that returns a 64-bit value, where:
- The lower 32 bits represent the thread group ID (TGID), which is the PID of the thread that initiated the system call.
- The upper 32 bits represent the thread ID (PID) of the current thread.
Since we are interested in the
PID, we shift the 64-bit value to the right by 32 bits (>> 32) to get just the process ID (PID) of the current process.
struct filename *name = (struct filename *)PT_REGS_PARM2(ctx);
filename = BPF_CORE_READ(name, name);
PT_REGS_PARM2(ctx): As previously discussed, this is a macro used to extract the second argument of the function being probed. In this case, the second argument is a pointer to the filename structure, which is passed to the do_mkdirat function. struct filename *name: This line casts the second parameter (a pointer to struct filename) to the name variable. struct filename holds the path to the directory to be created.
BPF_CORE_READ(name, name): It uses the BPF_CORE_READ macro from the bpf_core_read.h header. This macro is a helper function designed to safely read fields from kernel structures in a way that is compatible with BPF CO-RE (Compile Once, Run Everywhere) and it’s necessary because kernel structures may change between different kernel versions, and BPF_CORE_READ ensures that the field name can be accessed in a manner that works across various kernel versions.
name field: In this case, the field name in struct filename holds the string representing the path of the directory to be created.
mode = PT_REGS_PARM3(ctx);
PT_REGS_PARM3(ctx): This macro extracts the third argument passed to do_mkdirat, which represents the mode (permissions) of the directory to be created.
bpf_printk("KPROBE ENTRY pid = %d, filename = %s, mode = %u\n", pid, filename,mode);
bpf_printk: This is an eBPF macro that allows printing formatted output to the kernel’s trace buffer, which is accessible via /sys/kernel/debug/tracing/trace_pipe. bpf_printk only supports up to 3 arguments.
At this point we need to compile this code into an object file using clang with help from bpftool.
- Install required tools
sudo apt install linux-tools-$(uname -r) clang llvm libbpf-dev bpftool, - Generate
vmlinux.hviasudo bpftool btf dump file /sys/kernel/btf/vmlinux format c > vmlinux.h - Compile eBPF code into an object file
clang -g -O2 -target bpf -c kprobe-mkdirat.bpf.c -o kprobe-mkdirat.owith debugging information (-g) and optimization level-O2. The-target bpfflag ensures that Clang compiles the code for the eBPF target architecture. - Generate the skeleton header file
sudo bpftool gen skeleton kprobe-mkdirat.o > kprobe-mkdirat.skel.h
Note
If you encounter the error/usr/include/linux/types.h:5:10: fatal error: 'asm/types.h' file not found while compiling the eBPF kernel code , you can execute the command sudo ln -s /usr/include/x86_64-linux-gnu/asm /usr/include/asm.
Examining the generated object file llvm-objdump -h kprobe-mkdirat.o
kprobe-mkdirat.o: file format elf64-bpf
Sections:
Idx Name Size VMA Type
0 00000000 0000000000000000
1 .strtab 00000141 0000000000000000
2 .text 00000000 0000000000000000 TEXT
3 kprobe/do_mkdirat 000000a8 0000000000000000 TEXT
4 .relkprobe/do_mkdirat 00000010 0000000000000000
5 license 0000000d 0000000000000000 DATA
6 .rodata 00000031 0000000000000000 DATA
[...]
The generated object file kprobe-mkdirat.o has the file format ELF64-BPF, indicating it is a 64-bit ELF object file specifically for BPF (eBPF) code.
kprobe/do_mkdirat This is the section header where the actual eBPF program resides, as indicated by SEC("kprobe/do_mkdirat") in the code. This section contains the code that will be executed when the do_mkdirat kprobe is triggered.
Let’s move to the user-space code. The following code is derived from libbpf-bootstrap
#include <stdio.h>
#include <unistd.h>
#include <sys/resource.h>
#include <bpf/libbpf.h>
#include "kprobe-mkdirat.skel.h"
static int libbpf_print_fn(enum libbpf_print_level level, const char *format, va_list args)
{
return vfprintf(stderr, format, args);
}
int main(int argc, char **argv)
{
struct kprobe_mkdirat *skel;
int err;
libbpf_set_print(libbpf_print_fn);
skel = kprobe_mkdirat__open();
if (!skel) {
fprintf(stderr, "Failed to open BPF skeleton\n");
return 1;
}
err = kprobe_mkdirat__load(skel);
if (err) {
fprintf(stderr, "Failed to load and verify BPF skeleton\n");
goto cleanup;
}
err = kprobe_mkdirat__attach(skel);
if (err) {
fprintf(stderr, "Failed to attach BPF skeleton\n");
goto cleanup;
}
printf("Successfully started! Please run `sudo cat /sys/kernel/debug/tracing/trace_pipe` "
"to see output of the BPF programs.\n");
for (;;) {
fprintf(stderr, ".");
sleep(1);
}
cleanup:
kprobe_mkdirat__destroy(skel);
return -err;
}
Let’s divide the code
static int libbpf_print_fn(enum libbpf_print_level level, const char *format, va_list args)
{
return vfprintf(stderr, format, args);
}
A function for libbpf debug and error messages.
struct kprobe_mkdirat *skel;
declares a pointer skel to a structure kprobe_mkdirat, which represents the eBPF skeleton for the eBPF program attached to the do_mkdirat kprobe. This structure is used to manage the loading, attaching, and cleanup of the eBPF program.
skel = kprobe_mkdirat__open();
This function opens the eBPF skeleton for the kprobe_mkdirat program to set up the eBPF program, including its maps, and prepares it for loading.
err = kprobe_mkdirat__load(skel);
This function loads and verifies the eBPF program defined in the skeleton. It ensures that the eBPF code is valid and ready to be attached to the kernel.
err = kprobe_mkdirat__attach(skel);
This function attaches the eBPF program to the kernel’s kprobe at the do_mkdirat function. It makes the program active and starts tracing the specified kernel function.
kprobe_mkdirat__destroy(skel);
This function cleans up and frees resources used by the BPF skeleton. It detaches the program and destroys the associated maps and other resources.
All these functions (_open(), _load(), _attach(), and _destroy()) are automatically generated from the eBPF skeleton file. As we explained earlier that the skeleton file abstracts much of the complexity of interacting with BPF programs, making it much easier to build user-space code for managing and interacting with eBPF programs. It eliminates the need for manual setup and error handling, simplify the entire process.
To compile the user-space code, we use the following command: clang -o loader loader.c -lbpf. This compiles the loader.c file and links it with the libbpf library, producing an executable named loader.
To start the eBPF program, you can use the following command: sudo ./loader. This runs the compiled user-space program loader, which loads the eBPF program, attaches it to the kernel function (in this case, the do_mkdirat function via kprobes), and starts tracing the kernel function. The sudo is necessary because eBPF programs often require root privileges to attach to kernel functions or tracepoints.
libbpf: loading object 'kprobe_mkdirat' from buffer
libbpf: elf: section(3) kprobe/do_mkdirat, size 168, link 0, flags 6, type=1
libbpf: sec 'kprobe/do_mkdirat': found program 'kprobe_mkdir' at insn offset 0 (0 bytes), code size 21 insns (168 bytes)
libbpf: elf: section(4) .relkprobe/do_mkdirat, size 16, link 27, flags 40, type=9
libbpf: elf: section(5) license, size 13, link 0, flags 3, type=1
libbpf: license of kprobe_mkdirat is GPL
libbpf: elf: section(6) .rodata, size 49, link 0, flags 2, type=1
libbpf: elf: section(17) .BTF, size 1407, link 0, flags 0, type=1
libbpf: elf: section(19) .BTF.ext, size 284, link 0, flags 0, type=1
libbpf: elf: section(27) .symtab, size 384, link 1, flags 0, type=2
libbpf: looking for externs among 16 symbols...
libbpf: collected 0 externs total
libbpf: map 'kprobe_m.rodata' (global data): at sec_idx 6, offset 0, flags 80.
libbpf: map 0 is "kprobe_m.rodata"
libbpf: sec '.relkprobe/do_mkdirat': collecting relocation for section(3) 'kprobe/do_mkdirat'
libbpf: sec '.relkprobe/do_mkdirat': relo #0: insn #14 against '.rodata'
libbpf: prog 'kprobe_mkdir': found data map 0 (kprobe_m.rodata, sec 6, off 0) for insn 14
libbpf: loading kernel BTF '/sys/kernel/btf/vmlinux': 0
libbpf: map 'kprobe_m.rodata': created successfully, fd=4
libbpf: sec 'kprobe/do_mkdirat': found 3 CO-RE relocations
libbpf: CO-RE relocating [2] struct pt_regs: found target candidate [83] struct pt_regs in [vmlinux]
libbpf: prog 'kprobe_mkdir': relo #0: <byte_off> [2] struct pt_regs.si (0:13 @ offset 104)
libbpf: prog 'kprobe_mkdir': relo #0: matching candidate #0 <byte_off> [83] struct pt_regs.si (0:13 @ offset 104)
libbpf: prog 'kprobe_mkdir': relo #0: patched insn #3 (LDX/ST/STX) off 104 -> 104
libbpf: CO-RE relocating [7] struct filename: found target candidate [4878] struct filename in [vmlinux]
libbpf: prog 'kprobe_mkdir': relo #1: <byte_off> [7] struct filename.name (0:0 @ offset 0)
libbpf: prog 'kprobe_mkdir': relo #1: matching candidate #0 <byte_off> [4878] struct filename.name (0:0 @ offset 0)
libbpf: prog 'kprobe_mkdir': relo #1: patched insn #4 (ALU/ALU64) imm 0 -> 0
libbpf: prog 'kprobe_mkdir': relo #2: <byte_off> [2] struct pt_regs.dx (0:12 @ offset 96)
libbpf: prog 'kprobe_mkdir': relo #2: matching candidate #0 <byte_off> [83] struct pt_regs.dx (0:12 @ offset 96)
libbpf: prog 'kprobe_mkdir': relo #2: patched insn #12 (LDX/ST/STX) off 96 -> 96
Successfully started! Please run `sudo cat /sys/kernel/debug/tracing/trace_pipe` to see output of the BPF programs.
..............
To view the output of the eBPF program, you can open a separate terminal window and run the following command: sudo cat /sys/kernel/debug/tracing/trace_pipe
Then in another separate terminal run mkdir testing. In the second terminal, you should now see the following output:
mkdir-2173 [003] ...21 12952.686720: bpf_trace_printk: KPROBE ENTRY pid = 2173, filename = testing, mode = 511
mode = 511. The value 511 is the decimal representation of the octal permission 0777.
To observe the behavior of loading the eBPF program, you can run strace using the following command: sudo strace -ebpf ./loader. This will trace the bpf() system calls made by the loader program.
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_KPROBE, insn_cnt=21, insns=0x55f5e460a0f0, license="GPL", log_level=0, log_size=0, log_buf=NULL, kern_version=KERNEL_VERSION(6, 12, 12), prog_flags=0, prog_name="kprobe_mkdir", prog_ifindex=0, expected_attach_type=BPF_CGROUP_INET_INGRESS, prog_btf_fd=4, func_info_rec_size=8, func_info=0x55f5e4608850, func_info_cnt=1, line_info_rec_size=16, line_info=0x55f5e46088d0, line_info_cnt=9, attach_btf_id=0, attach_prog_fd=0, fd_array=NULL}, 148) = 5
The previous output tells us that the program type is BPF_PROG_TYPE_KPROBE in prog_type=BPF_PROG_TYPE_KPROBE, and prog_name="kprobe_mkdir" is the eBPF program that will be executed when the do_mkdirat entry point is triggered.
Congratulations! You’ve just run your first eBPF program, and it’s a portable eBPF program that can work across different kernel versions. It wasn’t that complicated, was it?
In eBPF kernel code, we used the name of the kprobe handler as kprobe_mkdir and passed a struct pt_regs as the context for the kprobe_mkdir function. Another approach is using BPF_KPROBE, which offers a more convenient and readable way to define kprobe handlers. With BPF_KPROBE, you specify the name of the function followed by any additional arguments you want to capture, making it a simpler and cleaner method.
#define __TARGET_ARCH_x86
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
#include <bpf/bpf_core_read.h>
char LICENSE[] SEC("license") = "GPL";
SEC("kprobe/do_mkdirat")
int BPF_KPROBE(capture_mkdir, int dfd, struct filename *name, umode_t mode)
{
pid_t pid;
const char *filename;
pid = bpf_get_current_pid_tgid() >> 32;
filename = BPF_CORE_READ(name, name);
bpf_printk("KPROBE ENTRY pid = %d, filename = %s, mode = %u\n", pid, filename, mode);
return 0;
}
This approach is more convenient and readable, while giving the same results. Either way, it’s up to you to choose which method is easier for you.
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_KPROBE, insn_cnt=22, insns=0x556e4ec810e0, license="GPL", log_level=0, log_size=0, log_buf=NULL, kern_version=KERNEL_VERSION(6, 12, 12), prog_flags=0, prog_name="capture_mkdir", prog_ifindex=0, expected_attach_type=BPF_CGROUP_INET_INGRESS, prog_btf_fd=4, func_info_rec_size=8, func_info=0x556e4ec7f840, func_info_cnt=1, line_info_rec_size=16, line_info=0x556e4ec7f8c0, line_info_cnt=8, attach_btf_id=0, attach_prog_fd=0, fd_array=NULL}, 148) = 5
Now let’s move forward to walkthrough kretprobe.
Kretprobes
A kretprobe fires when a monitored function returns. While a kprobe targets function entry (or a specific instruction), a kretprobe targets function exit. By pairing a kprobe at function entry with a kretprobe at function exit, you can measure how long a function took to run or check its return value. kretprobe-based eBPF programs are also classified under the program type BPF_PROG_TYPE_KPROBE
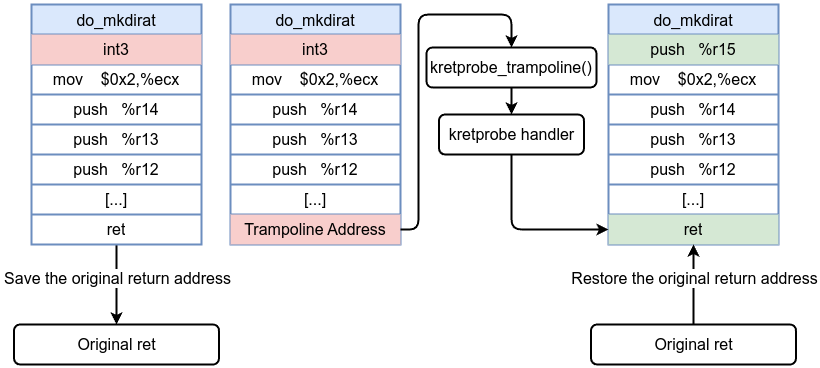
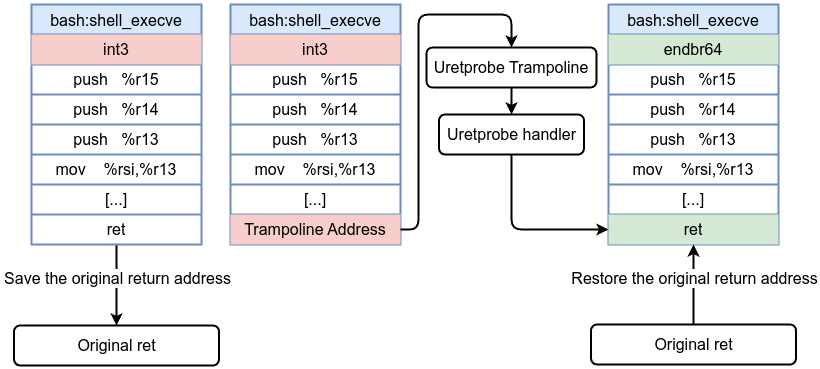
How Kretprobes Work Under the Hood
- When you register a kretprobe for a function, the kprobe mechanism inserts a probe at the function’s entry to store the original return address and replace it with a trampoline.
- The original return address is replaced with kretprobe_trampoline() address (which is the address of the trampoline) during function entry. The trampoline is also kprobed.
- When the function returns, control jumps to the trampoline instead of the original return address.
- Hitting the trampoline triggers the kretprobe handler. This handler can access the function’s return value and any data stored at entry time.
- The original return address is restored, and the function’s caller proceeds as usual.
Before kretprobe:

After kretprobe insertion:
Now let’s take a look at the same example by hooking kretprobe to do_mkdirat. First, Let’s look at the eBPF kernel code.
#define __TARGET_ARCH_x86
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
#include <bpf/bpf_core_read.h>
char LICENSE[] SEC("license") = "GPL";
SEC("kretprobe/do_mkdirat")
int kretprobe_mkdir(struct pt_regs *ctx)
{
pid_t pid;
pid = bpf_get_current_pid_tgid() >> 32;
long ret = PT_REGS_RC(ctx);
bpf_printk("KPROBE ENTRY pid = %d, return = %d\n", pid, ret);
return 0;
}
We changed SEC from ("kprobe/do_mkdirat") to ("kretprobe/do_mkdirat")
SEC("kretprobe/do_mkdirat")
int kretprobe_mkdir(struct pt_regs *ctx)
Using PT_REGS_RC macro to extract the return value form pt_regs structure. Macro PT_REGS_RC is defined in bpf_tracing.h as
#define PT_REGS_RC(x) (__PT_REGS_CAST(x)->__PT_RC_REG)
To compile we could do exactly the same as we did in the previous kprobe example.
- Generate
vmlinux.hvia
sudo bpftool btf dump file /sys/kernel/btf/vmlinux format c > vmlinux.h
- Compile eBPF code into an object file
clang -g -O2 -target bpf -c kretprobe-mkdirat.bpf.c -o kretprobe-mkdirat.owith debugging information (-g) and optimization level-O2. The-target bpfflag ensures that Clang compiles the code for the eBPF target architecture. - Generate the skeleton header file
sudo bpftool gen skeleton kretprobe-mkdirat.o > kprobe-kretprobe.skel.h
Moving to the second part which is the user-space code for opening, loading, attaching and destroying the eBPF code, let’s use the the previous code and modify it.
#include <stdio.h>
#include <unistd.h>
#include <sys/resource.h>
#include <bpf/libbpf.h>
#include "kretprobe-mkdirat.skel.h"
static int libbpf_print_fn(enum libbpf_print_level level, const char *format, va_list args)
{
return vfprintf(stderr, format, args);
}
int main(int argc, char **argv)
{
struct kretprobe_mkdirat *skel;
int err;
libbpf_set_print(libbpf_print_fn);
skel = kretprobe_mkdirat__open();
if (!skel) {
fprintf(stderr, "Failed to open BPF skeleton\n");
return 1;
}
err = kretprobe_mkdirat__load(skel);
if (err) {
fprintf(stderr, "Failed to load and verify BPF skeleton\n");
goto cleanup;
}
err = kretprobe_mkdirat__attach(skel);
if (err) {
fprintf(stderr, "Failed to attach BPF skeleton\n");
goto cleanup;
}
printf("Successfully started! Please run `sudo cat /sys/kernel/debug/tracing/trace_pipe` "
"to see output of the BPF programs.\n");
for (;;) {
fprintf(stderr, ".");
sleep(1);
}
cleanup:
kretprobe_mkdirat__destroy(skel);
return -err;
}
We need to change some lines here to match out generated skeleton file such as
#include "kretprobe-mkdirat.skel.h"
struct kretprobe_mkdirat *skel;
skel = kretprobe_mkdirat__open();
err = kretprobe_mkdirat__load(skel);
err = kretprobe_mkdirat__attach(skel);
kretprobe_mkdirat__destroy(skel);
Finally, let’s compile it and link it to libbpf clang -o loader loader.c -lbpf then run it as the previous with sudo ./loader. Then sudo cat /sys/kernel/debug/tracing/trace_pipe in a separate terminal. Then use command mkdir test and we get
<...>-2053 [002] ...21 5359.243727: bpf_trace_printk: KPROBE ENTRY pid = 2053, return = 0
Return value 0 indicates success, while any non-zero value represents an error, with the specific error codes defined in /include/uapi/asm-generic/errno-base.h.
#define EPERM 1 /* Operation not permitted */
#define ENOENT 2 /* No such file or directory */
#define ESRCH 3 /* No such process */
#define EINTR 4 /* Interrupted system call */
#define EIO 5 /* I/O error */
#define ENXIO 6 /* No such device or address */
#define E2BIG 7 /* Argument list too long */
#define ENOEXEC 8 /* Exec format error */
#define EBADF 9 /* Bad file number */
#define ECHILD 10 /* No child processes */
#define EAGAIN 11 /* Try again */
#define ENOMEM 12 /* Out of memory */
#define EACCES 13 /* Permission denied */
#define EFAULT 14 /* Bad address */
#define ENOTBLK 15 /* Block device required */
#define EBUSY 16 /* Device or resource busy */
#define EEXIST 17 /* File exists */
#define EXDEV 18 /* Cross-device link */
#define ENODEV 19 /* No such device */
#define ENOTDIR 20 /* Not a directory */
#define EISDIR 21 /* Is a directory */
#define EINVAL 22 /* Invalid argument */
#define ENFILE 23 /* File table overflow */
#define EMFILE 24 /* Too many open files */
#define ENOTTY 25 /* Not a typewriter */
#define ETXTBSY 26 /* Text file busy */
#define EFBIG 27 /* File too large */
#define ENOSPC 28 /* No space left on device */
#define ESPIPE 29 /* Illegal seek */
#define EROFS 30 /* Read-only file system */
#define EMLINK 31 /* Too many links */
#define EPIPE 32 /* Broken pipe */
#define EDOM 33 /* Math argument out of domain of func */
#define ERANGE 34 /* Math result not representable */
For example, if you try to run mkdir test command again you will get the following output.
mkdir-2054 [003] ...21 5365.024388: bpf_trace_printk: KPROBE ENTRY pid = 2054, return = -17
This indicate EEXIST - file exists. Running it with strace sudo strace -ebpf ./loader to capture bpf() syscalls shows that the the prog_type is BPF_PROG_TYPE_KPROBE and the prog_name is kretprobe_mkdir
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_KPROBE, insn_cnt=11, insns=0x55eb0c2b8000, license="GPL", log_level=0, log_size=0, log_buf=NULL, kern_version=KERNEL_VERSION(6, 12, 12), prog_flags=0, prog_name="kretprobe_mkdir", prog_ifindex=0, expected_attach_type=BPF_CGROUP_INET_INGRESS, prog_btf_fd=4, func_info_rec_size=8, func_info=0x55eb0c2b67f0, func_info_cnt=1, line_info_rec_size=16, line_info=0x55eb0c2b6870, line_info_cnt=6, attach_btf_id=0, attach_prog_fd=0, fd_array=NULL}, 148) = 5
The better approach is to use BPF_KRETPROBE macro, which offers a more convenient and readable way to define kretprobe handlers, as mentioned earlier.
#define __TARGET_ARCH_x86
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
#include <bpf/bpf_core_read.h>
char LICENSE[] SEC("license") = "GPL";
SEC("kretprobe/do_mkdirat")
int BPF_KRETPROBE(do_mkdirat, int ret)
{
pid_t pid;
pid = bpf_get_current_pid_tgid() >> 32;
bpf_printk("KPROBE ENTRY pid = %d, return = %d\n", pid, ret);
return 0;
}
As you can see, this is much simpler and cleaner.
Combining the use of both kprobe and kretprobe on the do_mkdirat kernel function provides insight into the arguments received by do_mkdirat and its return value. This type of instrumentation is valuable for several reasons, such as debugging, system performance monitoring, maintaining a detailed record of directory creation for forensic analysis, and detecting malicious activities like attempting unauthorized directory creation.
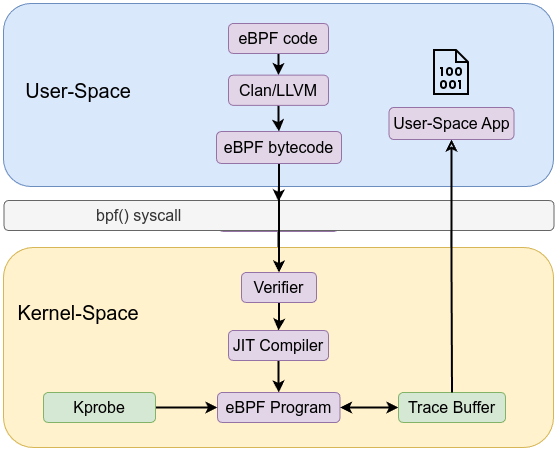
/sys/kernel/debug/tracing/trace_pipe is globally shared interface that aggregates all ebpf programs trace events, which can lead to contention and data mixing. In contrast, using maps provides a dedicated, structured, and efficient mechanism to pass data between kernel and user space, offering better control and isolation.
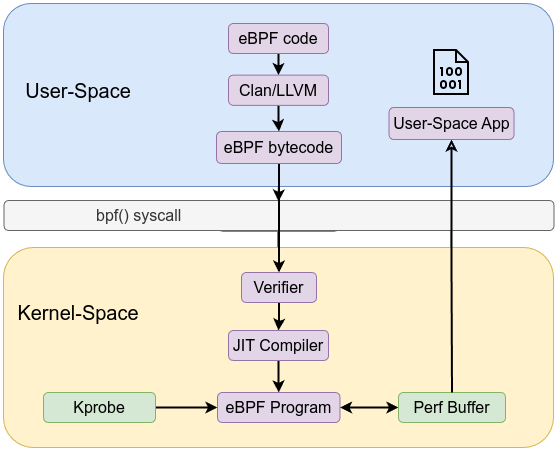
Let’s go forward and use maps instead of the kernel’s trace buffer /sys/kernel/debug/tracing/trace_pipe. Using the first example and add BPF_MAP_TYPE_PERF_EVENT_ARRAY to it and store our data using bpf_perf_event_output in BPF perf event.
#define __TARGET_ARCH_x86
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
#include <bpf/bpf_core_read.h>
struct event {
pid_t pid;
char filename[256];
umode_t mode;
};
struct {
__uint(type, BPF_MAP_TYPE_PERF_EVENT_ARRAY);
__uint(max_entries, 1024);
__type(key, int);
__type(value, int);
} mkdir SEC(".maps");
char LICENSE[] SEC("license") = "GPL";
SEC("kprobe/do_mkdirat")
int BPF_KPROBE(do_mkdirat, int dfd, struct filename *name, umode_t mode)
{
pid_t pid = bpf_get_current_pid_tgid() >> 32;
struct event ev = {};
ev.pid = pid;
ev.mode = mode;
const char *filename = BPF_CORE_READ(name, name);
bpf_probe_read_str(ev.filename, sizeof(ev.filename), filename);
bpf_perf_event_output(ctx, &mkdir, BPF_F_CURRENT_CPU, &ev, sizeof(ev));
return 0;
}
First we defined the structure for the event data that will be sent to user-space.
struct event {
pid_t pid;
char filename[256];
umode_t mode;
};
Then defined a map of type BPF_MAP_TYPE_PERF_EVENT_ARRAY as we explained earlier.
struct {
__uint(type, BPF_MAP_TYPE_PERF_EVENT_ARRAY); // Type of BPF map
__uint(max_entries, 1024); // Maximum number of entries in the map
__type(key, int); // Type of the key
__type(value, int); // Type of the value
} mkdir SEC(".maps");
Then we created ev of type struct event and store both pid and mode
struct event ev = {};
ev.pid = pid;
ev.mode = mode;
Next, we used bpf_probe_read_str to safely read a string from kernel space and copy it into the eBPF program’s memory space.
bpf_probe_read_str(ev.filename, sizeof(ev.filename), filename);
Finally, write ev data into our created map mkdir.
bpf_perf_event_output(ctx, &mkdir, BPF_F_CURRENT_CPU, &ev, sizeof(ev));
The user-space loader code
#include <stdio.h>
#include <unistd.h>
#include <sys/resource.h>
#include <bpf/libbpf.h>
#include <bpf/bpf.h>
#include "kprobe-mkdirat.skel.h"
#define PERF_BUFFER_PAGES 64
static int libbpf_print_fn(enum libbpf_print_level level, const char *format, va_list args)
{
return vfprintf(stderr, format, args);
}
struct event {
pid_t pid;
char filename[256];
mode_t mode;
};
static void handle_event(void *ctx, int cpu, void *data, __u32 data_sz)
{
struct event *evt = (struct event *)data;
printf("Process ID: %d, filename: %s, mode: %d\n", evt->pid, evt->filename, evt->mode);
}
static void handle_lost_events(void *ctx, int cpu, __u64 lost_cnt)
{
fprintf(stderr, "Lost %llu events on CPU %d\n", lost_cnt, cpu);
}
int main(int argc, char **argv)
{
struct kprobe-mkdirat *skel;
struct perf_buffer *pb = NULL;
int err;
libbpf_set_print(libbpf_print_fn);
skel = kprobe-mkdirat__open();
if (!skel) {
fprintf(stderr, "Failed to open BPF skeleton\n");
return 1;
}
err = kprobe-mkdirat__load(skel);
if (err) {
fprintf(stderr, "Failed to load and verify BPF skeleton\n");
goto cleanup;
}
err = kprobe-mkdirat__attach(skel);
if (err) {
fprintf(stderr, "Failed to attach BPF skeleton\n");
goto cleanup;
}
pb = perf_buffer__new(bpf_map__fd(skel->maps.mkdir), PERF_BUFFER_PAGES, handle_event, handle_lost_events, NULL, NULL);
if (!pb) {
fprintf(stderr, "Failed to create perf buffer\n");
goto cleanup;
}
printf("Successfully started! Listening for events...\n");
while (1) {
err = perf_buffer__poll(pb, 100);
if (err < 0) {
fprintf(stderr, "Error polling perf buffer\n");
break;
}
}
cleanup:
perf_buffer__free(pb);
kprobe-mkdirat__destroy(skel);
return -err;
}
First we defined the structure to store event data.
struct event {
pid_t pid;
char filename[256];
umode_t mode;
};
Next, we defined handle_event which gets called when a new event is read from the perf buffer. It casts the data pointer to the struct event and prints the pid, filename, and mode values. Then, we defined handle_lost_events which handles lost events (when the buffer overflows). It prints a message indicating how many events were lost on a specific CPU.
static void handle_event(void *ctx, int cpu, void *data, __u32 data_sz)
{
struct event *evt = (struct event *)data;
printf("Process ID: %d, filename: %s, mode: %d\n", evt->pid, evt->filename, evt->mode);
}
static void handle_lost_events(void *ctx, int cpu, __u64 lost_cnt)
{
fprintf(stderr, "Lost %llu events on CPU %d\n", lost_cnt, cpu);
}
Then we Initialize pb to hold the perf buffer, struct perf_buffer is defined in /tools/lib/bpf/libbpf.c
struct perf_buffer *pb = NULL;
Next, we created a perf buffer for our perf array map BPF_MAP_TYPE_PERF_EVENT_ARRAY using perf_buffer__new and it has the following prototype
struct perf_buffer * perf_buffer__new (int map_fd, size_t page_cnt, perf_buffer_sample_fn sample_cb, perf_buffer_lost_fn lost_cb, void *ctx, const struct perf_buffer_opts *opts)
perf_buffer__new takes a file descriptor for BPF_MAP_TYPE_PERF_EVENT_ARRAY , memory page size for each CPU, a function to invoke on each each received data, a function to invoke in case of data loss, *ctx and *opts.
pb = perf_buffer__new(bpf_map__fd(skel->maps.mkdir), PERF_BUFFER_PAGES, handle_event, handle_lost_events, NULL, NULL);
if (!pb) {
fprintf(stderr, "Failed to create perf buffer\n");
goto cleanup;
}
perf_buffer__poll is a function provided by the libbpf library that allows user-space applications to poll a perf buffer for new data. It has the following prototype:
int perf_buffer__poll (struct perf_buffer *pb, int timeout_ms)
err = perf_buffer__poll(pb, 100);
If Positive timeout_ms: Blocks for the specified time (e.g., 100ms). If data arrives within that time, it processes and returns. If no data arrives, it returns 0.
Iftimeout_ms == 0: Non-blocking. Checks immediately for data. Returns 0 if no data is available.
If Negative timeout_ms: Blocks indefinitely until data becomes available.
Finally, free perf buffer resource.
perf_buffer__free(pb);
After compiling as we did before, run loader using sudo and run mkdir /tmp/test in a new terminal.
[...]
libbpf: CO-RE relocating [11] struct pt_regs: found target candidate [136] struct pt_regs in [vmlinux]
libbpf: prog 'do_mkdirat': relo #0: <byte_off> [11] struct pt_regs.si (0:13 @ offset 104)
libbpf: prog 'do_mkdirat': relo #0: matching candidate #0 <byte_off> [136] struct pt_regs.si (0:13 @ offset 104)
libbpf: prog 'do_mkdirat': relo #0: patched insn #1 (LDX/ST/STX) off 104 -> 104
libbpf: prog 'do_mkdirat': relo #1: <byte_off> [11] struct pt_regs.dx (0:12 @ offset 96)
libbpf: prog 'do_mkdirat': relo #1: matching candidate #0 <byte_off> [136] struct pt_regs.dx (0:12 @ offset 96)
libbpf: prog 'do_mkdirat': relo #1: patched insn #2 (LDX/ST/STX) off 96 -> 96
libbpf: CO-RE relocating [25] struct filename: found target candidate [1410] struct filename in [vmlinux]
libbpf: prog 'do_mkdirat': relo #2: <byte_off> [25] struct filename.name (0:0 @ offset 0)
libbpf: prog 'do_mkdirat': relo #2: matching candidate #0 <byte_off> [1410] struct filename.name (0:0 @ offset 0)
libbpf: prog 'do_mkdirat': relo #2: patched insn #73 (ALU/ALU64) imm 0 -> 0
libbpf: map 'mkdir': created successfully, fd=3
Successfully started! Listening for events...
Process ID: 2416, filename: /tmp/test, mode: 511
Tracing bpf() syscall using strace
[...]
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_PERF_EVENT_ARRAY, key_size=4, value_size=4, max_entries=1024, map_flags=0, inner_map_fd=0, map_name="mkdir", map_ifindex=0, btf_fd=0, btf_key_type_id=0, btf_value_type_id=0, btf_vmlinux_value_type_id=0, map_extra=0}, 80) = 5
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_KPROBE, insn_cnt=96, insns=0x55cbcd994ff0, license="GPL", log_level=0, log_size=0, log_buf=NULL, kern_version=KERNEL_VERSION(6, 12, 12), prog_flags=0, prog_name="do_mkdirat", prog_ifindex=0, expected_attach_type=BPF_CGROUP_INET_INGRESS, prog_btf_fd=4, func_info_rec_size=8, func_info=0x55cbcd9937e0, func_info_cnt=1, line_info_rec_size=16, line_info=0x55cbcd9938c0, line_info_cnt=13, attach_btf_id=0, attach_prog_fd=0, fd_array=NULL}, 148) = 5
This output tells us that there an extra component which is BPF_MAP_CREATE command creating a map of type BPF_MAP_TYPE_PERF_EVENT_ARRAY and map_name is mkdir.
Attaching a kprobe to system call can be done using the same methods or using ksyscall technique with BPF_KSYSCALL macro and ("ksyscall/syscall_name") as section. For example, SEC("ksyscall/execve") as the next example, which we will attach a kprobe to execve syscall using ksyscall. The execve system call is one of the family of exec functions in Unix-like operating systems. It is used to execute a new program by replacing the current process image with a new one. The execve syscall is declared in include/linux/syscalls.h as the following:
asmlinkage long sys_execve(const char __user *filename,
const char __user *const __user *argv,
const char __user *const __user *envp);
asmlinkage: It’s a macro to tell the compile to that arguments are passed on the stack not registers.
const char __user *filename: A pointer to the filename (a user-space string) of the program to execute.
const char __user *const __user *argv: A pointer to an array of pointers (from user space) to the argument strings for the new program.
const char __user *const __user _*envp: A pointer to an array of pointers (from user space) to the environment variables for the new program.
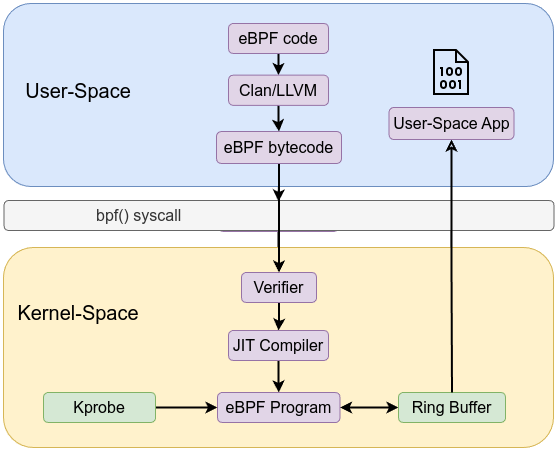
In next example, we will attach kprobe to execve syscall using ksyscall and we will add ring buffer to ship our events to the user-space instead of perf buffer. Ring buffer needs to be defined, reserve then submit your events. The ring buffer minimizes overhead, offering lower latency and better performance for high-frequency event reporting compared to perf buffer mechanism.
Note
In kprobe programs, syscalls and kernel functions follow different ABIs. The syscall ABI defines the transition from user space to kernel space and dictates how its arguments are passed, while the kernel function ABI governs internal calls within the kernel.#define __TARGET_ARCH_x86
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
#include <bpf/bpf_core_read.h>
#define MAX_ARGS 7
#define ARG_SIZE 128
struct event {
__u32 pid;
char path[ARG_SIZE];
char argv[MAX_ARGS][ARG_SIZE];
};
struct {
__uint(type, BPF_MAP_TYPE_RINGBUF);
__uint(max_entries, 1 << 16);
} rb SEC(".maps");
char LICENSE[] SEC("license") = "GPL";
SEC("ksyscall/execve")
int BPF_KSYSCALL(kprobe_sys_execve,
const char *filename,
const char *const *argv)
{
struct event *ev = bpf_ringbuf_reserve(&rb, sizeof(*ev), 0);
if (!ev)
return 0;
ev->pid = bpf_get_current_pid_tgid() >> 32;
bpf_probe_read_user_str(ev->path, sizeof(ev->path), filename);
#pragma unroll
for (int i = 0; i < MAX_ARGS; i++) {
const char *argp = NULL;
bpf_probe_read_user(&argp, sizeof(argp), &argv[i]);
if (!argp) {
break;
}
bpf_probe_read_user_str(ev->argv[i], sizeof(ev->argv[i]), argp);
}
bpf_ringbuf_submit(ev, 0);
return 0;
}
We defined a ring buffer type of map with name rb:
struct {
__uint(type, BPF_MAP_TYPE_RINGBUF);
__uint(max_entries, 1 << 16);
} rb SEC(".maps");
Define a data structure event
struct event {
__u32 pid;
char path[ARG_SIZE];
char argv[MAX_ARGS][ARG_SIZE];
};
We defined section with ksyscall/execve for execve syscall and use BPF_KSYSCALL macro. BPF_KSYSCALL macro defined two arguments of execve syscall instead of three because we only need filename to extract command being executed and argv to get command with its arguments and no need for environment variables.
SEC("ksyscall/execve")
int BPF_KSYSCALL(kprobe_sys_execve,
const char *filename,
const char *const *argv)
{
Then reserve space in eBPF ring buffer using bpf_ringbuf_reserve helper function which has prototype as the following void *bpf_ringbuf_reserve(void *ringbuf, u64 size, u64 flags), it take a pointer to a ring buffer definition as the first argument and the number of bytes to be reserved in the ring buffer as the second argument and returns a valid pointer with size bytes of memory available and flags must be 0.
struct event *ev = bpf_ringbuf_reserve(&rb, sizeof(*ev), 0);
if (!ev)
return 0;
bpf_probe_read_user_str is an eBPF helper function that safely reads a null-terminated string from user-space memory into an eBPF program which has the prototype long bpf_probe_read_user_str(void *dst, u32 size, const void *unsafe_ptr).
bpf_probe_read_user_str(ev->path, sizeof(ev->path), filename);
This will copy the filename into path member of ev structure. The argv parameter is essentially a double pointer or pointer to a pointer (const char __user *const __user *argv), meaning it points to an array of pointers where each element is a pointer to a string. Hence, we first need to copy the pointer itself (to get the address of the string) and then copy the string data from that address. In our code, we copy up to 7 pointers (defined by #define MAX_ARGS 7) from argv into a temporary storage argp and then extract the strings into the argv member of the ev structure.
for (int i = 0; i < MAX_ARGS; i++) {
const char *argp = NULL;
bpf_probe_read_user(&argp, sizeof(argp), &argv[i]);
if (!argp) {
break;
}
bpf_probe_read_user_str(ev->argv[i], sizeof(ev->argv[i]), argp);
}
We could add the #pragma unroll compiler directive to optimize our loop. Loop unrolling duplicates the loop body multiple times, reducing the overhead of loop control by executing multiple iterations’ work within a single loop iteration. For example,
int sum = 0;
int arr[4] = {1, 2, 3, 4};
#pragma unroll
for (int i = 0; i < 4; i++) {
sum += arr[i];
}
After unrolling:
int sum = 0;
int arr[4] = {1, 2, 3, 4};
sum += arr[0];
sum += arr[1];
sum += arr[2];
sum += arr[3];
Then we submit reserved ring buffer data to make it available in the ring buffer using bpf_ringbuf_submit helper function.
void bpf_ringbuf_submit(void *data, u64 flags) It take a pointer to data as the first argument and flag as the second argument and the flag can be as follow:
* If BPF_RB_NO_WAKEUP is specified in flags, no notification of new data availability is sent.
* If BPF_RB_FORCE_WAKEUP is specified in flags, notification of new data availability is sent unconditionally.
* If 0 is specified in flags, an adaptive notification of new data availability is sent.
bpf_ringbuf_submit(ev, 0);
What really happened is that we first reserved a space inside the ring buffer, then write our data into the reserved space and finally we submit to make these data available in the ring buffer.
#include <stdio.h>
#include <unistd.h>
#include <sys/resource.h>
#include <bpf/libbpf.h>
#include <bpf/bpf.h>
#include "ksyscall.skel.h"
#define MAX_ARGS 7
static int libbpf_print_fn(enum libbpf_print_level level, const char *format, va_list args)
{
return vfprintf(stderr, format, args);
}
struct event {
__u32 pid;
char path[128];
char argv[MAX_ARGS][128];
};
static int handle_event(void *ctx, void *data, size_t data_sz)
{
struct event *e = data;
printf("[execve] PID=%d Path=%s\n", e->pid, e->path);
for (int i = 0; i < MAX_ARGS; i++) {
if (e->argv[i][0] == '\0')
break;
printf(" argv[%d] = %s\n", i, e->argv[i]);
}
printf("\n");
return 0;
}
int main(int argc, char **argv)
{
struct ring_buffer *rb = NULL;
struct ksyscall *skel = NULL;
int err;
libbpf_set_print(libbpf_print_fn);
skel = ksyscall__open();
if (!skel) {
fprintf(stderr, "Failed to open BPF skeleton\n");
return 1;
}
err = ksyscall__load(skel);
if (err) {
fprintf(stderr, "Failed to load BPF skeleton: %d\n", err);
goto cleanup;
}
err = ksyscall__attach(skel);
if (err) {
fprintf(stderr, "Failed to attach BPF skeleton: %d\n", err);
goto cleanup;
}
rb = ring_buffer__new(bpf_map__fd(skel->maps.rb), handle_event, NULL, NULL);
if (!rb) {
fprintf(stderr, "Failed to create ring buffer\n");
err = 1;
goto cleanup;
}
printf("Tracing execve calls... Ctrl+C to exit.\n");
while (1) {
err = ring_buffer__poll(rb, 100);
if (err == -EINTR) {
continue;
} else if (err < 0) {
fprintf(stderr, "Error polling ring buffer: %d\n", err);
break;
}
}
cleanup:
ring_buffer__free(rb);
ksyscall__destroy(skel);
return 0;
}
We Initialize rb to hold the ring buffer.
struct ring_buffer *rb = NULL;
ring_buffer__new takes a file descriptor for BPF_MAP_TYPE_RINGBUF and function to invoke on each each received data.
rb = ring_buffer__new(bpf_map__fd(skel->maps.rb), handle_event, NULL, NULL);
Then we retrieve the newly added data to the ring buffer using ring_buffer__poll function which has the following prototype:int ring_buffer__poll (struct ring_buffer *rb, int timeout_ms).
If Positive timeout_ms: Blocks for the specified time (e.g., 100ms). If data arrives within that time, it processes and returns. If no data arrives, it returns 0.
Iftimeout_ms == 0: Non-blocking. Checks immediately for data. Returns 0 if no data is available.
If Negative timeout_ms: Blocks indefinitely until data becomes available.
Compile the code:
sudo bpftool btf dump file /sys/kernel/btf/vmlinux format c > vmlinux.h
clang -g -O2 -target bpf -c ksyscall_execve.bpf.c -o ksyscall.o
sudo bpftool gen skeleton ksyscall.o > ksyscall.skel.h
clang -o loader loader.c -lbpf
sudo ./loader
Executing any commands will trigger the probe such as ls -l /etc:
Tracing execve calls... Ctrl+C to exit.
[execve] PID=2584 Path=/usr/bin/ls
argv[0] = ls
argv[1] = --color=auto
argv[2] = -l
argv[3] = /etc
Examining the code using strace sudo strace -ebpf ./loader
[...]
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_RINGBUF, key_size=0, value_size=0, max_entries=65536, map_flags=0, inner_map_fd=0, map_name="rb", map_ifindex=0, btf_fd=5, btf_key_type_id=0, btf_value_type_id=0, btf_vmlinux_value_type_id=0, map_extra=0}, 80) = 6
[...]
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_KPROBE, insn_cnt=239, insns=0x55f2a2703020, license="GPL", log_level=0, log_size=0, log_buf=NULL, kern_version=KERNEL_VERSION(6, 12, 17), prog_flags=0, prog_name="kprobe_sys_exec", prog_ifindex=0, expected_attach_type=BPF_CGROUP_INET_INGRESS, prog_btf_fd=5, func_info_rec_size=8, func_info=0x55f2a2701810, func_info_cnt=1, line_info_rec_size=16, line_info=0x55f2a2701890, line_info_cnt=115, attach_btf_id=0, attach_prog_fd=0, fd_array=NULL}, 148) = 6
[...]
Shows the program type is indeed BPF_PROG_TYPE_KPROBE and it uses the map type of BPF_MAP_TYPE_RINGBUF.
A similar approach can be used with the kretsyscall with BPF_KRETPROBE macro to capture a syscall’s return value. The following probe will be triggered when execve syscall returns:
define __TARGET_ARCH_x86
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
#include <bpf/bpf_core_read.h>
char LICENSE[] SEC("license") = "GPL";
SEC("kretsyscall/execve")
int BPF_KRETPROBE(kretprobe_sys_execve, int ret)
{
pid_t pid = bpf_get_current_pid_tgid() >> 32;
bpf_printk("Execve return :pid = %d ret = %d\n", pid , ret);
return 0;
}
<...>-1781 [...] bpf_trace_printk: Execve return :pid = 1781 ret = 0
<...>-1782 [...] bpf_trace_printk: Execve return :pid = 1782 ret = 0
<...>-1847 [...] bpf_trace_printk: Execve return :pid = 1847 ret = -2
2 - Uprobes and Uretprobes
Uprobes and uretprobes enable instrumentation of user-space applications in a manner similar to how kprobes and kretprobes instrument kernel functions. Instead of tracing kernel-level routines, uprobes and uretprobes attach to functions (or instructions) within user-space executables and shared libraries. This allows system-wide dynamic instrumentation of user applications, including libraries that are shared among many processes.
Unlike the kprobe interface—where the kernel knows the symbol addresses of kernel functions—uprobes require the user to specify the file path and offset of the instruction(s) or function(s) to probe. The offset is calculated from the start of the executable or library file. Once attached, any process using that binary (including those that start in the future) is instrumented.
Uprobes
A uprobe is placed at a specific instruction in a user-space binary (e.g., a function’s entry point in an application or library). When that instruction executes, the CPU hits a breakpoint, and control is transferred to the kernel’s uprobes framework, which then calls the attached eBPF handler. This handler can inspect arguments (readable from user-space memory), task metadata, and more. uprobe eBPF programs are classified under the program type BPF_PROG_TYPE_KPROBE.
How Uprobes Work Under the Hood
- The user identifies the target function or instruction’s offset from the binary’s start. A breakpoint instruction (similar to kprobe’s approach) is inserted into the user-space code at runtime.
- When a process executes that instruction, a trap occurs, switching to kernel mode where the uprobes framework runs the attached eBPF program.
- The eBPF handler runs in the kernel but can read arguments and other data from user-space memory using
bpf_probe_read_user()or related helpers. After the handler completes, uprobes single-step the replaced instruction and return execution control to user space.
Before uprobe:

After uprobe insertion:
We can get list of all symbols from object or binary files using nm or objdump, for example, to get list of all symbols from /bin/bash all we have to do is nm -D /bin/bash to get dynamic symbols because /bin/bash is stripped of debug symbols, so if you use nm /bin/bash you will get nm: /bin/bash: no symbols.
objdump can extract dynamic symbols using objdump -T /bin/bash. That’s how the output looks in case of nm
[...]
0000000000136828 D shell_builtins
0000000000135cf8 D shell_compatibility_level
000000000013d938 B shell_environment
000000000013da90 B shell_eof_token
0000000000048930 T shell_execve
0000000000131b40 D shell_flags
000000000013f270 B shell_function_defs
000000000013f280 B shell_functions
00000000000839e0 T shell_glob_filename
000000000013d97c B shell_initialized
0000000000032110 T shell_is_restricted
[...]
D or data symbols which represent initialized variable, while B or BSS symbols represent uninitialized global variables and T or text symbols represent code which we are interested in. Let’s attach uprobe to entry point of shell_execve function. shell_execve has a prototype of int shell_execve(char *filename, char **argv, char **envp); which is similar to execve syscall man 2 execve which has this prototype
int execve(const char *pathname, char *const _Nullable argv[],
char *const _Nullable envp[]);
pathname must be either a binary executable, or a script starting with a line of the form:
#!interpreter [optional-arg]
argv is an array of pointers to strings passed to the new program as its command-line ar‐
guments. By convention, the first of these strings (i.e., argv[0]) should contain the
filename associated with the file being executed. The argv array must be terminated by a
null pointer. (Thus, in the new program, argv[argc] will be a null pointer.)
envp is an array of pointers to strings, conventionally of the form key=value, which are
passed as the environment of the new program. The envp array must be terminated by a null
pointer.
Starting with attache uprobe to /bin/bash:shell_execve and extract which command is being executed along with PID and send events to the user-space via ring buffer.
#define __TARGET_ARCH_x86
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
struct event {
pid_t pid;
char command[32];
};
struct {
__uint(type, BPF_MAP_TYPE_RINGBUF);
__uint(max_entries, 4096);
} events SEC(".maps");
char LICENSE[] SEC("license") = "GPL";
SEC("uprobe//bin/bash:shell_execve")
int BPF_UPROBE(uprobe_bash_shell_execve, const char *filename)
{
struct event *evt;
evt = bpf_ringbuf_reserve(&events, sizeof(struct event), 0);
if (!evt)
return 0;
evt->pid = bpf_get_current_pid_tgid() >> 32;
bpf_probe_read_user_str(evt->command, sizeof(evt->command), filename);
bpf_ringbuf_submit(evt, 0);
return 0;
}
We defined a ring buffer type of map with name events
struct {
__uint(type, BPF_MAP_TYPE_RINGBUF);
__uint(max_entries, 4096);
} events SEC(".maps");
Then we used BPF_UPROBE macro which is exactly like BPF_KPROBE which takes the first argument as a name for the function followed by any additional arguments you want to capture.
int BPF_UPROBE(uprobe_bash_shell_execve, const char *filename)
Then reserve space in eBPF ring buffer using bpf_ringbuf_reserve helper function.
evt = bpf_ringbuf_reserve(&events, sizeof(struct event), 0);
Then we copy filename into command member in evt structure.
bpf_probe_read_user_str(evt->command, sizeof(evt->command), filename);
Then we submit evt structure.
bpf_ringbuf_submit(evt, 0);
The user-space code is similar to the one we did before in ksyscall.
#include <stdio.h>
#include <unistd.h>
#include <sys/resource.h>
#include <bpf/libbpf.h>
#include <bpf/bpf.h>
#include "uprobe.skel.h"
static int libbpf_print_fn(enum libbpf_print_level level, const char *format, va_list args)
{
return vfprintf(stderr, format, args);
}
struct event {
pid_t pid;
char command[32];
};
static int handle_event(void *ctx, void *data, size_t data_sz)
{
struct event *evt = (struct event *)data;
printf("Process ID: %d, Command: %s\n", evt->pid, evt->command);
return 0;
}
int main(int argc, char **argv)
{
struct uprobe *skel;
struct ring_buffer *rb = NULL;
int err;
libbpf_set_print(libbpf_print_fn);
skel = uprobe__open();
if (!skel) {
fprintf(stderr, "Failed to open BPF skeleton\n");
return 1;
}
err = uprobe__load(skel);
if (err) {
fprintf(stderr, "Failed to load and verify BPF skeleton\n");
goto cleanup;
}
err = uprobe__attach(skel);
if (err) {
fprintf(stderr, "Failed to attach BPF skeleton\n");
goto cleanup;
}
rb = ring_buffer__new(bpf_map__fd(skel->maps.events), handle_event, NULL, NULL);
if (!rb) {
fprintf(stderr, "Failed to create ring buffer\n");
goto cleanup;
}
printf("Successfully started! Listening for events...\n");
while (1) {
err = ring_buffer__poll(rb, 100);
if (err < 0) {
fprintf(stderr, "Error polling ring buffer\n");
break;
}
}
cleanup:
ring_buffer__free(rb);
uprobe__destroy(skel);
return -err;
}
Let’s compile both codes and run the code
sudo bpftool btf dump file /sys/kernel/btf/vmlinux format c > vmlinux.h
clang -g -O2 -target bpf -c uprobe-shell_execve.bpf.c -o uprobe.o
sudo bpftool gen skeleton uprobe.o > uprobe.skel.h
clang -o loader loader.c -lbpf
sudo ./loader
Open a new terminal and execute bash & then gdb -p PID in my case gdb -p 1923 then disassemble shell_execve and you will get something similar
(gdb) disassemble shell_execve
Dump of assembler code for function shell_execve:
0x00005601e928c930 <+0>: int3
0x00005601e928c931 <+1>: nop %edx
0x00005601e928c934 <+4>: push %r15
0x00005601e928c936 <+6>: push %r14
0x00005601e928c938 <+8>: push %r13
0x00005601e928c93a <+10>: mov %rsi,%r13
0x00005601e928c93d <+13>: push %r12
0x00005601e928c93f <+15>: push %rbp
0x00005601e928c940 <+16>: push %rbx
0x00005601e928c941 <+17>: mov %rdi,%rbx
0x00005601e928c944 <+20>: sub $0xa8,%rsp
0x00005601e928c94b <+27>: mov %fs:0x28,%r14
[...]
Notice int3 at the entry point of shell_execve which is a software breakpoint set by uprobe. You will get also something similar on the loader terminal
libbpf: sec 'uprobe//bin/bash:shell_execve': found 1 CO-RE relocations
libbpf: CO-RE relocating [10] struct pt_regs: found target candidate [136] struct pt_regs in [vmlinux]
libbpf: prog 'uprobe_bash_shell_execve': relo #0: <byte_off> [10] struct pt_regs.di (0:14 @ offset 112)
libbpf: prog 'uprobe_bash_shell_execve': relo #0: matching candidate #0 <byte_off> [136] struct pt_regs.di (0:14 @ offset 112)
libbpf: prog 'uprobe_bash_shell_execve': relo #0: patched insn #0 (LDX/ST/STX) off 112 -> 112
libbpf: map 'events': created successfully, fd=3
libbpf: elf: symbol address match for 'shell_execve' in '/bin/bash': 0x48930
Successfully started! Listening for events...
Process ID: 1923, Command: /usr/bin/bash
Process ID: 1924, Command: /usr/bin/gdb
Running it with strace sudo strace -ebpf ./loader to capture bpf() syscalls shows that the the prog_type is indeed BPF_PROG_TYPE_KPROBE and the prog_name is uprobe_bash_shell_execve and map_type is BPF_MAP_TYPE_RINGBUF.
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_RINGBUF, key_size=0, value_size=0, max_entries=4096, map_flags=0, inner_map_fd=0, map_name="events", map_ifindex=0, btf_fd=4, btf_key_type_id=0, btf_value_type_id=0, btf_vmlinux_value_type_id=0, map_extra=0}, 80) = 5
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_KPROBE, insn_cnt=21, insns=0x55adbd3b0000, license="GPL", log_level=0, log_size=0, log_buf=NULL, kern_version=KERNEL_VERSION(6, 12, 12), prog_flags=0, prog_name="uprobe_bash_shell_execve", prog_ifindex=0, expected_attach_type=BPF_CGROUP_INET_INGRESS, prog_btf_fd=4, func_info_rec_size=8, func_info=0x55adbd3ae7e0, func_info_cnt=1, line_info_rec_size=16, line_info=0x55adbd3ae860, line_info_cnt=10, attach_btf_id=0, attach_prog_fd=0, fd_array=NULL}, 148) = 5
At this point i hope you got that you can uprobe your own code. Compile this code as /tmp/test and compile it gcc -g test.c -o test
#include <stdio.h>
const char* get_message() {
return "got uprobed!!";
}
int main() {
const char* message = get_message();
printf("%s\n", message);
return 0;
}
With eBPF code
#define __TARGET_ARCH_x86
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
char LICENSE[] SEC("license") = "GPL";
SEC("uprobe//tmp/test:get_message")
int BPF_UPROBE(trace_my_function)
{
pid_t pid;
pid = bpf_get_current_pid_tgid() >> 32;
bpf_printk("PID %d \n", pid);
return 0;
}
Then you will get
exam-3142 [003] ...11 17712.082503: bpf_trace_printk: PID 3142
Uretprobes
A uretprobe triggers when a user-space function returns. Just like kretprobes, uretprobes replace the function’s return address with a trampoline so that when the function completes, execution hits the trampoline first—invoking the eBPF return handler before returning to the actual caller. uprobe eBPF programs are also classified under the program type BPF_PROG_TYPE_KPROBE.
How Uretprobes Work Under the Hood
- When you register a uretprobe, a corresponding uprobe is placed at the function’s entry to record the return address and replace it with a trampoline.
- At function entry, the uprobe saves the original return address and sets the trampoline address. An optional entry handler can run here, deciding if we should track this particular instance.
- When the function returns, instead of going directly back to the caller, it hits the trampoline. The trampoline has its own probe, triggering the uretprobe handler. The handler can read the function’s return value, gather timing information, or finalize any data collected at entry.
- The original return address is restored, and the application continues execution as if nothing happened.
Before uretprobe:

After uretprobe installation:
The readline function in bash reads the user’s input from the terminal and returns a pointer to the string containing the text of the line read. Its prototype is:
char *readline (const char *prompt);. You can use eBPF to capture or record the user input in bash by hooking into the return of the readline function.
#define __TARGET_ARCH_x86
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
struct event {
pid_t pid;
char command[64];
};
struct {
__uint(type, BPF_MAP_TYPE_RINGBUF);
__uint(max_entries, 2048);
} events SEC(".maps");
char LICENSE[] SEC("license") = "GPL";
SEC("uretprobe//bin/bash:readline")
int BPF_URETPROBE(uretprobe_readline, const void *ret)
{
struct event *evt;
evt = bpf_ringbuf_reserve(&events, sizeof(struct event), 0);
if (!evt)
return 0;
evt->pid = bpf_get_current_pid_tgid() >> 32;
bpf_probe_read_user_str(evt->command, sizeof(evt->command), ret);
bpf_ringbuf_submit(evt, 0);
return 0;
};
Successfully started! Listening for events...
Process ID: 1859, Command: cat /etc/passwd
Process ID: 1859, Command: cat /etc/issue.net
Process ID: 1859, Command: ls -l
Note
Uprobes can add overhead, especially when targeting high-frequency user-space functions (like malloc()). The overhead can compound significantly if millions of events occur per second, potentially causing a noticeable slowdown in the application. Consider carefully which user-space functions to instrument and apply uprobes selectively, possibly in a test environment or only when diagnosing severe issues.Let’s walk through some advanced examples: we will demonstrate how to capture the password entered in PAM and how to observe decrypted traffic without needing CA certificates, all using uprobes.
PAM (Pluggable Authentication Modules) is a framework that offers a modular approach to authentication, making it easier to manage and secure the login process. During authentication, the pam_get_user function is responsible for obtaining the username from the session, while pam_get_authtok retrieves the corresponding password or token, ensuring that each step is handled securely and flexibly.
The function prototype for pam_get_authtok is:
int pam_get_authtok(pam_handle_t *pamh, int item,
const char **authtok, const char *prompt);
According to the man page, this function returns the cached authentication token (for example, a password) if one is available, or it prompts the user to enter one if no token is cached. Upon successful return, the **authtok parameter will point to the value of the authentication token. This function is intended for internal use by Linux-PAM and PAM service modules.
The prototype for pam_get_user is:
int pam_get_user(const pam_handle_t *pamh, const char **user, const char *prompt);
The pam_get_user function returns the name of the user specified by the pam_start function, which is responsible for creating the PAM context and initiating the PAM transaction. A pointer to the username is then returned as the contents of *user.
Note
Please note that both**authtok in pam_get_authtok and **user in pam_get_user are pointers to pointers.
To capture the password, we need to attach uprobe to libpam /lib/x86_64-linux-gnu/libpam.so.0:pam_get_authtok at the entry point and exit point, why entry point and exit point, short answer is that in pam_get_authtok the password pointer (**authtok) isn’t fully assigned or valid at the start of the function. Instead, the function fills in that pointer somewhere inside (for example, prompting the user or retrieving from memory), so by the time the function returns, the pointer (and thus the password string) is set. Hence, a uretprobe (return probe) is the only reliable place to grab the final pointer to the password.
The same goes for capturing the user, we need to attach uprobe to libpam /lib/x86_64-linux-gnu/libpam.so.0:pam_get_user at the entry point and exit point.
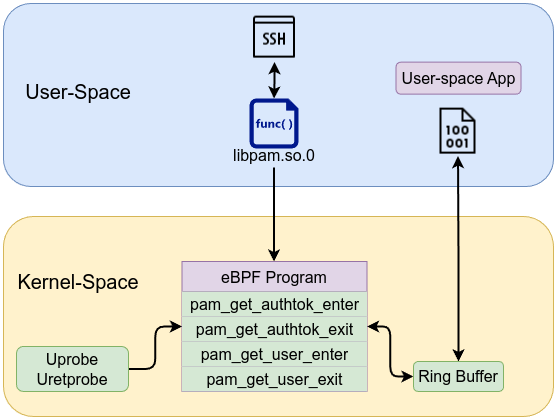
#define __TARGET_ARCH_x86
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
#include <bpf/bpf_core_read.h>
#define MAX_PW_LEN 128
#define MAX_USER_LEN 64
char LICENSE[] SEC("license") = "GPL";
struct event {
int pid;
char comm[16];
char password[MAX_PW_LEN];
char username[MAX_USER_LEN];
};
struct {
__uint(type, BPF_MAP_TYPE_RINGBUF);
__uint(max_entries, 4096);
} events SEC(".maps");
struct {
__uint(type, BPF_MAP_TYPE_HASH);
__uint(max_entries, 1024);
__type(key, __u32);
__type(value, __u64);
} authtok_ptrs SEC(".maps");
struct {
__uint(type, BPF_MAP_TYPE_HASH);
__uint(max_entries, 1024);
__type(key, __u32);
__type(value, __u64);
} user_ptrs SEC(".maps");
SEC("uprobe//lib/x86_64-linux-gnu/libpam.so.0:pam_get_authtok")
int BPF_UPROBE(pam_get_authtok_enter,
void *pamh,
int item,
const char **authtok,
const char *prompt)
{
pid_t pid = bpf_get_current_pid_tgid() >> 32;
__u64 atok_ptr = (unsigned long)authtok;
bpf_map_update_elem(&authtok_ptrs, &pid, &atok_ptr, BPF_ANY);
return 0;
}
SEC("uretprobe//lib/x86_64-linux-gnu/libpam.so.0:pam_get_authtok")
int BPF_URETPROBE(pam_get_authtok_exit)
{
pid_t pid = bpf_get_current_pid_tgid() >> 32;
int ret = PT_REGS_RC(ctx);
__u64 *stored = bpf_map_lookup_elem(&authtok_ptrs, &pid);
if (!stored)
return 0;
bpf_map_delete_elem(&authtok_ptrs, &pid);
if (ret != 0)
return 0;
__u64 atok_addr = 0;
bpf_probe_read_user(&atok_addr, sizeof(atok_addr), (const void *)(*stored));
if (!atok_addr)
return 0;
struct event *evt = bpf_ringbuf_reserve(&events, sizeof(struct event), 0);
if (!evt)
return 0;
evt->pid = pid;
bpf_get_current_comm(&evt->comm, sizeof(evt->comm));
bpf_probe_read_user(evt->password, sizeof(evt->password), (const void *)atok_addr);
bpf_ringbuf_submit(evt, 0);
return 0;
}
SEC("uprobe//lib/x86_64-linux-gnu/libpam.so.0:pam_get_user")
int BPF_UPROBE(pam_get_user_enter,
void *pamh,
const char **user,
const char *prompt)
{
pid_t pid = bpf_get_current_pid_tgid() >> 32;
__u64 user_ptr = (unsigned long)user;
bpf_map_update_elem(&user_ptrs, &pid, &user_ptr, BPF_ANY);
return 0;
}
SEC("uretprobe//lib/x86_64-linux-gnu/libpam.so.0:pam_get_user")
int BPF_URETPROBE(pam_get_user_exit)
{
pid_t pid = bpf_get_current_pid_tgid() >> 32;
int ret = PT_REGS_RC(ctx);
__u64 *stored = bpf_map_lookup_elem(&user_ptrs, &pid);
if (!stored)
return 0;
bpf_map_delete_elem(&user_ptrs, &pid);
if (ret != 0)
return 0;
__u64 user_addr = 0;
bpf_probe_read_user(&user_addr, sizeof(user_addr), (const void *)(*stored));
if (!user_addr)
return 0;
struct event *evt = bpf_ringbuf_reserve(&events, sizeof(struct event), 0);
if (!evt)
return 0;
evt->pid = pid;
bpf_get_current_comm(&evt->comm, sizeof(evt->comm));
bpf_probe_read_user(evt->username, sizeof(evt->username), (const void *)user_addr);
bpf_ringbuf_submit(evt, 0);
return 0;
}
First, we defined struct event and then created two BPF_MAP_TYPE_HASH maps to process and hold the username and password passed by the functions. Since **authtok and **user are pointers to pointers, we need to call bpf_probe_read_user twice to correctly read the values.
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <errno.h>
#include <signal.h>
#include <stdarg.h>
#include <bpf/libbpf.h>
#include <bpf/bpf.h>
#include "pamcapture.skel.h"
#define MAX_PW_LEN 128
struct event {
int pid;
char comm[16];
char password[MAX_PW_LEN];
char username[64];
};
static int handle_event(void *ctx, void *data, size_t data_sz)
{
struct event *evt = data;
printf("\n---- PAM Password capture ----\n");
if (evt->username[0] == '\0') {
printf("\n---- PAM Password captured ----\n");
printf("PID: %d, COMM: %.*s, Password: %s\n", evt->pid, 16, evt->comm, evt->password);
} else {
printf("\n---- PAM Uusername capture ----\n");
printf("PID: %d, username = %s\n", evt->pid,evt->username);
}
return 0;
}
static int libbpf_print_fn(enum libbpf_print_level level, const char *format, va_list args)
{
return vfprintf(stderr, format, args);
}
int main(int argc, char **argv)
{
struct pamcapture *skel = NULL;
struct ring_buffer *rb = NULL;
int err;
libbpf_set_print(libbpf_print_fn);
skel = pamcapture__open();
if (!skel) {
fprintf(stderr, "Failed to open BPF skeleton\n");
return 1;
}
err = pamcapture__load(skel);
if (err) {
fprintf(stderr, "Failed to load and verify BPF skeleton\n");
goto cleanup;
}
err = pamcapture__attach(skel);
if (err) {
fprintf(stderr, "Failed to attach BPF skeleton\n");
goto cleanup;
}
rb = ring_buffer__new(bpf_map__fd(skel->maps.events), handle_event, NULL, NULL);
if (!rb) {
fprintf(stderr, "Failed to create ring buffer\n");
goto cleanup;
}
printf("PAM password capture attached! Press Ctrl-C to exit.\n");
while (1) {
err = ring_buffer__poll(rb, 100);
if (err < 0) {
fprintf(stderr, "Error polling ring buffer\n");
break;
}
}
cleanup:
ring_buffer__free(rb);
pamcapture__destroy(skel);
return err < 0 ? -err : 0;
}
The output should be similar to the following
PAM password capture attached! Press Ctrl-C to exit.
---- PAM Uusername capture ----
PID: 2663, username = test
---- PAM Password captured ----
PID: 2663, COMM: sshd-session, Password: admin
Let’s explore another example to show you the power of uprobe/uretprobe. Libssl is a core component of the OpenSSL library, providing implementations of the Secure Sockets Layer (SSL) and Transport Layer Security (TLS) protocols to enable secure communications over network by encrypting data. You can check the list of all functions by executing command like nm on /lib/x86_64-linux-gnu/libssl.so.3 or whatever libssl version you have. Couple of its core functions are SSL_read and SSL_write. SSL_read reads data from an SSL/TLS connection, decrypting it and storing the result in the buffer pointed to by buf. Here, buf is a pointer to user-space memory where the decrypted data is written. SSL_read has a prototype of:
int SSL_read(SSL *ssl, void *buf, int num);
SSL_write function writes data to an SSL/TLS connection by encrypting the content of the buffer pointed to by buf and transmitting it. In this case, buf is a pointer to the user-space memory containing the plaintext data that will be encrypted. SSL_write has a prototype of:
int SSL_write(SSL *ssl, const void *buf, int num);
Uprobes let you intercept user-space function calls at runtime. By attaching them to libssl’s SSL_read and SSL_write, you capture data after it’s decrypted (or before it’s encrypted) inside the process memory. This means you get the plaintext data directly, without needing to use a CA to decrypt network traffic.
To capture decrypted traffic for both ways (send and receive ), we need to attach uprobe at the entry point and the exit point for each function. You need to attach a probe at the entry point to capture the buffer pointer (the address of buf) as soon as the function is called, because that pointer is passed as an argument. Then, attaching a probe at the exit point lets you read the final data from that buffer after the function has processed it.
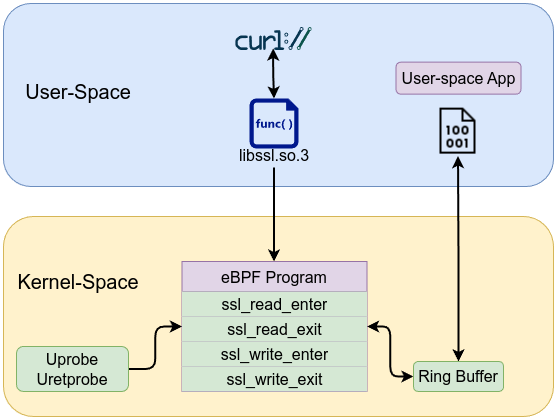
The curl command on my ubuntu box is version 8.5.0 which still uses libssl
curl -V
curl 8.5.0 (x86_64-pc-linux-gnu) libcurl/8.5.0 OpenSSL/3.0.13 zlib/1.3 brotli/1.1.0 zstd/1.5.5 libidn2/2.3.7 libpsl/0.21.2 (+libidn2/2.3.7) libssh/0.10.6/openssl/zlib nghttp2/1.59.0 librtmp/2.3 OpenLDAP/2.6.7
[...]
ldd /usr/bin/curl
[...]
libssl.so.3 => /lib/x86_64-linux-gnu/libssl.so.3 (0x00007a1b58443000)
[...]
Let’s see the kernel code:
#define __TARGET_ARCH_x86
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
#include <bpf/bpf_core_read.h>
#define MAX_BUF_SIZE 4096
char LICENSE[] SEC("license") = "GPL";
enum STATE {
STATE_READ = 0,
STATE_WRITE = 1,
};
struct data {
enum STATE STATE;
int len;
char comm[16];
char buf[MAX_BUF_SIZE];
};
struct {
__uint(type, BPF_MAP_TYPE_RINGBUF);
__uint(max_entries, 1 << 24);
} events SEC(".maps");
struct {
__uint(type, BPF_MAP_TYPE_HASH);
__uint(max_entries, 1024);
__type(key, __u32);
__type(value, __u64);
} buffers SEC(".maps");
static __always_inline __u32 get_tgid(void)
{
return (__u32)bpf_get_current_pid_tgid();
}
static int ssl_exit(struct pt_regs *ctx, enum STATE STATE)
{
__u32 tgid = get_tgid();
int ret = PT_REGS_RC(ctx);
if (ret <= 0) {
bpf_map_delete_elem(&buffers, &tgid);
return 0;
}
__u64 *bufp = bpf_map_lookup_elem(&buffers, &tgid);
if (!bufp) {
return 0;
}
if (*bufp == 0) {
bpf_map_delete_elem(&buffers, &tgid);
return 0;
}
struct data *data = bpf_ringbuf_reserve(&events, sizeof(*data), 0);
if (!data)
return 0;
data->STATE = STATE;
data->len = ret;
bpf_get_current_comm(&data->comm, sizeof(data->comm));
int err = bpf_probe_read_user(data->buf, sizeof(data->buf), (void *)(*bufp));
if (err) {
bpf_map_delete_elem(&buffers, &tgid);
bpf_ringbuf_submit(data, 0);
return 0;
}
bpf_map_delete_elem(&buffers, &tgid);
bpf_ringbuf_submit(data, 0);
return 0;
}
SEC("uprobe//lib/x86_64-linux-gnu/libssl.so.3:SSL_read")
int BPF_UPROBE(ssl_read_enter, void *ssl, void *buf, int num)
{
__u32 tgid = get_tgid();
bpf_map_update_elem(&buffers, &tgid, &buf, BPF_ANY);
return 0;
}
SEC("uretprobe//lib/x86_64-linux-gnu/libssl.so.3:SSL_read")
int BPF_URETPROBE(ssl_read_exit)
{
return ssl_exit(ctx, STATE_READ);
}
SEC("uprobe//lib/x86_64-linux-gnu/libssl.so.3:SSL_write")
int BPF_UPROBE(ssl_write_enter, void *ssl, const void *buf, int num)
{
__u32 tgid = get_tgid();
bpf_map_update_elem(&buffers, &tgid, &buf, BPF_ANY);
return 0;
}
SEC("uretprobe//lib/x86_64-linux-gnu/libssl.so.3:SSL_write")
int BPF_URETPROBE(ssl_write_exit)
{
return ssl_exit(ctx, STATE_WRITE);
}
The ssl_exit function retrieves the return value to determine if any data was processed and then uses the process ID (tgid) to look up the previously stored user-space buffer pointer. The function then reserves an event structure from the ring buffer, reads the actual data from user memory using bpf_probe_read_user, and finally submits the event while cleaning up the stored pointer from the BPF hash map.
Note
The__always_inline macros is used to tell the compiler to inline a function.This means that rather than generating a normal function call, the compiler inserts the body of the function directly into the calling code.
The user-space code:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/resource.h>
#include <bpf/libbpf.h>
#include <bpf/bpf.h>
#include "sslsniff.skel.h"
#define MAX_BUF_SIZE 4096
enum STATE {
STATE_READ = 0,
STATE_WRITE = 1,
};
struct data {
enum STATE STATE;
int len;
char comm[16];
char buf[MAX_BUF_SIZE];
};
static int libbpf_print_fn(enum libbpf_print_level level, const char *format, va_list args)
{
return vfprintf(stderr, format, args);
}
static int handle_event(void *ctx, void *data, size_t data_sz)
{
struct data *evt = data;
int data_len = evt->len < MAX_BUF_SIZE ? evt->len : MAX_BUF_SIZE;
const char *dir_str = (evt->STATE == STATE_WRITE) ? "SEND" : "RECV";
printf("\n--- Perf Event ---\n");
printf("Process: %s, Type: %d, Bytes: %d\n", evt->comm, dir_str, evt->len);
printf("Data (first %d bytes):\n", data_len);
fwrite(evt->buf, 1, data_len, stdout);
return 0;
}
int main(int argc, char **argv)
{
struct sslsniff *skel = NULL;
struct ring_buffer *rb = NULL;
int err;
libbpf_set_print(libbpf_print_fn);
skel = sslsniff__open();
if (!skel) {
fprintf(stderr, "Failed to open BPF skeleton\n");
return 1;
}
err = sslsniff__load(skel);
if (err) {
fprintf(stderr, "Failed to load and verify BPF skeleton\n");
goto cleanup;
}
err = sslsniff__attach(skel);
if (err) {
fprintf(stderr, "Failed to attach BPF skeleton\n");
goto cleanup;
}
rb = ring_buffer__new(bpf_map__fd(skel->maps.events), handle_event, NULL, NULL);
if (!rb) {
fprintf(stderr, "Failed to create ring buffer\n");
goto cleanup;
}
printf("libssl sniffer attached. Press Ctrl+C to exit.\n");
while (1) {
err = ring_buffer__poll(rb, 100);
if (err < 0) {
fprintf(stderr, "Error polling ring buffer\n");
break;
}
}
cleanup:
ring_buffer__free(rb);
sslsniff__destroy(skel);
return err < 0 ? -err : 0;
}
Running curl command curl https://www.hamza-megahed.com/robots.txt --http1.1 and we will get a similar traffic to the following:
--- Perf Event ---
Process: curl, Type: SEND, Bytes: 94
Data (first 94 bytes):
GET /robots.txt HTTP/1.1
Host: www.hamza-megahed.com
User-Agent: curl/8.5.0
Accept: */*
--- Perf Event ---
Process: curl, Type: RECV, Bytes: 1172
Data (first 1172 bytes):
HTTP/1.1 200 OK
Date: Sun, 02 Mar 2025 20:57:27 GMT
Content-Type: text/plain
Content-Length: 66
[...]
User-agent: *
Sitemap: https://www.hamza-megahed.com/sitemap.xml
As you can see, the traffic is decrypted!
Now let’s do the same to GnuTLS which has two functions gnutls_record_recv and gnutls_record_send
GnuTLS is a secure communications library that implements TLS/SSL protocols. Two core functions in this library are: gnutls_record_recv with prototype:
ssize_t gnutls_record_recv(gnutls_session_t session, void *data, size_t data_size);
gnutls_record_recv function receives an encrypted record from a GnuTLS session, decrypts it, and writes the resulting plaintext into the user-provided buffer pointed to by data.
Function gnutls_record_send with prototype
ssize_t gnutls_record_send(gnutls_session_t session, const void *data, size_t data_size);
gnutls_record_send function takes plaintext data from the user-provided buffer pointed to by data, encrypts it, and sends it over the network as an encrypted record.
I have another box with curl version 8.12.1
curl 8.12.1 (x86_64-pc-linux-gnu) libcurl/8.12.1 GnuTLS/3.8.9 zlib/1.3.1 brotli/1.1.0 zstd/1.5.6 libidn2/2.3.7 libpsl/0.21.2 libssh2/1.11.1 nghttp2/1.64.0 ngtcp2/1.9.1 nghttp3/1.6.0 librtmp/2.3 OpenLDAP/2.6.9
Release-Date: 2025-02-13, security patched: 8.12.1-2
The location of libgnutls linked to curl command can be obtained by running ldd /usr/bin/curl
libgnutls.so.30 => /lib/x86_64-linux-gnu/libgnutls.so.30 (0x00007f82da200000)
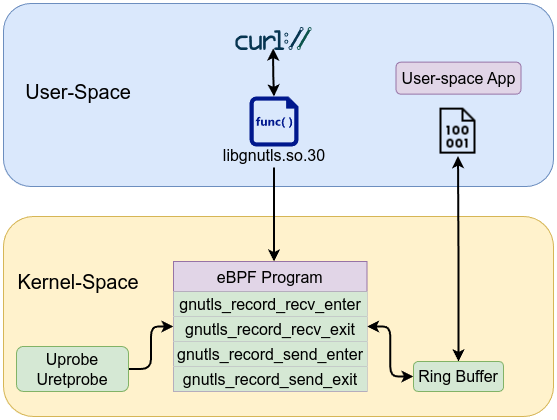
To capture the decrypted or plaintext data processed by these functions, you need to attach uprobes at both the entry and exit points of each function. Attaching a probe at the entry captures the buffer pointer as it is passed to the function, while attaching a probe at the exit allows you to read the final processed data from that buffer once the function has completed its work.
#define __TARGET_ARCH_x86
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
#include <bpf/bpf_core_read.h>
#define MAX_BUF_SIZE 4096
char LICENSE[] SEC("license") = "GPL";
enum STATE {
STATE_READ = 0,
STATE_WRITE = 1,
};
struct data {
enum STATE STATE;
int len;
char comm[16];
char buf[MAX_BUF_SIZE];
};
struct {
__uint(type, BPF_MAP_TYPE_RINGBUF);
__uint(max_entries, 1 << 24);
} events SEC(".maps");
struct {
__uint(type, BPF_MAP_TYPE_HASH);
__uint(max_entries, 1024);
__type(key, __u32);
__type(value, __u64);
} buffers SEC(".maps");
static __always_inline __u32 get_tgid(void)
{
return (__u32)bpf_get_current_pid_tgid();
}
static int record_exit(struct pt_regs *ctx, enum STATE STATE)
{
__u32 tgid = get_tgid();
int ret = PT_REGS_RC(ctx);
if (ret <= 0) {
bpf_map_delete_elem(&buffers, &tgid);
return 0;
}
__u64 *bufp = bpf_map_lookup_elem(&buffers, &tgid);
if (!bufp) {
return 0;
}
if (*bufp == 0) {
bpf_map_delete_elem(&buffers, &tgid);
return 0;
}
struct data *data = bpf_ringbuf_reserve(&events, sizeof(*data), 0);
if (!data)
return 0;
data->STATE = STATE;
data->len = ret;
bpf_get_current_comm(&data->comm, sizeof(data->comm));
int err = bpf_probe_read_user(data->buf, sizeof(data->buf), (void *)(*bufp));
if (err) {
bpf_map_delete_elem(&buffers, &tgid);
bpf_ringbuf_submit(data, 0);
return 0;
}
bpf_map_delete_elem(&buffers, &tgid);
bpf_ringbuf_submit(data, 0);
return 0;
}
SEC("uprobe//lib/x86_64-linux-gnu/libgnutls.so.30:gnutls_record_recv")
int BPF_UPROBE(gnutls_record_recv_enter, void *session, void *data, size_t sizeofdata)
{
__u32 tgid = get_tgid();
bpf_map_update_elem(&buffers, &tgid, &data, BPF_ANY);
return 0;
}
SEC("uretprobe//lib/x86_64-linux-gnu/libgnutls.so.30:gnutls_record_recv")
int BPF_URETPROBE(gnutls_record_recv_exit)
{
return record_exit(ctx, STATE_READ);
}
SEC("uprobe//lib/x86_64-linux-gnu/libgnutls.so.30:gnutls_record_send")
int BPF_UPROBE(gnutls_record_send_enter, void *session, const void *data, size_t sizeofdata)
{
__u32 tgid = get_tgid();
bpf_map_update_elem(&buffers, &tgid, &data, BPF_ANY);
return 0;
}
SEC("uretprobe//lib/x86_64-linux-gnu/libgnutls.so.30:gnutls_record_send")
int BPF_URETPROBE(gnutls_record_send_exit)
{
return record_exit(ctx, STATE_WRITE);
}
The user-space code:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/resource.h>
#include <bpf/libbpf.h>
#include <bpf/bpf.h>
#include "gnutls_sniffer.skel.h"
#define MAX_BUF_SIZE 4096
enum STATE {
STATE_READ = 0,
STATE_WRITE = 1,
};
struct data {
enum STATE STATE;
int len;
char comm[16];
char buf[MAX_BUF_SIZE];
};
static int libbpf_print_fn(enum libbpf_print_level level, const char *format, va_list args)
{
return vfprintf(stderr, format, args);
}
static int handle_event(void *ctx, void *data, size_t data_sz)
{
struct data *evt = data;
int data_len = evt->len < MAX_BUF_SIZE ? evt->len : MAX_BUF_SIZE;
const char *dir_str = (evt->STATE == STATE_WRITE) ? "SEND" : "RECV";
printf("\n--- Perf Event ---\n");
printf("Process: %s, Type: %s, Bytes: %d\n", evt->comm, dir_str, evt->len);
printf("Data (first %d bytes):\n", data_len);
fwrite(evt->buf, 1, data_len, stdout);
return 0;
}
int main(int argc, char **argv)
{
struct gnutls_sniffer *skel = NULL;
struct ring_buffer *rb = NULL;
int err;
skel = gnutls_sniffer__open();
if (!skel) {
fprintf(stderr, "Failed to open BPF skeleton\n");
return 1;
}
err = gnutls_sniffer__load(skel);
if (err) {
fprintf(stderr, "Failed to load/verify BPF skeleton: %d\n", err);
goto cleanup;
}
err = gnutls_sniffer__attach(skel);
if (err) {
fprintf(stderr, "Failed to attach BPF skeleton: %d\n", err);
goto cleanup;
}
rb = ring_buffer__new(bpf_map__fd(skel->maps.events), handle_event, NULL, NULL);
if (!rb) {
err = -errno;
fprintf(stderr, "Failed to create ring buffer: %d\n", err);
goto cleanup;
}
printf("GnuTLS sniffer attached. Press Ctrl+C to exit.\n");
while (1) {
err = ring_buffer__poll(rb, 100);
if (err < 0) {
fprintf(stderr, "Error polling ring buffer\n");
break;
}
}
cleanup:
ring_buffer__free(rb);
gnutls_sniffer__destroy(skel);
return err < 0 ? -err : 0;
}
Same results
GnuTLS sniffer attached. Press Ctrl+C to exit.
--- Perf Event ---
Process: curl, Type: SEND, Bytes: 95
Data (first 95 bytes):
GET /robots.txt HTTP/1.1
Host: www.hamza-megahed.com
User-Agent: curl/8.12.1
Accept: */*
--- Perf Event ---
Process: curl, Type: RECV, Bytes: 1174
Data (first 1174 bytes):
HTTP/1.1 200 OK
Date: Sun, 02 Mar 2025 21:34:37 GMT
[...]
User-agent: *
Sitemap: https://www.hamza-megahed.com/sitemap.xml
3 - Tracepoints
Tracepoints are static instrumentation points compiled into the kernel at code locations chosen by kernel developers. They are placed in meaningful logical places in the code—such as the allocation of memory, the scheduling of tasks, or network packet events—so that when enabled, they can provide consistent and stable data about kernel events. Unlike kprobes, which dynamically instrument arbitrary functions at runtime, tracepoints are predefined by the kernel and remain stable across kernel versions. This makes them a preferred interface whenever a suitable tracepoint is available for the event you are interested in. Tracepoint eBPF programs are classified under the program type BPF_PROG_TYPE_TRACEPOINT.
How Tracepoints Work Under the Hood
- At compile time, each tracepoint location in the kernel is reserved with a 5-byte NOP (on x86_64).
- At runtime, if a tracepoint is enabled, the 5-byte NOP is patched into a 5-byte jump to the trampoline.
- When the tracepoint is disabled (or the last callback is removed), the jump is reverted back to NOP, keeping overhead minimal.
Disabled tracepoint

Enabled tracepoint:
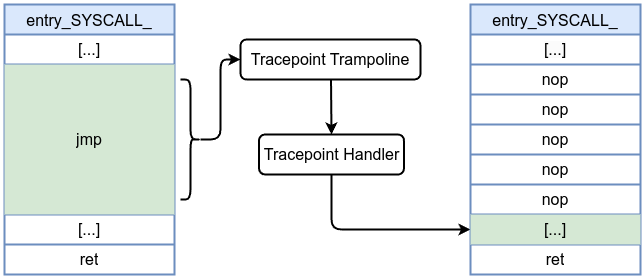
To list all available tracepoints in a Linux system, you can use either sudo bpftrace -l 'tracepoint:*' or sudo ls /sys/kernel/debug/tracing/events/ directory or /sys/kernel/tracing/available_events file which contains a list of all available tracepoints on the system. The SEC name usually follows the format tracepoint__<category>__<name>, for example, SEC("tracepoint/syscalls/sys_enter_unlinkat"). Similarly, the context structure for tracepoints typically follows the naming convention trace_event_raw_<name> (e.g., trace_event_raw_sys_enter and trace_event_raw_sys_exit).
However, there are exceptions. For instance, in the libbpf-bootstrap example, you’ll find:
SEC("tp/sched/sched_process_exit")
int handle_exit(struct trace_event_raw_sched_process_template *ctx)
Here, the context name should be trace_event_raw_sched_process_exit rather than trace_event_raw_sched_process_template. You can verify the correct context by checking the vmlinux.h file.
Let’s explore one of the defined tracepoints from the kernel source code include/trace/events/net.h:
DECLARE_EVENT_CLASS(net_dev_template,
TP_PROTO(struct sk_buff *skb),
TP_ARGS(skb),
TP_STRUCT__entry(
__field( void *, skbaddr )
__field( unsigned int, len )
__string( name, skb->dev->name )
),
TP_fast_assign(
__entry->skbaddr = skb;
__entry->len = skb->len;
__assign_str(name);
),
TP_printk("dev=%s skbaddr=%p len=%u",
__get_str(name), __entry->skbaddr, __entry->len)
)
DEFINE_EVENT(net_dev_template, net_dev_queue,
TP_PROTO(struct sk_buff *skb),
TP_ARGS(skb)
);
DEFINE_EVENT(net_dev_template, netif_receive_skb,
TP_PROTO(struct sk_buff *skb),
TP_ARGS(skb)
);
DEFINE_EVENT(net_dev_template, netif_rx,
TP_PROTO(struct sk_buff *skb),
TP_ARGS(skb)
);
Tracepoints are defined using macros like DECLARE_EVENT_CLASS and DEFINE_EVENT. For example, netif_rx is defined as a trace event that logs information about received packets.
DEFINE_EVENT(net_dev_template, netif_rx,
TP_PROTO(struct sk_buff *skb),
TP_ARGS(skb)
);
In net/core/dev.c, inside the netif_rx_internal() function:
static int netif_rx_internal(struct sk_buff *skb)
{
int ret;
net_timestamp_check(READ_ONCE(net_hotdata.tstamp_prequeue), skb);
trace_netif_rx(skb);
#ifdef CONFIG_RPS
if (static_branch_unlikely(&rps_needed)) {
struct rps_dev_flow voidflow, *rflow = &voidflow;
int cpu;
rcu_read_lock();
cpu = get_rps_cpu(skb->dev, skb, &rflow);
if (cpu < 0)
cpu = smp_processor_id();
ret = enqueue_to_backlog(skb, cpu, &rflow->last_qtail);
rcu_read_unlock();
[...]
You can see trace_netif_rx(skb);. This call triggers the tracepoint event for packet reception which logs the event if tracing is enabled.
Then by running gdb /usr/lib/debug/boot/vmlinux-$(uname -r)
(gdb) disassemble netif_rx_internal
Dump of assembler code for function netif_rx_internal:
0xffffffff81a23d70 <+0>: call 0xffffffff8108d360 <__fentry__>
0xffffffff81a23d75 <+5>: push %rbx
0xffffffff81a23d76 <+6>: sub $0x18,%rsp
0xffffffff81a23d7a <+10>: mov %gs:0x28,%rbx
0xffffffff81a23d83 <+19>: mov %rbx,0x10(%rsp)
0xffffffff81a23d88 <+24>: mov %rdi,%rbx
0xffffffff81a23d8b <+27>: xchg %ax,%ax
0xffffffff81a23d8d <+29>: nopl 0x0(%rax,%rax,1)
0xffffffff81a23d92 <+34>: xchg %ax,%ax
0xffffffff81a23d94 <+36>: mov %gs:0x7e611471(%rip),%esi # 0x3520c <pcpu_hot+12>
0xffffffff81a23d9b <+43>: mov %rbx,%rdi
0xffffffff81a23d9e <+46>: lea 0x8(%rsp),%rdx
0xffffffff81a23da3 <+51>: call 0xffffffff81a239e0 <enqueue_to_backlog>
0xffffffff81a23da8 <+56>: mov %eax,%ebx
[...]
The disassembly confirms that at address <+29> you see a reserved 5-byte NOP (shown as nopl 0x0(%rax,%rax,1)). This placeholder is exactly what the kernel uses for its dynamic patching mechanism—when the tracepoint (or static call) is enabled, that NOP will be patched into a jump to the corresponding trampoline (and ultimately to the tracepoint handler).
In the next example, we will examine unlinkat syscall entry point (which removes a directory entry relative to a directory file descriptor) with context trace_event_raw_sys_enter , but what exactly is the content of struct trace_event_raw_sys_enter. We can get the content by searching the vmlinux.h
struct trace_event_raw_sys_enter {
struct trace_entry ent;
long int id;
long unsigned int args[6];
char __data[0];
};
Using trace_event_raw_sys_enter as context supports BTF. You can also define the context by using the old approach by defining a structure matching the same parameters defined in the format file. For example, for the unlinkat syscall, this file is located at /sys/kernel/debug/tracing/events/syscalls/sys_enter_unlinkat/format which has the following content
name: sys_enter_unlinkat
ID: 849
format:
field:unsigned short common_type; offset:0; size:2; signed:0;
field:unsigned char common_flags; offset:2; size:1; signed:0;
field:unsigned char common_preempt_count; offset:3; size:1; signed:0;
field:int common_pid; offset:4; size:4; signed:1;
field:int __syscall_nr; offset:8; size:4; signed:1;
field:int dfd; offset:16; size:8; signed:0;
field:const char * pathname; offset:24; size:8; signed:0;
field:int flag; offset:32; size:8; signed:0;
print fmt: "dfd: 0x%08lx, pathname: 0x%08lx, flag: 0x%08lx", ((unsigned long)(REC->dfd)), ((unsigned long)(REC->pathname)), ((unsigned long)(REC->flag))
Based on this information, we can deduce that the corresponding structure looks like the following:
struct trace_event_raw_sys_enter_unlinkat {
long dfd;
long pathname_ptr;
long flag;
};
Then the program can use a pointer of type of that structure as context as in int trace_unlinkat(struct trace_event_raw_sys_enter_unlinkat* ctx) However, this approach is not ideal at all for portability.
If we look at the prototype int unlinkat(int dirfd, const char *pathname, int flags); which takes the following parameters:
dirfd: This is a directory file descriptor. When the pathname provided is relative, it’s interpreted relative to this directory.
pathname: This is the path of the file or directory to remove. If the pathname is absolute (starts with a /), the dirfd parameter is ignored.
flags: This parameter allows you to modify the behavior of the call. Typically, it is set to 0 for removing files. If you want to remove a directory, you must include the AT_REMOVEDIR flag, which tells the system to remove the directory instead of a regular file.
Let’s attach a probe to the entry point of the unlinkat syscall. As you’ll see, using more examples makes the process even easier.
#define __TARGET_ARCH_x86
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
#include <bpf/bpf_core_read.h>
struct event {
__u32 pid;
char comm[16];
char filename[256];
};
struct {
__uint(type, BPF_MAP_TYPE_RINGBUF);
__uint(max_entries, 4096);
} events SEC(".maps");
char _license[] SEC("license") = "GPL";
SEC("tracepoint/syscalls/sys_enter_unlinkat")
int trace_unlinkat(struct trace_event_raw_sys_enter* ctx) {
struct event *evt;
evt = bpf_ringbuf_reserve(&events, sizeof(struct event), 0);
if (!evt)
return 0;
evt->pid = bpf_get_current_pid_tgid() >> 32;
bpf_get_current_comm(&evt->comm, sizeof(evt->comm));
bpf_probe_read_user_str(&evt->filename, sizeof(evt->filename), (const char *)ctx->args[1]);
bpf_ringbuf_submit(evt, 0);
return 0;
}
We captured the pathname by accessing the second argument (pathname is the second argument in unlinkat syscall) in the context’s args array, as shown in:
bpf_probe_read_user_str(&evt->filename, sizeof(evt->filename), (const char *)ctx->args[1]);
By creating and removing files and directories, you should see similar output:
Successfully started! Listening for events...
Process ID: 1899, Command: rm, Filename: test1
Process ID: 1914, Command: rm, Filename: test2
Process ID: 1918, Command: rm, Filename: test3
As you saw, there tremendous amount of possibilities of using such probes, such as using tracepoint:syscalls:sys_enter_connect which allows you to monitor when a process initiates a network connection using the connect() system call, and this is just the tip of the iceberg.
4 - Raw Tracepoints
Raw tracepoints provide a lower-level interface to the same static instrumentation points used by regular tracepoints, but without the overhead of argument type casting and stable ABI guarantees. Introduced in Linux 4.17 by Alexei Starovoitov. Whereas normal tracepoints provide a stable set of arguments, often cast into well-defined data structures, raw tracepoints give direct access to the arguments in the form used by the kernel’s tracepoint handler. This means there’s no guarantee about the argument layout staying consistent across kernel versions—if the kernel’s internal definition of the tracepoint changes, your raw tracepoint program must adapt. Raw tracepoints attach to the same kernel tracepoints as normal tracepoint-based BPF programs. You specify a raw tracepoint by name, just as you would a regular tracepoint, but you load the BPF program with a type that indicates you want raw access, such as BPF_PROG_TYPE_TRACING with a section prefix like raw_tp/ or tp_btf/.
How Raw Tracepoints Work Under the Hood
Raw tracepoints use the same static jump patching mechanism as regular tracepoints, they differ in that they pass unformatted, low-level event data directly to the attached program.

The list of all raw tracepoints are available at /sys/kernel/debug/tracing/available_events file
Raw tracepoints are not defined for each individual syscall but are provided as generic entry and exit points (such as sys_enter and sys_exit) for all system calls. Therefore, if you want to target a specific syscall, you must filter events by checking the syscall ID.
Raw tracepoint uses bpf_raw_tracepoint_args data structure as context which is defined in include/uapi/linux/bpf.has the following:
struct bpf_raw_tracepoint_args {
__u64 args[0];
};
To understand what the arguments point to in the case of sys_enter, you should examine include/trace/events/syscalls.h.
TRACE_EVENT_SYSCALL(sys_enter,
TP_PROTO(struct pt_regs *regs, long id),
TP_ARGS(regs, id),
TP_STRUCT__entry(
__field( long, id )
__array( unsigned long, args, 6 )
),
TP_fast_assign(
__entry->id = id;
syscall_get_arguments(current, regs, __entry->args);
),
TP_printk("NR %ld (%lx, %lx, %lx, %lx, %lx, %lx)",
__entry->id,
__entry->args[0], __entry->args[1], __entry->args[2],
__entry->args[3], __entry->args[4], __entry->args[5]),
syscall_regfunc, syscall_unregfunc
);
It has args as args[0] -> points to pt_regs structure and args[1] is the syscall number.
To access the target syscalls’ parameters, you can either cast ctx->args[0] to a pointer to a struct pt_regs and use it directly, or copy its contents into a local variable of type struct pt_regs (e.g., struct pt_regs regs;). Then, you can extract the syscall parameters using the PT_REGS_PARM macros (such as PT_REGS_PARM1, PT_REGS_PARM2, etc.).
#define __TARGET_ARCH_x86
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
#include <bpf/bpf_core_read.h>
struct event {
__u32 pid;
char comm[16];
char filename[256];
};
struct {
__uint(type, BPF_MAP_TYPE_RINGBUF);
__uint(max_entries, 4096);
} events SEC(".maps");
char LICENSE[] SEC("license") = "GPL";
SEC("raw_tracepoint/sys_enter")
int trace_unlinkat_raw(struct bpf_raw_tracepoint_args *ctx)
{
struct pt_regs regs;
if (bpf_probe_read(®s, sizeof(regs), (void *)ctx->args[0]) != 0)
return 0;
// The syscall number is stored in ctx->args[1]
long syscall_id = ctx->args[1];
if (syscall_id != 263)
return 0;
const char *pathname = (const char *)PT_REGS_PARM2(®s);
struct event *evt = bpf_ringbuf_reserve(&events, sizeof(struct event), 0);
if (!evt)
return 0;
evt->pid = bpf_get_current_pid_tgid() >> 32;
bpf_get_current_comm(evt->comm, sizeof(evt->comm));
int ret = bpf_probe_read_user_str(evt->filename, sizeof(evt->filename), pathname);
if (ret < 0)
evt->filename[0] = '\0';
bpf_ringbuf_submit(evt, 0);
return 0;
}
User-space code
#include <stdio.h>
#include <signal.h>
#include <stdlib.h>
#include <unistd.h>
#include <bpf/libbpf.h>
#include "rtp_unlinkat.skel.h"
static volatile bool exiting = false;
static void sig_handler(int signo)
{
exiting = true;
}
struct event {
__u32 pid;
char comm[16];
char filename[256];
};
static int handle_event(void *ctx, void *data, size_t data_sz)
{
const struct event *e = data;
printf("PID: %u, COMM: %s, FILENAME: %s\n", e->pid, e->comm, e->filename);
return 0;
}
int main(int argc, char **argv)
{
struct rtp_unlinkat *skel;
struct ring_buffer *rb = NULL;
int err;
libbpf_set_strict_mode(LIBBPF_STRICT_ALL);
skel = rtp_unlinkat__open();
if (!skel) {
fprintf(stderr, "Failed to open BPF skeleton\n");
return 1;
}
err = rtp_unlinkat__load(skel);
if (err) {
fprintf(stderr, "Failed to load BPF skeleton: %d\n", err);
goto cleanup;
}
err = rtp_unlinkat__attach(skel);
if (err) {
fprintf(stderr, "Failed to attach BPF skeleton: %d\n", err);
goto cleanup;
}
rb = ring_buffer__new(bpf_map__fd(skel->maps.events), handle_event, NULL, NULL);
if (!rb) {
fprintf(stderr, "Failed to create ring buffer\n");
err = 1;
goto cleanup;
}
signal(SIGINT, sig_handler);
printf("Waiting for events... Press Ctrl+C to exit.\n");
while (!exiting) {
err = ring_buffer__poll(rb, 100);
if (err < 0) {
fprintf(stderr, "Error polling ring buffer: %d\n", err);
break;
}
}
cleanup:
ring_buffer__free(rb);
rtp_unlinkat__destroy(skel);
return err < 0 ? -err : 0;
}
The output:
PID: 3440, COMM: rm, FILENAME: test1
PID: 3442, COMM: rm, FILENAME: test2
Let’s explore another example other than sys_enter. The following is raw tracepoint task_rename which is triggered when a process change its command name. Detecting such activity is crucial in security field such as malware try to hide its true identity or mimic a trusted process such as using prctl(PR_SET_NAME) to change the name of comm.
By examining task_rename tracing event source code located in include/trace/events/task.h,we can see how the tracing mechanism is implemented:
TRACE_EVENT(task_rename,
TP_PROTO(struct task_struct *task, const char *comm),
TP_ARGS(task, comm),
TP_STRUCT__entry(
__field( pid_t, pid)
__array( char, oldcomm, TASK_COMM_LEN)
__array( char, newcomm, TASK_COMM_LEN)
__field( short, oom_score_adj)
),
TP_fast_assign(
__entry->pid = task->pid;
memcpy(entry->oldcomm, task->comm, TASK_COMM_LEN);
strscpy(entry->newcomm, comm, TASK_COMM_LEN);
__entry->oom_score_adj = task->signal->oom_score_adj;
),
TP_printk("pid=%d oldcomm=%s newcomm=%s oom_score_adj=%hd",
__entry->pid, __entry->oldcomm,
__entry->newcomm, __entry->oom_score_adj)
);
From TP_PTORO, we can see that the first argument ctx->args[0] is pointing to struct task_struct *task and the second ctx->args[1] argument is pointing to const char *comm:
TP_PROTO(struct task_struct *task, const char *comm)
struct task_struct data structure is defined in include/linux/sched.h. Let’s see the following code:
#define __TARGET_ARCH_x86
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
#include <bpf/bpf_core_read.h>
#ifndef TASK_COMM_LEN
#define TASK_COMM_LEN 16
#endif
struct event {
u32 pid;
u32 parent_pid;
char new_comm[TASK_COMM_LEN];
char old_comm[TASK_COMM_LEN];
};
struct {
__uint(type, BPF_MAP_TYPE_RINGBUF);
__uint(max_entries, 1 << 12);
} events SEC(".maps");
char LICENSE[] SEC("license") = "GPL";
SEC("raw_tracepoint/task_rename")
int raw_tracepoint_task_rename(struct bpf_raw_tracepoint_args *ctx)
{
struct task_struct *task = (struct task_struct *)ctx->args[0];
const char *new_comm_ptr = (const char *)ctx->args[1];
struct event *e = bpf_ringbuf_reserve(&events, sizeof(*e), 0);
if (!e)
return 0;
e->pid = BPF_CORE_READ(task, pid);
struct task_struct *parent = BPF_CORE_READ(task, real_parent);
e->parent_pid = BPF_CORE_READ(parent, pid);
bpf_probe_read_kernel_str(e->old_comm, sizeof(e->old_comm), task->comm);
bpf_probe_read_kernel_str(e->new_comm, sizeof(e->new_comm), new_comm_ptr);
bpf_ringbuf_submit(e, 0);
return 0;
}
The first argument ctx->args[0] is pointing to struct task_struct *task and the second ctx->args[1] argument is pointing to const char *comm:
struct task_struct *task = (struct task_struct *)ctx->args[0];
const char *new_comm_ptr = (const char *)ctx->args[1];
User-space code:
#include <stdio.h>
#include <stdlib.h>
#include <signal.h>
#include <unistd.h>
#include <errno.h>
#include <bpf/libbpf.h>
#include "task_rename_ringbuf.skel.h"
struct event {
__u32 pid;
__u32 parent_pid;
char new_comm[16];
char old_comm[16];
};
static int handle_event(void *ctx, void *data, size_t data_sz)
{
struct event *e = data;
printf("pid=%u, parent_pid=%u, new_comm=%s, old_comm=%s\n",
e->pid, e->parent_pid, e->new_comm, e->old_comm);
return 0;
}
int main(int argc, char **argv)
{
struct task_rename_ringbuf_bpf *skel;
struct ring_buffer *rb = NULL;
int err;
skel = task_rename_ringbuf_bpf__open();
if (!skel) {
fprintf(stderr, "ERROR: failed to open BPF skeleton\n");
return 1;
}
err = task_rename_ringbuf_bpf__load(skel);
if (err) {
fprintf(stderr, "ERROR: failed to load BPF skeleton: %d\n", err);
goto cleanup;
}
err = task_rename_ringbuf_bpf__attach(skel);
if (err) {
fprintf(stderr, "ERROR: failed to attach BPF skeleton: %d\n", err);
goto cleanup;
}
rb = ring_buffer__new(bpf_map__fd(skel->maps.events), handle_event, NULL, NULL);
if (!rb) {
err = -errno;
fprintf(stderr, "ERROR: failed to create ring buffer: %d\n", err);
goto cleanup;
}
printf("Waiting for task_rename events... Press Ctrl+C to exit.\n");
while (1) {
err = ring_buffer__poll(rb, 100);
if (err < 0 && err != -EINTR) {
fprintf(stderr, "ERROR: polling ring buffer failed: %d\n", err);
break;
}
}
cleanup:
ring_buffer__free(rb);
task_rename_ringbuf_bpf__destroy(skel);
return -err;
}
Now let’s create a simple code to use prctl(PR_SET_NAME) to change comm name:
#include <stdio.h>
#include <unistd.h>
#include <sys/prctl.h>
#include <string.h>
#include <errno.h>
int main(void) {
char current_name[16] = {0};
if (prctl(PR_GET_NAME, (unsigned long)current_name, 0, 0, 0) != 0) {
perror("prctl(PR_GET_NAME)");
return 1;
}
printf("Current process name: %s\n", current_name);
const char *fake_name = "systemd";
if (prctl(PR_SET_NAME, (unsigned long)fake_name, 0, 0, 0) != 0) {
perror("prctl(PR_SET_NAME)");
return 1;
}
memset(current_name, 0, sizeof(current_name));
if (prctl(PR_GET_NAME, (unsigned long)current_name, 0, 0, 0) != 0) {
perror("prctl(PR_GET_NAME)");
return 1;
}
printf("Process name changed to: %s\n", current_name);
sleep(120);
return 0;
}
Compile it using gcc fake.c -o fake then run it ./fake
Waiting for task_rename events... Press Ctrl+C to exit.
pid=7839, parent_pid=7478, new_comm=fake, old_comm=bash
pid=7839, parent_pid=7478, new_comm=systemd, old_comm=fake
Then process changed it’s comm from fake to systemd. We can confirm by
cat /proc/7839/comm
systemd
Or using top command, top --pid 7839
top - 04:57:06 up 4:42, 6 users, load average: 0.02, 0.01, 0.00
Tasks: 1 total, 0 running, 1 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.1 us, 0.1 sy, 0.0 ni, 99.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 3921.3 total, 1481.0 free, 1199.2 used, 1534.0 buff/cache
MiB Swap: 3169.0 total, 3169.0 free, 0.0 used. 2722.1 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
7839 ebpf 20 0 2560 1616 1616 S 0.0 0.0 0:00.00 systemd
5 - Fentry and Fexit
Fentry
An fentry eBPF program is attached precisely at the entry point of a kernel function. Introduced in Linux kernel 5.5 , fentry uses a BPF trampoline to patch function entry points to invoke eBPF code. This results in minimal overhead compared to traditional kprobe.
- When a function is compiled with tracing support CONFIG_FUNCTION_TRACER, the compiler inserts a call to
__fentry__at the beginning of the function which contains severalNOPinstructions0x90. - When an fentry eBPF program is attached, the kernel patches the NOPs dynamically—replacing it with a jump to a BPF trampoline.
- The trampoline then efficiently invokes fentry handler (without the overhead of breakpoints or interrupts) and, after executing, returns control to the original function so that normal execution continues.
Fentry-based and fexit-based eBPF programs are classified under the program type BPF_PROG_TYPE_TRACING.
By looking at the entry is a kernel function such as do_set_acl. First we need to download debug symbols for the kernel, on debian just sudo apt-get install linux-image-$(uname -r)-dbg and the debug symbols will be at /usr/lib/debug/boot/vmlinux-$(uname -r).
Getting the entry point of do_set_acl using objdump -d vmlinux-$(uname -r) | grep -A 10 "<do_set_acl>:"
ffffffff814d7d20 <do_set_acl>:
ffffffff814d7d20: f3 0f 1e fa endbr64
ffffffff814d7d24: e8 37 56 bb ff call ffffffff8108d360 <__fentry__>
ffffffff814d7d29: 41 55 push %r13
ffffffff814d7d2b: 49 89 d5 mov %rdx,%r13
ffffffff814d7d2e: 41 54 push %r12
ffffffff814d7d30: 49 89 f4 mov %rsi,%r12
ffffffff814d7d33: 55 push %rbp
ffffffff814d7d34: 48 89 fd mov %rdi,%rbp
ffffffff814d7d37: 53 push %rbx
ffffffff814d7d38: 4d 85 c0 test %r8,%r8
We can look at __fentry__ using objdump -d vmlinux-$(uname -r) | grep -A 15 "<__fentry__>:"
ffffffff8108d360 <__fentry__>:
ffffffff8108d360: f3 0f 1e fa endbr64
ffffffff8108d364: 90 nop
ffffffff8108d365: 90 nop
ffffffff8108d366: 90 nop
ffffffff8108d367: 90 nop
ffffffff8108d368: 90 nop
ffffffff8108d369: 90 nop
ffffffff8108d36a: 90 nop
ffffffff8108d36b: 90 nop
ffffffff8108d36c: 90 nop
ffffffff8108d36d: e9 ee de c6 00 jmp ffffffff81cfb260 <__x86_return_thunk>
ffffffff8108d372: 66 66 2e 0f 1f 84 00 data16 cs nopw 0x0(%rax,%rax,1)
ffffffff8108d379: 00 00 00 00
ffffffff8108d37d: 0f 1f 00 nopl (%rax)
Before inserting an fentry probe:

After inserting an fentry probe (with BPF trampoline):
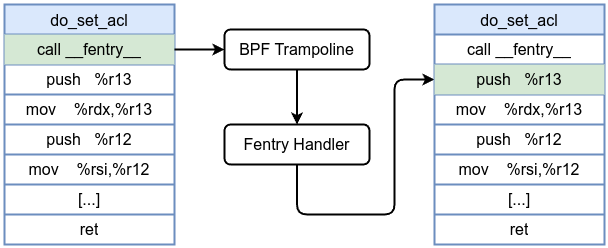
Let’s see the following example, which attaches a probe to the entry of do_set_acl kernel function. do_set_acl is a kernel function that implements the setting of Access Control Lists (ACLs) on files and directories, enabling granular permission control beyond standard Unix permissions.
#define __TARGET_ARCH_x86
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
#include <bpf/bpf_core_read.h>
char LICENSE[] SEC("license") = "GPL";
SEC("fentry/do_set_acl")
int BPF_PROG(handle_do_set_acl,
struct mnt_idmap *idmap,
struct dentry *dentry,
const char *acl_name,
const void *kvalue,
size_t size)
{
char acl[64] = {};
char dname[64] = {};
if (acl_name) {
if (bpf_probe_read_kernel_str(acl, sizeof(acl), acl_name) < 0)
return 0;
}
const char *name_ptr = (const char *)BPF_CORE_READ(dentry, d_name.name);
if (name_ptr) {
if (bpf_probe_read_kernel_str(dname, sizeof(dname), name_ptr) < 0)
return 0;
}
bpf_printk("do_set_acl: dentry=%s, acl_name=%s\n",
dname, acl);
return 0;
}
do_set_acl is defined in fs/posix_acl.c as the following:
int do_set_acl(struct mnt_idmap *idmap, struct dentry *dentry,
const char *acl_name, const void *kvalue, size_t size)
We can also obtain the parameters using sudo bpftrace -lv 'fentry:do_set_acl' (bpftrace will be explained in details later):
fentry:vmlinux:do_set_acl
struct mnt_idmap * idmap
struct dentry * dentry
const char * acl_name
const void * kvalue
size_t size
int retval
user-space code:
#include <stdio.h>
#include <unistd.h>
#include <sys/resource.h>
#include <bpf/libbpf.h>
#include "fentry.skel.h"
static int libbpf_print_fn(enum libbpf_print_level level, const char *format, va_list args)
{
return vfprintf(stderr, format, args);
}
int main(int argc, char **argv)
{
struct fentry *skel;
int err;
libbpf_set_print(libbpf_print_fn);
skel = fentry__open();
if (!skel) {
fprintf(stderr, "Failed to open BPF skeleton\n");
return 1;
}
err = fentry__load(skel);
if (err) {
fprintf(stderr, "Failed to load and verify BPF skeleton\n");
goto cleanup;
}
err = fentry__attach(skel);
if (err) {
fprintf(stderr, "Failed to attach BPF skeleton\n");
goto cleanup;
}
printf("Successfully started! Please run `sudo cat /sys/kernel/debug/tracing/trace_pipe` "
"to see output of the BPF programs.\n");
for (;;) {
fprintf(stderr, ".");
sleep(1);
}
cleanup:
fentry__destroy(skel);
return -err;
}
Executing setctl to change ACL such as setfacl -m u:test:rwx /tmp/file1 or setfacl -m u:test:rwx /etc/passwd
<...>-3776 [...] do_set_acl: dentry=file1, acl_name=system.posix_acl_access
setfacl-3777 [...] do_set_acl: dentry=passwd, acl_name=system.posix_acl_access
Fexit
An fexit eBPF program is attached at the point when a kernel function returns (exits). Introduced alongside fentry, fexit programs also leverage the BPF trampoline. When you attach an fexit program, the kernel finds and patches the return instruction in the function to jump to BPF trampoline. That trampoline then calls your fexit handler before finally returning to the caller. Unlike traditional kretprobe, fexit programs have direct access to both the input parameters of the traced kernel function and its return value. Thus, you don’t need to use additional maps or state tracking to record inputs before function execution.
Before inserting an fexit probe:

After inserting an fexit probe (with BPF trampoline):
Let’s explore the following example which is attach a probe to return of do_set_acl kernel function.
#define __TARGET_ARCH_x86
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
#include <bpf/bpf_core_read.h>
char LICENSE[] SEC("license") = "GPL";
SEC("fexit/do_set_acl")
int BPF_PROG(handle_do_set_acl,
struct mnt_idmap *idmap,
struct dentry *dentry,
const char *acl_name,
const void *kvalue,
size_t size,
int retval)
{
char acl[64] = {};
char dname[64] = {};
if (acl_name) {
if (bpf_probe_read_kernel_str(acl, sizeof(acl), acl_name) < 0)
return 0;
}
const char *name_ptr = (const char *)BPF_CORE_READ(dentry, d_name.name);
if (name_ptr) {
if (bpf_probe_read_kernel_str(dname, sizeof(dname), name_ptr) < 0)
return 0;
}
bpf_printk("do_set_acl: dentry=%s, acl_name=%s, retval=%d\n",
dname, acl, retval);
return 0;
}
user-space code:
#include <stdio.h>
#include <unistd.h>
#include <sys/resource.h>
#include <bpf/libbpf.h>
#include "fexit.skel.h"
static int libbpf_print_fn(enum libbpf_print_level level, const char *format, va_list args)
{
return vfprintf(stderr, format, args);
}
int main(int argc, char **argv)
{
struct fexit *skel;
int err;
libbpf_set_print(libbpf_print_fn);
skel = fexit__open();
if (!skel) {
fprintf(stderr, "Failed to open BPF skeleton\n");
return 1;
}
err = fexit__load(skel);
if (err) {
fprintf(stderr, "Failed to load and verify BPF skeleton\n");
goto cleanup;
}
err = fexit__attach(skel);
if (err) {
fprintf(stderr, "Failed to attach BPF skeleton\n");
goto cleanup;
}
printf("Successfully started! Please run `sudo cat /sys/kernel/debug/tracing/trace_pipe` "
"to see output of the BPF programs.\n");
for (;;) {
fprintf(stderr, ".");
sleep(1);
}
cleanup:
fexit__destroy(skel);
return -err;
}
setfacl-3861 [...] do_set_acl: dentry=file1, acl_name=system.posix_acl_access, retval=0
<...>-3862 [...] do_set_acl: dentry=passwd, acl_name=system.posix_acl_access, retval=-1
Fexit programs have direct access to both the input parameters of the traced kernel function and its return value.