Fentry and Fexit
Fentry
An fentry eBPF program is attached precisely at the entry point of a kernel function. Introduced in Linux kernel 5.5 , fentry uses a BPF trampoline to patch function entry points to invoke eBPF code. This results in minimal overhead compared to traditional kprobe.
- When a function is compiled with tracing support CONFIG_FUNCTION_TRACER, the compiler inserts a call to
__fentry__at the beginning of the function which contains severalNOPinstructions0x90. - When an fentry eBPF program is attached, the kernel patches the NOPs dynamically—replacing it with a jump to a BPF trampoline.
- The trampoline then efficiently invokes fentry handler (without the overhead of breakpoints or interrupts) and, after executing, returns control to the original function so that normal execution continues.
Fentry-based and fexit-based eBPF programs are classified under the program type BPF_PROG_TYPE_TRACING.
By looking at the entry is a kernel function such as do_set_acl. First we need to download debug symbols for the kernel, on debian just sudo apt-get install linux-image-$(uname -r)-dbg and the debug symbols will be at /usr/lib/debug/boot/vmlinux-$(uname -r).
Getting the entry point of do_set_acl using objdump -d vmlinux-$(uname -r) | grep -A 10 "<do_set_acl>:"
ffffffff814d7d20 <do_set_acl>:
ffffffff814d7d20: f3 0f 1e fa endbr64
ffffffff814d7d24: e8 37 56 bb ff call ffffffff8108d360 <__fentry__>
ffffffff814d7d29: 41 55 push %r13
ffffffff814d7d2b: 49 89 d5 mov %rdx,%r13
ffffffff814d7d2e: 41 54 push %r12
ffffffff814d7d30: 49 89 f4 mov %rsi,%r12
ffffffff814d7d33: 55 push %rbp
ffffffff814d7d34: 48 89 fd mov %rdi,%rbp
ffffffff814d7d37: 53 push %rbx
ffffffff814d7d38: 4d 85 c0 test %r8,%r8
We can look at __fentry__ using objdump -d vmlinux-$(uname -r) | grep -A 15 "<__fentry__>:"
ffffffff8108d360 <__fentry__>:
ffffffff8108d360: f3 0f 1e fa endbr64
ffffffff8108d364: 90 nop
ffffffff8108d365: 90 nop
ffffffff8108d366: 90 nop
ffffffff8108d367: 90 nop
ffffffff8108d368: 90 nop
ffffffff8108d369: 90 nop
ffffffff8108d36a: 90 nop
ffffffff8108d36b: 90 nop
ffffffff8108d36c: 90 nop
ffffffff8108d36d: e9 ee de c6 00 jmp ffffffff81cfb260 <__x86_return_thunk>
ffffffff8108d372: 66 66 2e 0f 1f 84 00 data16 cs nopw 0x0(%rax,%rax,1)
ffffffff8108d379: 00 00 00 00
ffffffff8108d37d: 0f 1f 00 nopl (%rax)
Before inserting an fentry probe:

After inserting an fentry probe (with BPF trampoline):
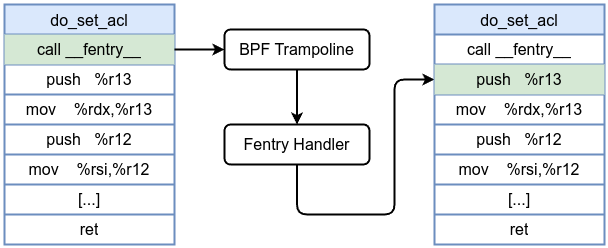
Let’s see the following example, which attaches a probe to the entry of do_set_acl kernel function. do_set_acl is a kernel function that implements the setting of Access Control Lists (ACLs) on files and directories, enabling granular permission control beyond standard Unix permissions.
#define __TARGET_ARCH_x86
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
#include <bpf/bpf_core_read.h>
char LICENSE[] SEC("license") = "GPL";
SEC("fentry/do_set_acl")
int BPF_PROG(handle_do_set_acl,
struct mnt_idmap *idmap,
struct dentry *dentry,
const char *acl_name,
const void *kvalue,
size_t size)
{
char acl[64] = {};
char dname[64] = {};
if (acl_name) {
if (bpf_probe_read_kernel_str(acl, sizeof(acl), acl_name) < 0)
return 0;
}
const char *name_ptr = (const char *)BPF_CORE_READ(dentry, d_name.name);
if (name_ptr) {
if (bpf_probe_read_kernel_str(dname, sizeof(dname), name_ptr) < 0)
return 0;
}
bpf_printk("do_set_acl: dentry=%s, acl_name=%s\n",
dname, acl);
return 0;
}
do_set_acl is defined in fs/posix_acl.c as the following:
int do_set_acl(struct mnt_idmap *idmap, struct dentry *dentry,
const char *acl_name, const void *kvalue, size_t size)
We can also obtain the parameters using sudo bpftrace -lv 'fentry:do_set_acl' (bpftrace will be explained in details later):
fentry:vmlinux:do_set_acl
struct mnt_idmap * idmap
struct dentry * dentry
const char * acl_name
const void * kvalue
size_t size
int retval
user-space code:
#include <stdio.h>
#include <unistd.h>
#include <sys/resource.h>
#include <bpf/libbpf.h>
#include "fentry.skel.h"
static int libbpf_print_fn(enum libbpf_print_level level, const char *format, va_list args)
{
return vfprintf(stderr, format, args);
}
int main(int argc, char **argv)
{
struct fentry *skel;
int err;
libbpf_set_print(libbpf_print_fn);
skel = fentry__open();
if (!skel) {
fprintf(stderr, "Failed to open BPF skeleton\n");
return 1;
}
err = fentry__load(skel);
if (err) {
fprintf(stderr, "Failed to load and verify BPF skeleton\n");
goto cleanup;
}
err = fentry__attach(skel);
if (err) {
fprintf(stderr, "Failed to attach BPF skeleton\n");
goto cleanup;
}
printf("Successfully started! Please run `sudo cat /sys/kernel/debug/tracing/trace_pipe` "
"to see output of the BPF programs.\n");
for (;;) {
fprintf(stderr, ".");
sleep(1);
}
cleanup:
fentry__destroy(skel);
return -err;
}
Executing setctl to change ACL such as setfacl -m u:test:rwx /tmp/file1 or setfacl -m u:test:rwx /etc/passwd
<...>-3776 [...] do_set_acl: dentry=file1, acl_name=system.posix_acl_access
setfacl-3777 [...] do_set_acl: dentry=passwd, acl_name=system.posix_acl_access
Fexit
An fexit eBPF program is attached at the point when a kernel function returns (exits). Introduced alongside fentry, fexit programs also leverage the BPF trampoline. When you attach an fexit program, the kernel finds and patches the return instruction in the function to jump to BPF trampoline. That trampoline then calls your fexit handler before finally returning to the caller. Unlike traditional kretprobe, fexit programs have direct access to both the input parameters of the traced kernel function and its return value. Thus, you don’t need to use additional maps or state tracking to record inputs before function execution.
Before inserting an fexit probe:

After inserting an fexit probe (with BPF trampoline):
Let’s explore the following example which is attach a probe to return of do_set_acl kernel function.
#define __TARGET_ARCH_x86
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
#include <bpf/bpf_core_read.h>
char LICENSE[] SEC("license") = "GPL";
SEC("fexit/do_set_acl")
int BPF_PROG(handle_do_set_acl,
struct mnt_idmap *idmap,
struct dentry *dentry,
const char *acl_name,
const void *kvalue,
size_t size,
int retval)
{
char acl[64] = {};
char dname[64] = {};
if (acl_name) {
if (bpf_probe_read_kernel_str(acl, sizeof(acl), acl_name) < 0)
return 0;
}
const char *name_ptr = (const char *)BPF_CORE_READ(dentry, d_name.name);
if (name_ptr) {
if (bpf_probe_read_kernel_str(dname, sizeof(dname), name_ptr) < 0)
return 0;
}
bpf_printk("do_set_acl: dentry=%s, acl_name=%s, retval=%d\n",
dname, acl, retval);
return 0;
}
user-space code:
#include <stdio.h>
#include <unistd.h>
#include <sys/resource.h>
#include <bpf/libbpf.h>
#include "fexit.skel.h"
static int libbpf_print_fn(enum libbpf_print_level level, const char *format, va_list args)
{
return vfprintf(stderr, format, args);
}
int main(int argc, char **argv)
{
struct fexit *skel;
int err;
libbpf_set_print(libbpf_print_fn);
skel = fexit__open();
if (!skel) {
fprintf(stderr, "Failed to open BPF skeleton\n");
return 1;
}
err = fexit__load(skel);
if (err) {
fprintf(stderr, "Failed to load and verify BPF skeleton\n");
goto cleanup;
}
err = fexit__attach(skel);
if (err) {
fprintf(stderr, "Failed to attach BPF skeleton\n");
goto cleanup;
}
printf("Successfully started! Please run `sudo cat /sys/kernel/debug/tracing/trace_pipe` "
"to see output of the BPF programs.\n");
for (;;) {
fprintf(stderr, ".");
sleep(1);
}
cleanup:
fexit__destroy(skel);
return -err;
}
setfacl-3861 [...] do_set_acl: dentry=file1, acl_name=system.posix_acl_access, retval=0
<...>-3862 [...] do_set_acl: dentry=passwd, acl_name=system.posix_acl_access, retval=-1
Fexit programs have direct access to both the input parameters of the traced kernel function and its return value.