Uprobes and Uretprobes
Uprobes and uretprobes enable instrumentation of user-space applications in a manner similar to how kprobes and kretprobes instrument kernel functions. Instead of tracing kernel-level routines, uprobes and uretprobes attach to functions (or instructions) within user-space executables and shared libraries. This allows system-wide dynamic instrumentation of user applications, including libraries that are shared among many processes.
Unlike the kprobe interface—where the kernel knows the symbol addresses of kernel functions—uprobes require the user to specify the file path and offset of the instruction(s) or function(s) to probe. The offset is calculated from the start of the executable or library file. Once attached, any process using that binary (including those that start in the future) is instrumented.
Uprobes
A uprobe is placed at a specific instruction in a user-space binary (e.g., a function’s entry point in an application or library). When that instruction executes, the CPU hits a breakpoint, and control is transferred to the kernel’s uprobes framework, which then calls the attached eBPF handler. This handler can inspect arguments (readable from user-space memory), task metadata, and more. uprobe eBPF programs are classified under the program type BPF_PROG_TYPE_KPROBE.
How Uprobes Work Under the Hood
- The user identifies the target function or instruction’s offset from the binary’s start. A breakpoint instruction (similar to kprobe’s approach) is inserted into the user-space code at runtime.
- When a process executes that instruction, a trap occurs, switching to kernel mode where the uprobes framework runs the attached eBPF program.
- The eBPF handler runs in the kernel but can read arguments and other data from user-space memory using
bpf_probe_read_user()or related helpers. After the handler completes, uprobes single-step the replaced instruction and return execution control to user space.
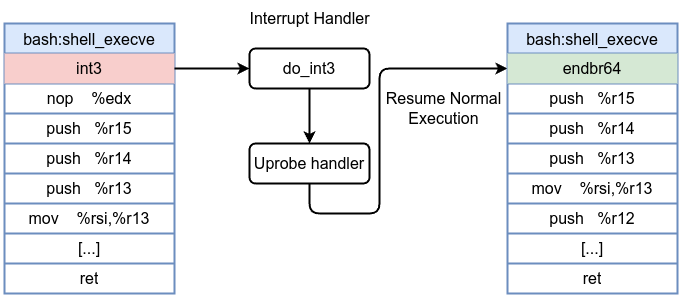
Before uprobe:

After uprobe insertion:
We can get list of all symbols from object or binary files using nm or objdump, for example, to get list of all symbols from /bin/bash all we have to do is nm -D /bin/bash to get dynamic symbols because /bin/bash is stripped of debug symbols, so if you use nm /bin/bash you will get nm: /bin/bash: no symbols.
objdump can extract dynamic symbols using objdump -T /bin/bash. That’s how the output looks in case of nm
[...]
0000000000136828 D shell_builtins
0000000000135cf8 D shell_compatibility_level
000000000013d938 B shell_environment
000000000013da90 B shell_eof_token
0000000000048930 T shell_execve
0000000000131b40 D shell_flags
000000000013f270 B shell_function_defs
000000000013f280 B shell_functions
00000000000839e0 T shell_glob_filename
000000000013d97c B shell_initialized
0000000000032110 T shell_is_restricted
[...]
D or data symbols which represent initialized variable, while B or BSS symbols represent uninitialized global variables and T or text symbols represent code which we are interested in. Let’s attach uprobe to entry point of shell_execve function. shell_execve has a prototype of int shell_execve(char *filename, char **argv, char **envp); which is similar to execve syscall man 2 execve which has this prototype
int execve(const char *pathname, char *const _Nullable argv[],
char *const _Nullable envp[]);
pathname must be either a binary executable, or a script starting with a line of the form:
#!interpreter [optional-arg]
argv is an array of pointers to strings passed to the new program as its command-line ar‐
guments. By convention, the first of these strings (i.e., argv[0]) should contain the
filename associated with the file being executed. The argv array must be terminated by a
null pointer. (Thus, in the new program, argv[argc] will be a null pointer.)
envp is an array of pointers to strings, conventionally of the form key=value, which are
passed as the environment of the new program. The envp array must be terminated by a null
pointer.
Starting with attache uprobe to /bin/bash:shell_execve and extract which command is being executed along with PID and send events to the user-space via ring buffer.
#define __TARGET_ARCH_x86
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
struct event {
pid_t pid;
char command[32];
};
struct {
__uint(type, BPF_MAP_TYPE_RINGBUF);
__uint(max_entries, 4096);
} events SEC(".maps");
char LICENSE[] SEC("license") = "GPL";
SEC("uprobe//bin/bash:shell_execve")
int BPF_UPROBE(uprobe_bash_shell_execve, const char *filename)
{
struct event *evt;
evt = bpf_ringbuf_reserve(&events, sizeof(struct event), 0);
if (!evt)
return 0;
evt->pid = bpf_get_current_pid_tgid() >> 32;
bpf_probe_read_user_str(evt->command, sizeof(evt->command), filename);
bpf_ringbuf_submit(evt, 0);
return 0;
}
We defined a ring buffer type of map with name events
struct {
__uint(type, BPF_MAP_TYPE_RINGBUF);
__uint(max_entries, 4096);
} events SEC(".maps");
Then we used BPF_UPROBE macro which is exactly like BPF_KPROBE which takes the first argument as a name for the function followed by any additional arguments you want to capture.
int BPF_UPROBE(uprobe_bash_shell_execve, const char *filename)
Then reserve space in eBPF ring buffer using bpf_ringbuf_reserve helper function.
evt = bpf_ringbuf_reserve(&events, sizeof(struct event), 0);
Then we copy filename into command member in evt structure.
bpf_probe_read_user_str(evt->command, sizeof(evt->command), filename);
Then we submit evt structure.
bpf_ringbuf_submit(evt, 0);
The user-space code is similar to the one we did before in ksyscall.
#include <stdio.h>
#include <unistd.h>
#include <sys/resource.h>
#include <bpf/libbpf.h>
#include <bpf/bpf.h>
#include "uprobe.skel.h"
static int libbpf_print_fn(enum libbpf_print_level level, const char *format, va_list args)
{
return vfprintf(stderr, format, args);
}
struct event {
pid_t pid;
char command[32];
};
static int handle_event(void *ctx, void *data, size_t data_sz)
{
struct event *evt = (struct event *)data;
printf("Process ID: %d, Command: %s\n", evt->pid, evt->command);
return 0;
}
int main(int argc, char **argv)
{
struct uprobe *skel;
struct ring_buffer *rb = NULL;
int err;
libbpf_set_print(libbpf_print_fn);
skel = uprobe__open();
if (!skel) {
fprintf(stderr, "Failed to open BPF skeleton\n");
return 1;
}
err = uprobe__load(skel);
if (err) {
fprintf(stderr, "Failed to load and verify BPF skeleton\n");
goto cleanup;
}
err = uprobe__attach(skel);
if (err) {
fprintf(stderr, "Failed to attach BPF skeleton\n");
goto cleanup;
}
rb = ring_buffer__new(bpf_map__fd(skel->maps.events), handle_event, NULL, NULL);
if (!rb) {
fprintf(stderr, "Failed to create ring buffer\n");
goto cleanup;
}
printf("Successfully started! Listening for events...\n");
while (1) {
err = ring_buffer__poll(rb, 100);
if (err < 0) {
fprintf(stderr, "Error polling ring buffer\n");
break;
}
}
cleanup:
ring_buffer__free(rb);
uprobe__destroy(skel);
return -err;
}
Let’s compile both codes and run the code
sudo bpftool btf dump file /sys/kernel/btf/vmlinux format c > vmlinux.h
clang -g -O2 -target bpf -c uprobe-shell_execve.bpf.c -o uprobe.o
sudo bpftool gen skeleton uprobe.o > uprobe.skel.h
clang -o loader loader.c -lbpf
sudo ./loader
Open a new terminal and execute bash & then gdb -p PID in my case gdb -p 1923 then disassemble shell_execve and you will get something similar
(gdb) disassemble shell_execve
Dump of assembler code for function shell_execve:
0x00005601e928c930 <+0>: int3
0x00005601e928c931 <+1>: nop %edx
0x00005601e928c934 <+4>: push %r15
0x00005601e928c936 <+6>: push %r14
0x00005601e928c938 <+8>: push %r13
0x00005601e928c93a <+10>: mov %rsi,%r13
0x00005601e928c93d <+13>: push %r12
0x00005601e928c93f <+15>: push %rbp
0x00005601e928c940 <+16>: push %rbx
0x00005601e928c941 <+17>: mov %rdi,%rbx
0x00005601e928c944 <+20>: sub $0xa8,%rsp
0x00005601e928c94b <+27>: mov %fs:0x28,%r14
[...]
Notice int3 at the entry point of shell_execve which is a software breakpoint set by uprobe. You will get also something similar on the loader terminal
libbpf: sec 'uprobe//bin/bash:shell_execve': found 1 CO-RE relocations
libbpf: CO-RE relocating [10] struct pt_regs: found target candidate [136] struct pt_regs in [vmlinux]
libbpf: prog 'uprobe_bash_shell_execve': relo #0: <byte_off> [10] struct pt_regs.di (0:14 @ offset 112)
libbpf: prog 'uprobe_bash_shell_execve': relo #0: matching candidate #0 <byte_off> [136] struct pt_regs.di (0:14 @ offset 112)
libbpf: prog 'uprobe_bash_shell_execve': relo #0: patched insn #0 (LDX/ST/STX) off 112 -> 112
libbpf: map 'events': created successfully, fd=3
libbpf: elf: symbol address match for 'shell_execve' in '/bin/bash': 0x48930
Successfully started! Listening for events...
Process ID: 1923, Command: /usr/bin/bash
Process ID: 1924, Command: /usr/bin/gdb
Running it with strace sudo strace -ebpf ./loader to capture bpf() syscalls shows that the the prog_type is indeed BPF_PROG_TYPE_KPROBE and the prog_name is uprobe_bash_shell_execve and map_type is BPF_MAP_TYPE_RINGBUF.
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_RINGBUF, key_size=0, value_size=0, max_entries=4096, map_flags=0, inner_map_fd=0, map_name="events", map_ifindex=0, btf_fd=4, btf_key_type_id=0, btf_value_type_id=0, btf_vmlinux_value_type_id=0, map_extra=0}, 80) = 5
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_KPROBE, insn_cnt=21, insns=0x55adbd3b0000, license="GPL", log_level=0, log_size=0, log_buf=NULL, kern_version=KERNEL_VERSION(6, 12, 12), prog_flags=0, prog_name="uprobe_bash_shell_execve", prog_ifindex=0, expected_attach_type=BPF_CGROUP_INET_INGRESS, prog_btf_fd=4, func_info_rec_size=8, func_info=0x55adbd3ae7e0, func_info_cnt=1, line_info_rec_size=16, line_info=0x55adbd3ae860, line_info_cnt=10, attach_btf_id=0, attach_prog_fd=0, fd_array=NULL}, 148) = 5
At this point i hope you got that you can uprobe your own code. Compile this code as /tmp/test and compile it gcc -g test.c -o test
#include <stdio.h>
const char* get_message() {
return "got uprobed!!";
}
int main() {
const char* message = get_message();
printf("%s\n", message);
return 0;
}
With eBPF code
#define __TARGET_ARCH_x86
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
char LICENSE[] SEC("license") = "GPL";
SEC("uprobe//tmp/test:get_message")
int BPF_UPROBE(trace_my_function)
{
pid_t pid;
pid = bpf_get_current_pid_tgid() >> 32;
bpf_printk("PID %d \n", pid);
return 0;
}
Then you will get
exam-3142 [003] ...11 17712.082503: bpf_trace_printk: PID 3142
Uretprobes
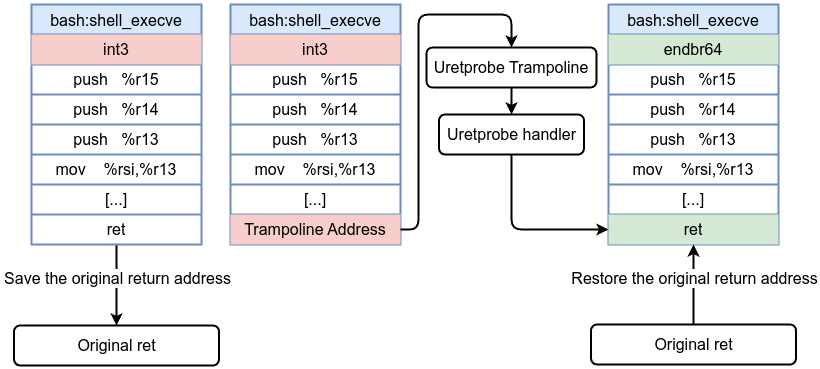
A uretprobe triggers when a user-space function returns. Just like kretprobes, uretprobes replace the function’s return address with a trampoline so that when the function completes, execution hits the trampoline first—invoking the eBPF return handler before returning to the actual caller. uprobe eBPF programs are also classified under the program type BPF_PROG_TYPE_KPROBE.
How Uretprobes Work Under the Hood
- When you register a uretprobe, a corresponding uprobe is placed at the function’s entry to record the return address and replace it with a trampoline.
- At function entry, the uprobe saves the original return address and sets the trampoline address. An optional entry handler can run here, deciding if we should track this particular instance.
- When the function returns, instead of going directly back to the caller, it hits the trampoline. The trampoline has its own probe, triggering the uretprobe handler. The handler can read the function’s return value, gather timing information, or finalize any data collected at entry.
- The original return address is restored, and the application continues execution as if nothing happened.
Before uretprobe:

After uretprobe installation:
The readline function in bash reads the user’s input from the terminal and returns a pointer to the string containing the text of the line read. Its prototype is:
char *readline (const char *prompt);. You can use eBPF to capture or record the user input in bash by hooking into the return of the readline function.
#define __TARGET_ARCH_x86
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
struct event {
pid_t pid;
char command[64];
};
struct {
__uint(type, BPF_MAP_TYPE_RINGBUF);
__uint(max_entries, 2048);
} events SEC(".maps");
char LICENSE[] SEC("license") = "GPL";
SEC("uretprobe//bin/bash:readline")
int BPF_URETPROBE(uretprobe_readline, const void *ret)
{
struct event *evt;
evt = bpf_ringbuf_reserve(&events, sizeof(struct event), 0);
if (!evt)
return 0;
evt->pid = bpf_get_current_pid_tgid() >> 32;
bpf_probe_read_user_str(evt->command, sizeof(evt->command), ret);
bpf_ringbuf_submit(evt, 0);
return 0;
};
Successfully started! Listening for events...
Process ID: 1859, Command: cat /etc/passwd
Process ID: 1859, Command: cat /etc/issue.net
Process ID: 1859, Command: ls -l
Note
Uprobes can add overhead, especially when targeting high-frequency user-space functions (like malloc()). The overhead can compound significantly if millions of events occur per second, potentially causing a noticeable slowdown in the application. Consider carefully which user-space functions to instrument and apply uprobes selectively, possibly in a test environment or only when diagnosing severe issues.Let’s walk through some advanced examples: we will demonstrate how to capture the password entered in PAM and how to observe decrypted traffic without needing CA certificates, all using uprobes.
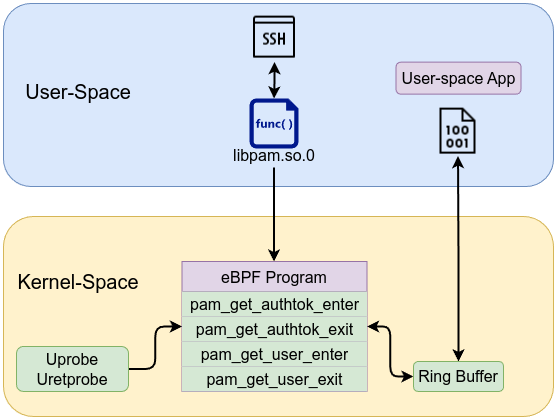
PAM (Pluggable Authentication Modules) is a framework that offers a modular approach to authentication, making it easier to manage and secure the login process. During authentication, the pam_get_user function is responsible for obtaining the username from the session, while pam_get_authtok retrieves the corresponding password or token, ensuring that each step is handled securely and flexibly.
The function prototype for pam_get_authtok is:
int pam_get_authtok(pam_handle_t *pamh, int item,
const char **authtok, const char *prompt);
According to the man page, this function returns the cached authentication token (for example, a password) if one is available, or it prompts the user to enter one if no token is cached. Upon successful return, the **authtok parameter will point to the value of the authentication token. This function is intended for internal use by Linux-PAM and PAM service modules.
The prototype for pam_get_user is:
int pam_get_user(const pam_handle_t *pamh, const char **user, const char *prompt);
The pam_get_user function returns the name of the user specified by the pam_start function, which is responsible for creating the PAM context and initiating the PAM transaction. A pointer to the username is then returned as the contents of *user.
Note
Please note that both**authtok in pam_get_authtok and **user in pam_get_user are pointers to pointers.
To capture the password, we need to attach uprobe to libpam /lib/x86_64-linux-gnu/libpam.so.0:pam_get_authtok at the entry point and exit point, why entry point and exit point, short answer is that in pam_get_authtok the password pointer (**authtok) isn’t fully assigned or valid at the start of the function. Instead, the function fills in that pointer somewhere inside (for example, prompting the user or retrieving from memory), so by the time the function returns, the pointer (and thus the password string) is set. Hence, a uretprobe (return probe) is the only reliable place to grab the final pointer to the password.
The same goes for capturing the user, we need to attach uprobe to libpam /lib/x86_64-linux-gnu/libpam.so.0:pam_get_user at the entry point and exit point.
#define __TARGET_ARCH_x86
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
#include <bpf/bpf_core_read.h>
#define MAX_PW_LEN 128
#define MAX_USER_LEN 64
char LICENSE[] SEC("license") = "GPL";
struct event {
int pid;
char comm[16];
char password[MAX_PW_LEN];
char username[MAX_USER_LEN];
};
struct {
__uint(type, BPF_MAP_TYPE_RINGBUF);
__uint(max_entries, 4096);
} events SEC(".maps");
struct {
__uint(type, BPF_MAP_TYPE_HASH);
__uint(max_entries, 1024);
__type(key, __u32);
__type(value, __u64);
} authtok_ptrs SEC(".maps");
struct {
__uint(type, BPF_MAP_TYPE_HASH);
__uint(max_entries, 1024);
__type(key, __u32);
__type(value, __u64);
} user_ptrs SEC(".maps");
SEC("uprobe//lib/x86_64-linux-gnu/libpam.so.0:pam_get_authtok")
int BPF_UPROBE(pam_get_authtok_enter,
void *pamh,
int item,
const char **authtok,
const char *prompt)
{
pid_t pid = bpf_get_current_pid_tgid() >> 32;
__u64 atok_ptr = (unsigned long)authtok;
bpf_map_update_elem(&authtok_ptrs, &pid, &atok_ptr, BPF_ANY);
return 0;
}
SEC("uretprobe//lib/x86_64-linux-gnu/libpam.so.0:pam_get_authtok")
int BPF_URETPROBE(pam_get_authtok_exit)
{
pid_t pid = bpf_get_current_pid_tgid() >> 32;
int ret = PT_REGS_RC(ctx);
__u64 *stored = bpf_map_lookup_elem(&authtok_ptrs, &pid);
if (!stored)
return 0;
bpf_map_delete_elem(&authtok_ptrs, &pid);
if (ret != 0)
return 0;
__u64 atok_addr = 0;
bpf_probe_read_user(&atok_addr, sizeof(atok_addr), (const void *)(*stored));
if (!atok_addr)
return 0;
struct event *evt = bpf_ringbuf_reserve(&events, sizeof(struct event), 0);
if (!evt)
return 0;
evt->pid = pid;
bpf_get_current_comm(&evt->comm, sizeof(evt->comm));
bpf_probe_read_user(evt->password, sizeof(evt->password), (const void *)atok_addr);
bpf_ringbuf_submit(evt, 0);
return 0;
}
SEC("uprobe//lib/x86_64-linux-gnu/libpam.so.0:pam_get_user")
int BPF_UPROBE(pam_get_user_enter,
void *pamh,
const char **user,
const char *prompt)
{
pid_t pid = bpf_get_current_pid_tgid() >> 32;
__u64 user_ptr = (unsigned long)user;
bpf_map_update_elem(&user_ptrs, &pid, &user_ptr, BPF_ANY);
return 0;
}
SEC("uretprobe//lib/x86_64-linux-gnu/libpam.so.0:pam_get_user")
int BPF_URETPROBE(pam_get_user_exit)
{
pid_t pid = bpf_get_current_pid_tgid() >> 32;
int ret = PT_REGS_RC(ctx);
__u64 *stored = bpf_map_lookup_elem(&user_ptrs, &pid);
if (!stored)
return 0;
bpf_map_delete_elem(&user_ptrs, &pid);
if (ret != 0)
return 0;
__u64 user_addr = 0;
bpf_probe_read_user(&user_addr, sizeof(user_addr), (const void *)(*stored));
if (!user_addr)
return 0;
struct event *evt = bpf_ringbuf_reserve(&events, sizeof(struct event), 0);
if (!evt)
return 0;
evt->pid = pid;
bpf_get_current_comm(&evt->comm, sizeof(evt->comm));
bpf_probe_read_user(evt->username, sizeof(evt->username), (const void *)user_addr);
bpf_ringbuf_submit(evt, 0);
return 0;
}
First, we defined struct event and then created two BPF_MAP_TYPE_HASH maps to process and hold the username and password passed by the functions. Since **authtok and **user are pointers to pointers, we need to call bpf_probe_read_user twice to correctly read the values.
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <errno.h>
#include <signal.h>
#include <stdarg.h>
#include <bpf/libbpf.h>
#include <bpf/bpf.h>
#include "pamcapture.skel.h"
#define MAX_PW_LEN 128
struct event {
int pid;
char comm[16];
char password[MAX_PW_LEN];
char username[64];
};
static int handle_event(void *ctx, void *data, size_t data_sz)
{
struct event *evt = data;
printf("\n---- PAM Password capture ----\n");
if (evt->username[0] == '\0') {
printf("\n---- PAM Password captured ----\n");
printf("PID: %d, COMM: %.*s, Password: %s\n", evt->pid, 16, evt->comm, evt->password);
} else {
printf("\n---- PAM Uusername capture ----\n");
printf("PID: %d, username = %s\n", evt->pid,evt->username);
}
return 0;
}
static int libbpf_print_fn(enum libbpf_print_level level, const char *format, va_list args)
{
return vfprintf(stderr, format, args);
}
int main(int argc, char **argv)
{
struct pamcapture *skel = NULL;
struct ring_buffer *rb = NULL;
int err;
libbpf_set_print(libbpf_print_fn);
skel = pamcapture__open();
if (!skel) {
fprintf(stderr, "Failed to open BPF skeleton\n");
return 1;
}
err = pamcapture__load(skel);
if (err) {
fprintf(stderr, "Failed to load and verify BPF skeleton\n");
goto cleanup;
}
err = pamcapture__attach(skel);
if (err) {
fprintf(stderr, "Failed to attach BPF skeleton\n");
goto cleanup;
}
rb = ring_buffer__new(bpf_map__fd(skel->maps.events), handle_event, NULL, NULL);
if (!rb) {
fprintf(stderr, "Failed to create ring buffer\n");
goto cleanup;
}
printf("PAM password capture attached! Press Ctrl-C to exit.\n");
while (1) {
err = ring_buffer__poll(rb, 100);
if (err < 0) {
fprintf(stderr, "Error polling ring buffer\n");
break;
}
}
cleanup:
ring_buffer__free(rb);
pamcapture__destroy(skel);
return err < 0 ? -err : 0;
}
The output should be similar to the following
PAM password capture attached! Press Ctrl-C to exit.
---- PAM Uusername capture ----
PID: 2663, username = test
---- PAM Password captured ----
PID: 2663, COMM: sshd-session, Password: admin
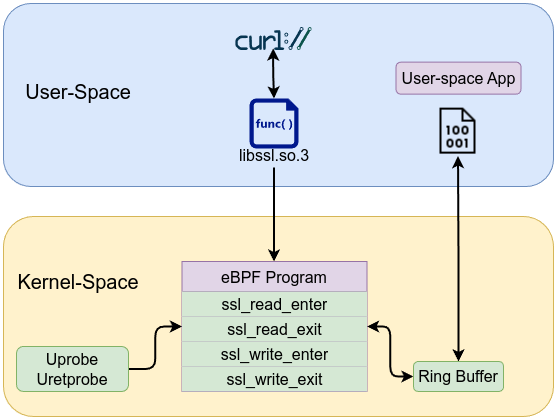
Let’s explore another example to show you the power of uprobe/uretprobe. Libssl is a core component of the OpenSSL library, providing implementations of the Secure Sockets Layer (SSL) and Transport Layer Security (TLS) protocols to enable secure communications over network by encrypting data. You can check the list of all functions by executing command like nm on /lib/x86_64-linux-gnu/libssl.so.3 or whatever libssl version you have. Couple of its core functions are SSL_read and SSL_write. SSL_read reads data from an SSL/TLS connection, decrypting it and storing the result in the buffer pointed to by buf. Here, buf is a pointer to user-space memory where the decrypted data is written. SSL_read has a prototype of:
int SSL_read(SSL *ssl, void *buf, int num);
SSL_write function writes data to an SSL/TLS connection by encrypting the content of the buffer pointed to by buf and transmitting it. In this case, buf is a pointer to the user-space memory containing the plaintext data that will be encrypted. SSL_write has a prototype of:
int SSL_write(SSL *ssl, const void *buf, int num);
Uprobes let you intercept user-space function calls at runtime. By attaching them to libssl’s SSL_read and SSL_write, you capture data after it’s decrypted (or before it’s encrypted) inside the process memory. This means you get the plaintext data directly, without needing to use a CA to decrypt network traffic.
To capture decrypted traffic for both ways (send and receive ), we need to attach uprobe at the entry point and the exit point for each function. You need to attach a probe at the entry point to capture the buffer pointer (the address of buf) as soon as the function is called, because that pointer is passed as an argument. Then, attaching a probe at the exit point lets you read the final data from that buffer after the function has processed it.
The curl command on my ubuntu box is version 8.5.0 which still uses libssl
curl -V
curl 8.5.0 (x86_64-pc-linux-gnu) libcurl/8.5.0 OpenSSL/3.0.13 zlib/1.3 brotli/1.1.0 zstd/1.5.5 libidn2/2.3.7 libpsl/0.21.2 (+libidn2/2.3.7) libssh/0.10.6/openssl/zlib nghttp2/1.59.0 librtmp/2.3 OpenLDAP/2.6.7
[...]
ldd /usr/bin/curl
[...]
libssl.so.3 => /lib/x86_64-linux-gnu/libssl.so.3 (0x00007a1b58443000)
[...]
Let’s see the kernel code:
#define __TARGET_ARCH_x86
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
#include <bpf/bpf_core_read.h>
#define MAX_BUF_SIZE 4096
char LICENSE[] SEC("license") = "GPL";
enum STATE {
STATE_READ = 0,
STATE_WRITE = 1,
};
struct data {
enum STATE STATE;
int len;
char comm[16];
char buf[MAX_BUF_SIZE];
};
struct {
__uint(type, BPF_MAP_TYPE_RINGBUF);
__uint(max_entries, 1 << 24);
} events SEC(".maps");
struct {
__uint(type, BPF_MAP_TYPE_HASH);
__uint(max_entries, 1024);
__type(key, __u32);
__type(value, __u64);
} buffers SEC(".maps");
static __always_inline __u32 get_tgid(void)
{
return (__u32)bpf_get_current_pid_tgid();
}
static int ssl_exit(struct pt_regs *ctx, enum STATE STATE)
{
__u32 tgid = get_tgid();
int ret = PT_REGS_RC(ctx);
if (ret <= 0) {
bpf_map_delete_elem(&buffers, &tgid);
return 0;
}
__u64 *bufp = bpf_map_lookup_elem(&buffers, &tgid);
if (!bufp) {
return 0;
}
if (*bufp == 0) {
bpf_map_delete_elem(&buffers, &tgid);
return 0;
}
struct data *data = bpf_ringbuf_reserve(&events, sizeof(*data), 0);
if (!data)
return 0;
data->STATE = STATE;
data->len = ret;
bpf_get_current_comm(&data->comm, sizeof(data->comm));
int err = bpf_probe_read_user(data->buf, sizeof(data->buf), (void *)(*bufp));
if (err) {
bpf_map_delete_elem(&buffers, &tgid);
bpf_ringbuf_submit(data, 0);
return 0;
}
bpf_map_delete_elem(&buffers, &tgid);
bpf_ringbuf_submit(data, 0);
return 0;
}
SEC("uprobe//lib/x86_64-linux-gnu/libssl.so.3:SSL_read")
int BPF_UPROBE(ssl_read_enter, void *ssl, void *buf, int num)
{
__u32 tgid = get_tgid();
bpf_map_update_elem(&buffers, &tgid, &buf, BPF_ANY);
return 0;
}
SEC("uretprobe//lib/x86_64-linux-gnu/libssl.so.3:SSL_read")
int BPF_URETPROBE(ssl_read_exit)
{
return ssl_exit(ctx, STATE_READ);
}
SEC("uprobe//lib/x86_64-linux-gnu/libssl.so.3:SSL_write")
int BPF_UPROBE(ssl_write_enter, void *ssl, const void *buf, int num)
{
__u32 tgid = get_tgid();
bpf_map_update_elem(&buffers, &tgid, &buf, BPF_ANY);
return 0;
}
SEC("uretprobe//lib/x86_64-linux-gnu/libssl.so.3:SSL_write")
int BPF_URETPROBE(ssl_write_exit)
{
return ssl_exit(ctx, STATE_WRITE);
}
The ssl_exit function retrieves the return value to determine if any data was processed and then uses the process ID (tgid) to look up the previously stored user-space buffer pointer. The function then reserves an event structure from the ring buffer, reads the actual data from user memory using bpf_probe_read_user, and finally submits the event while cleaning up the stored pointer from the BPF hash map.
Note
The__always_inline macros is used to tell the compiler to inline a function.This means that rather than generating a normal function call, the compiler inserts the body of the function directly into the calling code.
The user-space code:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/resource.h>
#include <bpf/libbpf.h>
#include <bpf/bpf.h>
#include "sslsniff.skel.h"
#define MAX_BUF_SIZE 4096
enum STATE {
STATE_READ = 0,
STATE_WRITE = 1,
};
struct data {
enum STATE STATE;
int len;
char comm[16];
char buf[MAX_BUF_SIZE];
};
static int libbpf_print_fn(enum libbpf_print_level level, const char *format, va_list args)
{
return vfprintf(stderr, format, args);
}
static int handle_event(void *ctx, void *data, size_t data_sz)
{
struct data *evt = data;
int data_len = evt->len < MAX_BUF_SIZE ? evt->len : MAX_BUF_SIZE;
const char *dir_str = (evt->STATE == STATE_WRITE) ? "SEND" : "RECV";
printf("\n--- Perf Event ---\n");
printf("Process: %s, Type: %d, Bytes: %d\n", evt->comm, dir_str, evt->len);
printf("Data (first %d bytes):\n", data_len);
fwrite(evt->buf, 1, data_len, stdout);
return 0;
}
int main(int argc, char **argv)
{
struct sslsniff *skel = NULL;
struct ring_buffer *rb = NULL;
int err;
libbpf_set_print(libbpf_print_fn);
skel = sslsniff__open();
if (!skel) {
fprintf(stderr, "Failed to open BPF skeleton\n");
return 1;
}
err = sslsniff__load(skel);
if (err) {
fprintf(stderr, "Failed to load and verify BPF skeleton\n");
goto cleanup;
}
err = sslsniff__attach(skel);
if (err) {
fprintf(stderr, "Failed to attach BPF skeleton\n");
goto cleanup;
}
rb = ring_buffer__new(bpf_map__fd(skel->maps.events), handle_event, NULL, NULL);
if (!rb) {
fprintf(stderr, "Failed to create ring buffer\n");
goto cleanup;
}
printf("libssl sniffer attached. Press Ctrl+C to exit.\n");
while (1) {
err = ring_buffer__poll(rb, 100);
if (err < 0) {
fprintf(stderr, "Error polling ring buffer\n");
break;
}
}
cleanup:
ring_buffer__free(rb);
sslsniff__destroy(skel);
return err < 0 ? -err : 0;
}
Running curl command curl https://www.hamza-megahed.com/robots.txt --http1.1 and we will get a similar traffic to the following:
--- Perf Event ---
Process: curl, Type: SEND, Bytes: 94
Data (first 94 bytes):
GET /robots.txt HTTP/1.1
Host: www.hamza-megahed.com
User-Agent: curl/8.5.0
Accept: */*
--- Perf Event ---
Process: curl, Type: RECV, Bytes: 1172
Data (first 1172 bytes):
HTTP/1.1 200 OK
Date: Sun, 02 Mar 2025 20:57:27 GMT
Content-Type: text/plain
Content-Length: 66
[...]
User-agent: *
Sitemap: https://www.hamza-megahed.com/sitemap.xml
As you can see, the traffic is decrypted!
Now let’s do the same to GnuTLS which has two functions gnutls_record_recv and gnutls_record_send
GnuTLS is a secure communications library that implements TLS/SSL protocols. Two core functions in this library are: gnutls_record_recv with prototype:
ssize_t gnutls_record_recv(gnutls_session_t session, void *data, size_t data_size);
gnutls_record_recv function receives an encrypted record from a GnuTLS session, decrypts it, and writes the resulting plaintext into the user-provided buffer pointed to by data.
Function gnutls_record_send with prototype
ssize_t gnutls_record_send(gnutls_session_t session, const void *data, size_t data_size);
gnutls_record_send function takes plaintext data from the user-provided buffer pointed to by data, encrypts it, and sends it over the network as an encrypted record.
I have another box with curl version 8.12.1
curl 8.12.1 (x86_64-pc-linux-gnu) libcurl/8.12.1 GnuTLS/3.8.9 zlib/1.3.1 brotli/1.1.0 zstd/1.5.6 libidn2/2.3.7 libpsl/0.21.2 libssh2/1.11.1 nghttp2/1.64.0 ngtcp2/1.9.1 nghttp3/1.6.0 librtmp/2.3 OpenLDAP/2.6.9
Release-Date: 2025-02-13, security patched: 8.12.1-2
The location of libgnutls linked to curl command can be obtained by running ldd /usr/bin/curl
libgnutls.so.30 => /lib/x86_64-linux-gnu/libgnutls.so.30 (0x00007f82da200000)
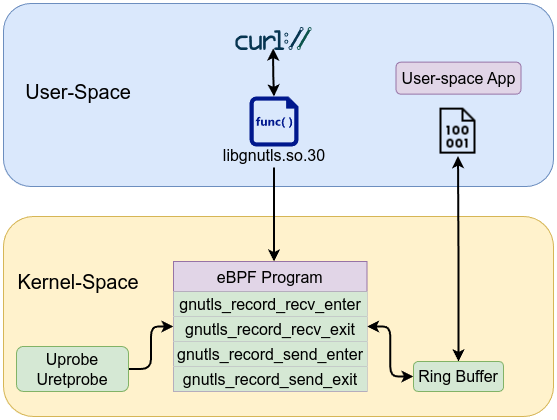
To capture the decrypted or plaintext data processed by these functions, you need to attach uprobes at both the entry and exit points of each function. Attaching a probe at the entry captures the buffer pointer as it is passed to the function, while attaching a probe at the exit allows you to read the final processed data from that buffer once the function has completed its work.
#define __TARGET_ARCH_x86
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
#include <bpf/bpf_core_read.h>
#define MAX_BUF_SIZE 4096
char LICENSE[] SEC("license") = "GPL";
enum STATE {
STATE_READ = 0,
STATE_WRITE = 1,
};
struct data {
enum STATE STATE;
int len;
char comm[16];
char buf[MAX_BUF_SIZE];
};
struct {
__uint(type, BPF_MAP_TYPE_RINGBUF);
__uint(max_entries, 1 << 24);
} events SEC(".maps");
struct {
__uint(type, BPF_MAP_TYPE_HASH);
__uint(max_entries, 1024);
__type(key, __u32);
__type(value, __u64);
} buffers SEC(".maps");
static __always_inline __u32 get_tgid(void)
{
return (__u32)bpf_get_current_pid_tgid();
}
static int record_exit(struct pt_regs *ctx, enum STATE STATE)
{
__u32 tgid = get_tgid();
int ret = PT_REGS_RC(ctx);
if (ret <= 0) {
bpf_map_delete_elem(&buffers, &tgid);
return 0;
}
__u64 *bufp = bpf_map_lookup_elem(&buffers, &tgid);
if (!bufp) {
return 0;
}
if (*bufp == 0) {
bpf_map_delete_elem(&buffers, &tgid);
return 0;
}
struct data *data = bpf_ringbuf_reserve(&events, sizeof(*data), 0);
if (!data)
return 0;
data->STATE = STATE;
data->len = ret;
bpf_get_current_comm(&data->comm, sizeof(data->comm));
int err = bpf_probe_read_user(data->buf, sizeof(data->buf), (void *)(*bufp));
if (err) {
bpf_map_delete_elem(&buffers, &tgid);
bpf_ringbuf_submit(data, 0);
return 0;
}
bpf_map_delete_elem(&buffers, &tgid);
bpf_ringbuf_submit(data, 0);
return 0;
}
SEC("uprobe//lib/x86_64-linux-gnu/libgnutls.so.30:gnutls_record_recv")
int BPF_UPROBE(gnutls_record_recv_enter, void *session, void *data, size_t sizeofdata)
{
__u32 tgid = get_tgid();
bpf_map_update_elem(&buffers, &tgid, &data, BPF_ANY);
return 0;
}
SEC("uretprobe//lib/x86_64-linux-gnu/libgnutls.so.30:gnutls_record_recv")
int BPF_URETPROBE(gnutls_record_recv_exit)
{
return record_exit(ctx, STATE_READ);
}
SEC("uprobe//lib/x86_64-linux-gnu/libgnutls.so.30:gnutls_record_send")
int BPF_UPROBE(gnutls_record_send_enter, void *session, const void *data, size_t sizeofdata)
{
__u32 tgid = get_tgid();
bpf_map_update_elem(&buffers, &tgid, &data, BPF_ANY);
return 0;
}
SEC("uretprobe//lib/x86_64-linux-gnu/libgnutls.so.30:gnutls_record_send")
int BPF_URETPROBE(gnutls_record_send_exit)
{
return record_exit(ctx, STATE_WRITE);
}
The user-space code:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/resource.h>
#include <bpf/libbpf.h>
#include <bpf/bpf.h>
#include "gnutls_sniffer.skel.h"
#define MAX_BUF_SIZE 4096
enum STATE {
STATE_READ = 0,
STATE_WRITE = 1,
};
struct data {
enum STATE STATE;
int len;
char comm[16];
char buf[MAX_BUF_SIZE];
};
static int libbpf_print_fn(enum libbpf_print_level level, const char *format, va_list args)
{
return vfprintf(stderr, format, args);
}
static int handle_event(void *ctx, void *data, size_t data_sz)
{
struct data *evt = data;
int data_len = evt->len < MAX_BUF_SIZE ? evt->len : MAX_BUF_SIZE;
const char *dir_str = (evt->STATE == STATE_WRITE) ? "SEND" : "RECV";
printf("\n--- Perf Event ---\n");
printf("Process: %s, Type: %s, Bytes: %d\n", evt->comm, dir_str, evt->len);
printf("Data (first %d bytes):\n", data_len);
fwrite(evt->buf, 1, data_len, stdout);
return 0;
}
int main(int argc, char **argv)
{
struct gnutls_sniffer *skel = NULL;
struct ring_buffer *rb = NULL;
int err;
skel = gnutls_sniffer__open();
if (!skel) {
fprintf(stderr, "Failed to open BPF skeleton\n");
return 1;
}
err = gnutls_sniffer__load(skel);
if (err) {
fprintf(stderr, "Failed to load/verify BPF skeleton: %d\n", err);
goto cleanup;
}
err = gnutls_sniffer__attach(skel);
if (err) {
fprintf(stderr, "Failed to attach BPF skeleton: %d\n", err);
goto cleanup;
}
rb = ring_buffer__new(bpf_map__fd(skel->maps.events), handle_event, NULL, NULL);
if (!rb) {
err = -errno;
fprintf(stderr, "Failed to create ring buffer: %d\n", err);
goto cleanup;
}
printf("GnuTLS sniffer attached. Press Ctrl+C to exit.\n");
while (1) {
err = ring_buffer__poll(rb, 100);
if (err < 0) {
fprintf(stderr, "Error polling ring buffer\n");
break;
}
}
cleanup:
ring_buffer__free(rb);
gnutls_sniffer__destroy(skel);
return err < 0 ? -err : 0;
}
Same results
GnuTLS sniffer attached. Press Ctrl+C to exit.
--- Perf Event ---
Process: curl, Type: SEND, Bytes: 95
Data (first 95 bytes):
GET /robots.txt HTTP/1.1
Host: www.hamza-megahed.com
User-Agent: curl/8.12.1
Accept: */*
--- Perf Event ---
Process: curl, Type: RECV, Bytes: 1174
Data (first 1174 bytes):
HTTP/1.1 200 OK
Date: Sun, 02 Mar 2025 21:34:37 GMT
[...]
User-agent: *
Sitemap: https://www.hamza-megahed.com/sitemap.xml