This is the multi-page printable view of this section. Click here to print.
eBPF Taking off
- 1: bpf() syscall
- 2: eBPF Maps
- 3: eBPF Map Operations
- 4: eBPF Program Types
1 - bpf() syscall
Introduction to the bpf() System Call
The bpf() system call serves as a central mechanism in the Linux kernel for working with the Extended Berkeley Packet Filter (eBPF) subsystem. Originally introduced as a tool to filter packets in the kernel’s networking stack, Berkeley Packet Filters (BPF) allowed user space to define small programs that run efficiently in kernel space. Over time, this concept has evolved significantly from classic BPF (cBPF) to extended BPF (eBPF), which unlocks a far richer set of capabilities. The extended model supports versatile data structures, the ability to attach programs to a variety of kernel subsystems, and the invocation of helper functions that simplify complex operations.
The bpf() system call accepts a command argument determining the exact operation to be performed, and a corresponding attribute structure that passes parameters specific to that operation. Among these operations are commands to load eBPF programs into the kernel, create and manage eBPF maps, attach programs to hooks, and query or manipulate existing eBPF objects. This wide range of functionality makes bpf() a cornerstone of eBPF-based tooling in modern Linux systems.
The kernel ensures eBPF programs cannot crash or destabilize the system through rigorous static analysis at load time. As a result, the bpf() system call provides a secure yet flexible interface for extending kernel functionality.
In the /include/uapi/linux/bpf.h header file, you will find a list of all the commands used in the bpf() syscall. These commands define the actions that can be performed on eBPF objects, such as loading programs, creating maps, attaching programs to kernel events, and more. The commands are organized as part of the enum bpf_cmd, which is used as an argument to specify the desired operation when invoking the bpf() syscall.
Here’s an example of how the enum bpf_cmd is defined in the kernel source:
enum bpf_cmd {
BPF_MAP_CREATE,
BPF_MAP_LOOKUP_ELEM,
BPF_MAP_UPDATE_ELEM,
BPF_MAP_DELETE_ELEM,
BPF_MAP_GET_NEXT_KEY,
BPF_PROG_LOAD,
BPF_OBJ_PIN,
BPF_OBJ_GET,
BPF_PROG_ATTACH,
BPF_PROG_DETACH,
BPF_PROG_TEST_RUN,
BPF_PROG_RUN = BPF_PROG_TEST_RUN,
BPF_PROG_GET_NEXT_ID,
BPF_MAP_GET_NEXT_ID,
BPF_PROG_GET_FD_BY_ID,
BPF_MAP_GET_FD_BY_ID,
BPF_OBJ_GET_INFO_BY_FD,
BPF_PROG_QUERY,
BPF_RAW_TRACEPOINT_OPEN,
BPF_BTF_LOAD,
BPF_BTF_GET_FD_BY_ID,
BPF_TASK_FD_QUERY,
BPF_MAP_LOOKUP_AND_DELETE_ELEM,
BPF_MAP_FREEZE,
BPF_BTF_GET_NEXT_ID,
BPF_MAP_LOOKUP_BATCH,
BPF_MAP_LOOKUP_AND_DELETE_BATCH,
BPF_MAP_UPDATE_BATCH,
BPF_MAP_DELETE_BATCH,
BPF_LINK_CREATE,
BPF_LINK_UPDATE,
BPF_LINK_GET_FD_BY_ID,
BPF_LINK_GET_NEXT_ID,
BPF_ENABLE_STATS,
BPF_ITER_CREATE,
BPF_LINK_DETACH,
BPF_PROG_BIND_MAP,
BPF_TOKEN_CREATE,
__MAX_BPF_CMD,
};
We are not going through the full list but among these commands, one of the most important is bpf_prog_load. This command is used to load an eBPF program into the kernel. By invoking bpf() with the BPF_PROG_LOAD command, the kernel verifies the program’s safety, ensuring that it won’t cause any harm to the system. Upon success, the program is loaded into the kernel, and the system call returns a file descriptor associated with this eBPF program, allowing the program to be attached to various kernel events or subsystems, such as network interfaces, tracepoints, or XDP.
In the kernel’s BPF subsystem, specifically in kernel/bpf/syscall.c, a switch statement is used to dispatch commands defined by the enum bpf_cmd to their corresponding handler functions.
switch (cmd) {
case BPF_MAP_CREATE:
err = map_create(&attr);
break;
case BPF_MAP_LOOKUP_ELEM:
err = map_lookup_elem(&attr);
break;
case BPF_MAP_UPDATE_ELEM:
err = map_update_elem(&attr, uattr);
break;
case BPF_MAP_DELETE_ELEM:
err = map_delete_elem(&attr, uattr);
break;
case BPF_MAP_GET_NEXT_KEY:
err = map_get_next_key(&attr);
break;
case BPF_MAP_FREEZE:
err = map_freeze(&attr);
break;
case BPF_PROG_LOAD:
err = bpf_prog_load(&attr, uattr, size);
break;
[...]
Now, let’s take a closer look at how bpf_prog_load works in practice and how eBPF programs can be loaded into the kernel.
bpf_prog_load
As outlined in man 2 bpf, the bpf_prog_load operation is used to load an eBPF program into the Linux kernel via the bpf() syscall. When successful, this operation returns a new file descriptor associated with the loaded eBPF program. This file descriptor can then be used for operations such as attaching the program to specific kernel events (e.g., networking, tracing), checking its status, or even unloading it when necessary. The BPF_PROG_LOAD operation is invoked through the bpf() syscall to load the eBPF program into the kernel.
char bpf_log_buf[LOG_BUF_SIZE];
int bpf_prog_load(enum bpf_prog_type type,
const struct bpf_insn *insns, int insn_cnt,
const char *license)
{
union bpf_attr attr = {
.prog_type = type,
.insns = ptr_to_u64(insns),
.insn_cnt = insn_cnt,
.license = ptr_to_u64(license),
.log_buf = ptr_to_u64(bpf_log_buf),
.log_size = LOG_BUF_SIZE,
.log_level = 1,
};
return bpf(BPF_PROG_LOAD, &attr, sizeof(attr));
}
Key Parameters:
prog_type: Specifies the type of eBPF program (e.g., BPF_PROG_TYPE_XDP, BPF_PROG_TYPE_KPROBE).insns: The array of eBPF instructions (bytecode) that the program consists of.insn_cnt: The number of instructions in the insns array.license: This attribute specifies the license under which the eBPF program is distributed. It is important for ensuring compatibility with kernel helper functions that areGPL-only. Some eBPF helpers are restricted to being used only in programs that have a GPL-compatible license. Examples of such licenses include “GPL”, “GPL v2”, or “Dual BSD/GPL”. If the program’s license is not compatible with the GPL, it may not be allowed to invoke these specific helper functions.log_buf: A buffer where the kernel stores the verification log if the program fails verification.log_size: The size of the verification log buffer.
When a user-space process issues a BPF_PROG_LOAD command, the kernel invokes the bpf_prog_load(&attr, uattr, size) function which is defined in kernel/bpf/syscall.c kernel source code:
static int bpf_prog_load(union bpf_attr *attr, bpfptr_t uattr, u32 uattr_size)
{
enum bpf_prog_type type = attr->prog_type;
struct bpf_prog *prog, *dst_prog = NULL;
struct btf *attach_btf = NULL;
struct bpf_token *token = NULL;
bool bpf_cap;
int err;
char license[128];
[...]
libbpf Wrapper for bpf_prog_load
To simplify working with eBPF programs, libbpf provides the bpf_prog_load() function, which abstracts the complexity of interacting with the kernel via the bpf() syscall. This wrapper is located in /tools/lib/bpf/bpf.c and provides additional functionality like retrying failed program loads and setting detailed log options.
int bpf_prog_load(enum bpf_prog_type prog_type,
const char *prog_name, const char *license,
const struct bpf_insn *insns, size_t insn_cnt,
struct bpf_prog_load_opts *opts)
This function simplifies the process of loading eBPF programs by wrapping around the bpf() syscall, handling retries, and providing additional configuration options.
bpf_prog_load_opts structure: This structure provides additional configuration options when loading an eBPF program, as seen below:
struct bpf_prog_load_opts {
size_t sz; // Size of this structure for compatibility
int attempts; // Retry attempts if bpf() returns -EAGAIN
enum bpf_attach_type expected_attach_type; // Expected attachment type
__u32 prog_btf_fd; // BTF file descriptor
__u32 prog_flags; // Program flags
__u32 prog_ifindex; // Interface index for programs like XDP
__u32 kern_version; // Kernel version for compatibility
const int *fd_array; // Array of file descriptors for attachments
const void *func_info; // Function info for BTF
__u32 func_info_cnt; // Function info count
__u32 func_info_rec_size; // Function info record size
const void *line_info; // Line info for BTF
__u32 line_info_cnt; // Line info count
__u32 line_info_rec_size; // Line info record size
__u32 log_level; // Log verbosity for verifier logs
__u32 log_size; // Log buffer size
char *log_buf; // Log buffer
__u32 log_true_size; // Actual log size
__u32 token_fd; // Token file descriptor (optional)
__u32 fd_array_cnt; // Length of fd_array
size_t :0; // Padding for compatibility
};
At the heart of eBPF lies the concept of eBPF maps. Maps are generic, dynamic, kernel-resident data structures accessible from both eBPF programs and user space applications. They allow you to share state and pass information between user space and eBPF code.
The Linux man page (man 2 bpf) states:
eBPF maps are a generic data structure for storage of different data types. Data types are generally treated as binary blobs. A user just specifies the size of the key and the size of the value at map-creation time.
Now, let’s dive into the world of eBPF maps and explore how these powerful data structures are created, accessed, and used within the kernel. By understanding how to interact with maps, you’ll unlock the ability to efficiently store and retrieve data across different eBPF programs.
2 - eBPF Maps
Introduction to eBPF Maps
One of the key design elements that make eBPF so flexible and powerful is the concept of maps. An eBPF map is a data structure residing in the kernel, accessible both by eBPF programs and user space applications. Maps provide a stable way to share state, pass configuration or lookup data, store metrics, and build more complex logic around kernel events.
Unlike traditional kernel data structures, eBPF maps are created, managed, and destroyed via well-defined syscalls and helper functions. They offer a form of persistent kernel memory to eBPF programs, ensuring that data can outlast a single function call or event. This allows administrators and developers to build sophisticated tools for tracing, networking, security, performance monitoring, and more—without modifying or recompiling the kernel.
The Linux kernel defines numerous map types (more than 30 as of this writing), each optimized for different use cases. Some store generic key-value pairs, others store arrays or are used specifically for attaching events, referencing other maps, or implementing special data structures like tries. Choosing the right map type depends on the data and the operations you need to perform.
Before we start with explaining eBPF maps, we need to install either gcc or clang, along with libbpf-dev, to compile our examples. These tools are essential for building and linking the necessary components for eBPF programs. On Debian and Ubuntu, you can install them using the following command:
sudo apt install gcc libbpf-dev
Below, we explore ten commonly used eBPF map types, detailing their conceptual purpose, common use cases, and providing code snippets demonstrating their creation using the bpf_create_map() API.
From the large collection defined in the kernel’s /include/uapi/linux/bpf.h,
enum bpf_map_type {
BPF_MAP_TYPE_UNSPEC,
BPF_MAP_TYPE_HASH,
BPF_MAP_TYPE_ARRAY,
BPF_MAP_TYPE_PROG_ARRAY,
BPF_MAP_TYPE_PERF_EVENT_ARRAY,
BPF_MAP_TYPE_PERCPU_HASH,
BPF_MAP_TYPE_PERCPU_ARRAY,
BPF_MAP_TYPE_STACK_TRACE,
BPF_MAP_TYPE_CGROUP_ARRAY,
BPF_MAP_TYPE_LRU_HASH,
BPF_MAP_TYPE_LRU_PERCPU_HASH,
BPF_MAP_TYPE_LPM_TRIE,
BPF_MAP_TYPE_ARRAY_OF_MAPS,
BPF_MAP_TYPE_HASH_OF_MAPS,
BPF_MAP_TYPE_DEVMAP,
BPF_MAP_TYPE_SOCKMAP,
BPF_MAP_TYPE_CPUMAP,
BPF_MAP_TYPE_XSKMAP,
BPF_MAP_TYPE_SOCKHASH,
BPF_MAP_TYPE_CGROUP_STORAGE_DEPRECATED,
BPF_MAP_TYPE_CGROUP_STORAGE = BPF_MAP_TYPE_CGROUP_STORAGE_DEPRECATED,
BPF_MAP_TYPE_REUSEPORT_SOCKARRAY,
BPF_MAP_TYPE_PERCPU_CGROUP_STORAGE_DEPRECATED,
BPF_MAP_TYPE_PERCPU_CGROUP_STORAGE = BPF_MAP_TYPE_PERCPU_CGROUP_STORAGE_DEPRECATED,
BPF_MAP_TYPE_QUEUE,
BPF_MAP_TYPE_STACK,
BPF_MAP_TYPE_SK_STORAGE,
BPF_MAP_TYPE_DEVMAP_HASH,
BPF_MAP_TYPE_STRUCT_OPS,
BPF_MAP_TYPE_RINGBUF,
BPF_MAP_TYPE_INODE_STORAGE,
BPF_MAP_TYPE_TASK_STORAGE,
BPF_MAP_TYPE_BLOOM_FILTER,
BPF_MAP_TYPE_USER_RINGBUF,
BPF_MAP_TYPE_CGRP_STORAGE,
BPF_MAP_TYPE_ARENA,
__MAX_BPF_MAP_TYPE
};
we’ll focus on these ten map types:
- BPF_MAP_TYPE_HASH
- BPF_MAP_TYPE_ARRAY
- BPF_MAP_TYPE_PERF_EVENT_ARRAY
- BPF_MAP_TYPE_PROG_ARRAY
- BPF_MAP_TYPE_PERCPU_HASH
- BPF_MAP_TYPE_PERCPU_ARRAY
- BPF_MAP_TYPE_LPM_TRIE
- BPF_MAP_TYPE_ARRAY_OF_MAPS
- BPF_MAP_TYPE_HASH_OF_MAPS
- BPF_MAP_TYPE_RINGBUF
These map types are either widely used or particularly illustrative of eBPF’s capabilities. Together, they represent a broad spectrum of data structures and functionalities.
Maps in eBPF program
In eBPF, there are two main components: the eBPF program (which runs in the kernel) and the user-space code (both components will be explained later). It is common to define maps in the eBPF program, but maps are actually created and managed in user-space using the bpf() syscall.
The eBPF program (kernel-side) defines how the map should look and how it will be used by the program. This definition specifies the map’s type, key size, value size, and other parameters. However, the actual creation of the map (allocating memory for it in the kernel and linking it to the eBPF program) occurs in user-space. This process involves invoking the bpf() syscall with the BPF_MAP_CREATE command.
In practice, BTF (BPF Type Format) style maps are the preferred method for defining maps in eBPF programs. Using BTF provides a more flexible, type-safe way to define maps and makes it easier to manage complex data structures. We will explain BTF (BPF Type Format) later in details. When a user-space process issues a BPF_MAP_CREATE command, the kernel invokes the map_create(&attr) function which look like the following:
static int map_create(union bpf_attr *attr)
{
const struct bpf_map_ops *ops;
struct bpf_token *token = NULL;
int numa_node = bpf_map_attr_numa_node(attr);
u32 map_type = attr->map_type;
struct bpf_map *map;
bool token_flag;
int f_flags;
[...]
The bpf_map_create() function is part of the libbpf library, which provides a user-space interface for interacting with eBPF in Linux. Internally, bpf_map_create() sets up the necessary parameters for creating an eBPF map and then makes a call to the bpf() syscall with the BPF_MAP_CREATE command. This function simplifies the process for the user by abstracting away the complexities of directly using the bpf() syscall. It configures the map, including its type, key size, value size, and the number of entries, and once these parameters are prepared, bpf_map_create() invokes the bpf() syscall with the BPF_MAP_CREATE command, instructing the kernel to create the eBPF map. In essence, bpf_map_create() serves as a user-friendly wrapper around the bpf() syscall’s BPF_MAP_CREATE command or map_create function, making it easier for user-space programs to create eBPF maps.
bpf_map_create() wrapper function is defined in the Kernel source code under tools/lib/bpf/bpf.c. The function prototype is as follows:
int bpf_map_create(enum bpf_map_type map_type,
const char *map_name,
__u32 key_size,
__u32 value_size,
__u32 max_entries,
const struct bpf_map_create_opts *opts);
map_type: Specifies the type of the map (e.g.,BPF_MAP_TYPE_HASH).map_name: The name of the map.key_size: Size of the key in the map.value_size: Size of the value in the map.max_entries: Maximum number of entries the map can hold.opts: A pointer to thebpf_map_create_optsstructure, which contains additional options for map creation (such as flags, BTF information, etc.).
The definition for the bpf_map_create_opts structure, part of libbpf, can be found in /tools/lib/bpf/bpf.h
struct bpf_map_create_opts {
size_t sz; /* Size of this struct for forward/backward compatibility */
__u32 btf_fd; /* BTF (BPF Type Format) file descriptor for type information */
__u32 btf_key_type_id; /* BTF key type ID for the map */
__u32 btf_value_type_id; /* BTF value type ID for the map */
__u32 btf_vmlinux_value_type_id; /* BTF vmlinux value type ID for maps */
__u32 inner_map_fd; /* File descriptor for an inner map (for nested maps) */
__u32 map_flags; /* Flags for the map (e.g., read-only, etc.) */
__u64 map_extra; /* Extra space for future expansion or additional settings */
__u32 numa_node; /* NUMA node to assign the map */
__u32 map_ifindex; /* Network interface index for map assignment */
__s32 value_type_btf_obj_fd; /* File descriptor for the BTF object corresponding to the value type */
__u32 token_fd; /* BPF token FD passed in a corresponding command's token_fd field */
size_t :0; /* Reserved for future compatibility (bitfield) */
};
sz: Size of the structure, ensuring forward/backward compatibility.btf_fd,btf_key_type_id,btf_value_type_id, andbtf_vmlinux_value_type_id: These fields are related to theBPF Type Format(BTF), which provides type information for the map’s key and value typesinner_map_fd: The file descriptor of an inner map if the map is being used as part of a nested structure.map_flags: Flags that modify the behavior of the map, such as setting the map to read-only or enabling special features (e.g., memory-mapping).map_extra: Reserved for future extensions to the structure or additional configuration.numa_node: Specifies the NUMA node for memory locality when creating the map (used for NUMA-aware systems).map_ifindex: Specifies the network interface index for associating the map with a specific network interface.value_type_btf_obj_fd: A file descriptor pointing to the BTF object representing the map’s value type.token_fd: A token FD for passing file descriptors across different BPF operations.
These fields allow for fine-grained control over how the eBPF map behaves, including its memory allocation, access permissions, and type information. Don’t worry about these details now, as some of them will be used shortly when we dive into more examples.
Now that we’ve covered the basics of map creation, let’s start exploring some of the most commonly used eBPF map types.
Note
All the following snippets of code use different contexts for working with the same BPF map. “The Map Definition in eBPF Program” snippet is used within the eBPF kernel code to declare the map (using section annotations likeSEC(".maps")) so that the eBPF program can use it. The “Hash Map User-Space Example snippet”, on the other hand, shows how user-space code (using libbpf and BPF syscalls) can interact with the map—such as creating or obtaining a file descriptor for the map.
1. Hash Map
A hash map stores key-value pairs. Each key maps to a corresponding value, and both the key and value have fixed sizes determined at creation time. The hash map provides fast lookups and updates, making it a great choice for data that changes frequently. Common uses include tracking connection states in networking, counting events keyed by process ID or file descriptor, or caching metadata for quick lookups.
BTF Map Definition in eBPF Program
struct {
__uint(type, BPF_MAP_TYPE_HASH);
__type(key, int);
__type(value, int);
__uint(max_entries, 1024);
} hash_map_example SEC(".maps");
Hash Map User-Space Example
#include <bpf/libbpf.h>
#include <bpf/bpf.h>
#include <errno.h>
#include <unistd.h>
int create_hash_map(void) {
int fd = bpf_map_create(BPF_MAP_TYPE_HASH, "hash_map_example",
sizeof(int), // key_size
sizeof(int), // value_size
1024, // max_entries
NULL); // map_flags
if (fd < 0) {
fprintf(stderr, "Failed to create hash map: %s\n", strerror(errno));
}
return fd;
}
int main() {
int fd = create_hash_map();
if (fd >= 0) {
printf("Hash map created successfully with fd: %d\n", fd);
close(fd);
}
return 0;
}
We can compile it using gcc -o hash_map hash_map.c -lbpf and -lbpf which tells the compiler to link against the libbpf library, or by using clang -o ring_buff ring_buff.c -lbpf
Note
You should always useclose() when you’re done using a BPF map file descriptor to ensure proper resource management, prevent resource leaks, and allow the system to release the map’s resources.
Note
Loading most eBPF programs into the kernel requires root privileges, as they require access to restricted kernel resources and system calls. However, it’s possible for non-root users to load eBPF programs if they have been granted specific capabilities, such asCAP_BPF.
To run this program, you need to use the sudo commandsudo ./hash_map
2. Array Map
An array map stores a fixed number of elements indexed by integer keys. Unlike a hash map, array keys are not arbitrary—they are simply indexes from 0 to max_entries -1. This simplifies lookups and can provide stable, predictable memory usage. Array maps are perfect for scenarios where you know the exact number of elements you need and require constant-time indexed access. Typical uses include lookup tables, static configuration data, or indexing CPU-related counters by CPU number.
BTF Map Definition in eBPF Program
struct {
__uint(type, BPF_MAP_TYPE_ARRAY);
__type(key, int);
__type(value, int);
__uint(max_entries, 256);
} array_map_example SEC(".maps");
Array Map User-Space Example
#include <bpf/libbpf.h>
#include <bpf/bpf.h>
#include <errno.h>
#include <unistd.h>
int create_array_map(void) {
int fd = bpf_map_create(BPF_MAP_TYPE_ARRAY, "array_map_example",
sizeof(int), // key_size
sizeof(int), // value_size
256, // max_entries
NULL); // map_flags
if (fd < 0) {
fprintf(stderr, "Failed to create array map: %s\n", strerror(errno));
}
return fd;
}
int main() {
int fd = create_array_map();
if (fd >= 0) {
printf("Array map created successfully with fd: %d\n", fd);
close(fd);
}
return 0;
}
3. Perf Event Array Map
The Perf Event Array map provides a mechanism to redirect perf events (such as hardware counters or software events) into user space using the perf ring buffer infrastructure. By attaching eBPF programs to perf events and using this map, you can efficiently gather performance metrics from the kernel, making it a cornerstone of low-overhead performance monitoring and observability tools.

BTF Map Definition in eBPF Program
struct {
__uint(type, BPF_MAP_TYPE_PERF_EVENT_ARRAY);
__type(key, int);
__type(value, int);
__uint(max_entries, 64);
} perf_event_array_example SEC(".maps");
Note
You can ignoremax_entries as it will be set automatically to the number of CPUs on your computer by libbpf as per https://nakryiko.com/posts/bpf-ringbuf/.
Pert Event Array Map User-Space Example
#include <bpf/libbpf.h>
#include <bpf/bpf.h>
#include <errno.h>
#include <unistd.h>
int create_perf_event_array_map(void) {
int fd = bpf_map_create(BPF_MAP_TYPE_PERF_EVENT_ARRAY, "perf_event_array_example",
sizeof(int), // key_size
sizeof(int), // value_size (fd)
64, // max_entries (for events)
NULL); // map_flags
if (fd < 0) {
fprintf(stderr, "Failed to create perf event array map: %s\n", strerror(errno));
}
return fd;
}
int main() {
int fd = create_perf_event_array_map();
if (fd >= 0) {
printf("perf event array map created successfully with fd: %d\n", fd);
close(fd);
}
return 0;
}
4. Prog Array Map
A program array holds references to other eBPF programs, enabling tail calls. Tail calls allow one eBPF program to jump into another without returning, effectively chaining multiple programs into a pipeline. This map type is essential for building modular and dynamic eBPF toolchains that can be reconfigured at runtime without reloading the entire set of programs.
BTF Map Definition in eBPF Program
struct {
__uint(type, BPF_MAP_TYPE_PROG_ARRAY);
__type(key, int);
__type(value, int);
__uint(max_entries, 32);
} prog_array_example SEC(".maps");
Prog Array Map User-Space Example
#include <bpf/libbpf.h>
#include <bpf/bpf.h>
#include <errno.h>
#include <unistd.h>
int create_prog_array_map(void) {
int fd = bpf_map_create(BPF_MAP_TYPE_PROG_ARRAY, "prog_array_example",
sizeof(int), // key_size
sizeof(int), // value_size (prog FD)
32, // max_entries
NULL);
if (fd < 0) {
fprintf(stderr, "Failed to create prog array map: %s\n", strerror(errno));
}
return fd;
}
int main() {
int fd = create_prog_array_map();
if (fd >= 0) {
printf("Prog array map created successfully with fd: %d\n", fd);
close(fd);
}
return 0;
}
5. PERCPU Hash Map
A per-CPU hash map is similar to a standard hash map but stores distinct values for each CPU. This design minimizes lock contention and cache-line ping-ponging, allowing for extremely high-performance counting or state tracking when updates are frequent. Each CPU updates its own version of the value, and user space can aggregate these values later.
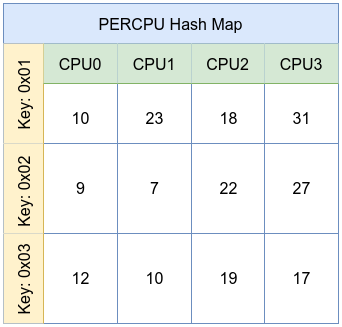
BTF Map Definition in eBPF Program
struct {
__uint(type, BPF_MAP_TYPE_PERCPU_HASH);
__type(key, int);
__type(value, int);
__uint(max_entries, 1024);
} percpu_hash_example SEC(".maps");
PERCPU Hash Map User-Space Example
#include <bpf/libbpf.h>
#include <bpf/bpf.h>
#include <errno.h>
#include <unistd.h>
int create_percpu_hash_map(void) {
int fd = bpf_map_create(BPF_MAP_TYPE_PERCPU_HASH, "percpu_hash_example",
sizeof(int), // key_size
sizeof(int), // value_size
1024, // max_entries
NULL);
if (fd < 0) {
fprintf(stderr, "Failed to create PERCPU hash map: %s\n", strerror(errno));
}
return fd;
}
int main() {
int fd = create_percpu_hash_map();
if (fd >= 0) {
printf("PERCPU hash map created successfully with fd: %d\n", fd);
close(fd);
}
return 0;
}
6. PERCPU Array Map
A per-CPU array, like the per-CPU hash, stores distinct copies of array elements for each CPU. This further reduces contention, making it ideal for per-CPU statistics counters, histograms, or other metrics that need to be incremented frequently without facing synchronization overhead.
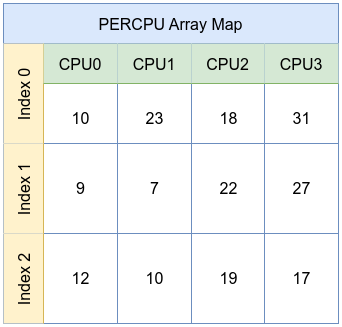
BTF Map Definition in eBPF Program
struct {
__uint(type, BPF_MAP_TYPE_PERCPU_ARRAY);
__type(key, int);
__type(value, int);
__uint(max_entries, 1024);
} percpu_array_example SEC(".maps");
PERCPU Array Map User-Space Example
#include <bpf/libbpf.h>
#include <bpf/bpf.h>
#include <errno.h>
#include <unistd.h>
int create_percpu_array_map(void) {
int fd = bpf_map_create(BPF_MAP_TYPE_PERCPU_ARRAY, "percpu_array_example",
sizeof(int), // key_size
sizeof(int), // value_size
128, // max_entries
NULL);
if (fd < 0) {
fprintf(stderr, "Failed to create PERCPU array map: %s\n", strerror(errno));
}
return fd;
}
int main() {
int fd = create_percpu_array_map();
if (fd >= 0) {
printf("PERCPU array map created successfully with fd: %d\n", fd);
close(fd);
}
return 0;
}
7. LPM Trie Map
The LPM (Longest Prefix Match) Trie map is designed for prefix-based lookups, commonly used in networking. For example, you might store IP prefixes (like CIDR blocks) and quickly determine which prefix best matches a given IP address. This is useful for routing, firewall rules, or policy decisions based on IP addresses.
Note
When creating an LPM Trie map, it is important to use theBPF_F_NO_PREALLOC flag. This flag prevents the kernel from pre-allocating memory for all entries at map creation time, allowing the map to dynamically allocate memory as needed.
For example, if you create a map that is intended to hold 1,000 entries, the kernel might allocate memory for all 1,000 entries at map creation time. However, in the case of an LPM Trie map, the situation is different. An LPM Trie map is used for prefix-based lookups, such as storing CIDR blocks or IP address prefixes for example 192.168.0.0/24. The number of entries and the amount of memory required for the map can vary depending on the data stored. You can still specify a max_entries value when creating an LPM Trie map, but it is important to note that the kernel will ignore this value. The actual number of entries in an LPM Trie map depends on how many prefixes are inserted, and the map dynamically allocates memory based on the prefixes.
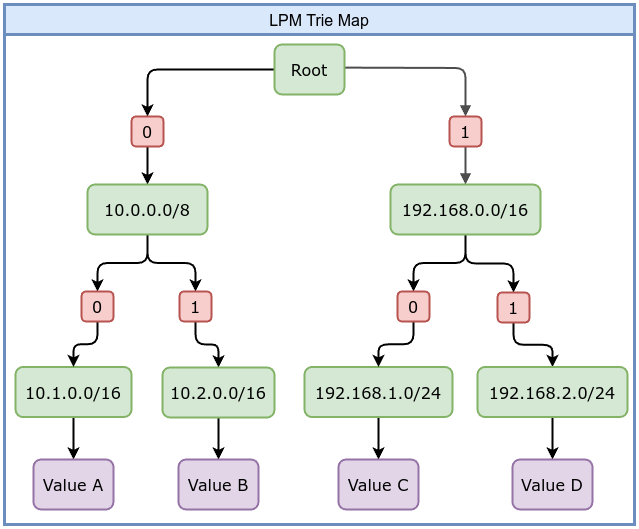
BTF Map Definition in eBPF Program
struct {
__uint(type, BPF_MAP_TYPE_LPM_TRIE);
__type(key, int);
__type(value, int);
__uint(max_entries, 1024);
} lpm_trie_example SEC(".maps");
LPM Trie Map User-Space Example
#include <bpf/libbpf.h>
#include <bpf/bpf.h>
#include <errno.h>
#include <unistd.h>
int create_lpm_trie_map(void) {
struct bpf_map_create_opts opts = {0};
opts.sz = sizeof(opts);
opts.map_flags = BPF_F_NO_PREALLOC;
int fd = bpf_map_create(BPF_MAP_TYPE_LPM_TRIE, "lpm_trie_example",
8, // key_size
sizeof(long), // value_size
1024, // max_entries and it will ignored
&opts);
if (fd < 0) {
fprintf(stderr, "Failed to create LMP trie map: %s\n", strerror(errno));
}
return fd;
}
int main() {
int fd = create_lpm_trie_map();
if (fd >= 0) {
printf("LMP trie map created successfully with fd: %d\n", fd);
close(fd);
}
return 0;
}
8. Array of Maps Map
An array-of-maps stores references to other maps. Each element in this array is itself a map FD. This structure allows building hierarchical or modular configurations. For example, you might keep a set of hash maps, each representing a different tenant or set of rules, and select which one to use at runtime by indexing into the array-of-maps. In the following example, we will first create a hash map to serve as the inner map, and then use this hash map as the reference for creating an array of maps.
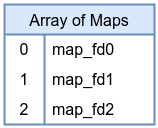
BTF Map Definition in eBPF Program
struct inner_map {
__uint(type, BPF_MAP_TYPE_HASH);
__type(key, int);
__type(value, int);
__uint(max_entries, 1024);
} hash_map_example SEC(".maps");
struct {
__uint(type, BPF_MAP_TYPE_ARRAY_OF_MAPS);
__type(key, int);
__type(value, int);
__uint(max_entries, 4);
__array(values, struct {
__uint(type, BPF_MAP_TYPE_HASH);
__type(key, int);
__type(value, int);
__uint(max_entries, 1024);
});
} array_of_maps_map_example SEC(".maps");
Array of Maps Map User-Space Example
#include <bpf/libbpf.h>
#include <bpf/bpf.h>
#include <errno.h>
#include <unistd.h>
int create_inner_hash_map(void) {
int fd = bpf_map_create(BPF_MAP_TYPE_HASH, "hash_map_example",
sizeof(int), // key_size
sizeof(int), // value_size
1024, // max_entries
NULL); // map_flags
if (fd < 0) {
fprintf(stderr, "Failed to create hash map: %s\n", strerror(errno));
}
return fd;
}
int create_array_of_maps(int inner_map_fd) {
struct bpf_map_create_opts opts = {0};
opts.sz = sizeof(opts);
opts.inner_map_fd = inner_map_fd; // Specify the inner map FD
int fd = bpf_map_create(BPF_MAP_TYPE_ARRAY_OF_MAPS, "array_of_maps_map_example",
sizeof(int), // key_size
sizeof(int), // value_size (placeholder for map FD)
4, // max_entries
&opts);
if (fd < 0) {
fprintf(stderr, "Failed to create Array of maps map: %s\n", strerror(errno));
}
return fd;
}
int main() {
// Step 1: Create the inner hash map
int inner_map_fd = create_inner_hash_map();
if (inner_map_fd >= 0) {
printf("Hash map created successfully with fd: %d\n", inner_map_fd);
close(inner_map_fd);
}
// Step 2: Create the array of maps, using the inner map FD
int array_of_maps_fd = create_array_of_maps(inner_map_fd);
if (array_of_maps_fd >= 0) {
printf("Array of maps map created successfully with fd: %d\n", array_of_maps_fd);
close(array_of_maps_fd);
}
if (inner_map_fd >= 0) {
close(inner_map_fd);
}
if (array_of_maps_fd >= 0) {
close(array_of_maps_fd);
}
return 0;
}
9. Hash of Maps Maps
A hash-of-maps extends the concept of array-of-maps to dynamic keying. Instead of indexing by integer, you can use arbitrary keys to select which map is referenced. This allows flexible and dynamic grouping of maps, where user space can manage complex configurations by updating keys and associated map FDs. Again, bpf_create_map() cannot set inner_map_fd, so this example is minimal.
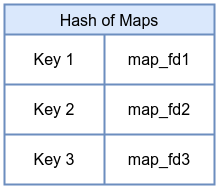
BTF Map Definition in eBPF Program
struct inner_map {
__uint(type, BPF_MAP_TYPE_HASH);
__type(key, int);
__type(value, int);
__uint(max_entries, 1024);
} hash_map_example SEC(".maps");
struct {
__uint(type, BPF_MAP_TYPE_HASH_OF_MAPS);
__type(key, int);
__type(value, int);
__uint(max_entries, 4);
__array(values, struct {
__uint(type, BPF_MAP_TYPE_HASH);
__type(key, int);
__type(value, int);
__uint(max_entries, 1024);
});
} hash_of_maps_map_example SEC(".maps");
Hash of Maps Map User-Space Example
#include <bpf/libbpf.h>
#include <bpf/bpf.h>
#include <errno.h>
#include <unistd.h>
int create_inner_hash_map(void) {
int fd = bpf_map_create(BPF_MAP_TYPE_HASH, "hash_map_example",
sizeof(int), // key_size
sizeof(int), // value_size
1024, // max_entries
NULL); // map_flags
if (fd < 0) {
fprintf(stderr, "Failed to create hash map: %s\n", strerror(errno));
}
return fd;
}
int create_hash_of_maps(int inner_map_fd) {
struct bpf_map_create_opts opts = {0};
opts.sz = sizeof(opts);
opts.inner_map_fd = inner_map_fd; // Specify the inner map FD
int fd = bpf_map_create(BPF_MAP_TYPE_HASH_OF_MAPS, "hash_of_maps_map_example",
sizeof(int), // key_size
sizeof(int), // value_size (placeholder for map FD)
4, // max_entries
&opts);
if (fd < 0) {
fprintf(stderr, "Failed to create hash of maps map: %s\n", strerror(errno));
}
return fd;
}
int main() {
// Step 1: Create the inner hash map
int inner_map_fd = create_inner_hash_map();
if (inner_map_fd >= 0) {
printf("Hash map created successfully with fd: %d\n", inner_map_fd);
}
// Step 2: Create the array of maps, using the inner map FD
int array_of_maps_fd = create_hash_of_maps(inner_map_fd);
if (array_of_maps_fd >= 0) {
printf("Array_of_maps map created successfully with fd: %d\n", array_of_maps_fd);
}
if (inner_map_fd >= 0) {
close(inner_map_fd);
}
if (array_of_maps_fd >= 0) {
close(array_of_maps_fd);
}
return 0;
}
10. Ring Buffer Map
The ring buffer map is a relatively new addition that enables lock-free communication from kernel to user space. Instead of performing lookups or updates for each record, the kernel-side eBPF program writes events into the ring buffer, and user space reads them as a continuous stream. A ring buffer is a circular data structure that uses a continuous block of memory to store data sequentially. When data is added to the buffer and the end is reached, new data wraps around to the beginning, potentially overwriting older data if it hasn’t been read yet.
A typical ring buffer uses two pointers (or “heads”): one for writing and one for reading. The write pointer marks where new data is added, while the read pointer indicates where data should be consumed. This dual-pointer system allows for efficient and concurrent operations, ensuring that the writer doesn’t overwrite data before the reader has processed it. Additionally, the ring buffer is shared across all CPUs, consolidating events from multiple cores into a single stream. This greatly reduces overhead for high-volume event reporting, making it ideal for profiling, tracing, or continuous monitoring tools.
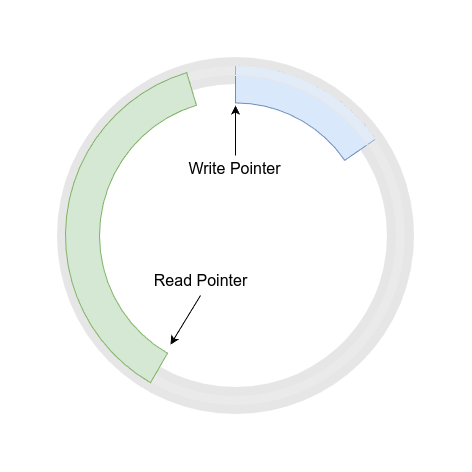
BTF Map Definition in eBPF Program
struct {
__uint(type, BPF_MAP_TYPE_RINGBUF);
__uint(max_entries, 4096); //It must be a power of 2
} ring_buffer_map_example SEC(".maps");
Note
max_entries in BPF_MAP_TYPE_RINGBUF must be a power of 2 such as 4096.
Ring Buffer Map User-Space Example
#include <bpf/libbpf.h>
#include <bpf/bpf.h>
#include <errno.h>
#include <unistd.h>
int create_ringbuf_map(void) {
// The size of the ringbuf is given in bytes by max_entries.
int fd = bpf_map_create(BPF_MAP_TYPE_RINGBUF, "ring_buffer_map_example",
0, // key_size = 0 for ringbuf
0, // value_size = 0 for ringbuf
4096,
NULL);
if (fd < 0) {
fprintf(stderr, "Failed to create ring buffer map: %s\n", strerror(errno));
}
return fd;
}
int main() {
int fd = create_ringbuf_map();
if (fd >= 0) {
printf("Ring buffer map created successfully with fd: %d\n", fd);
close(fd);
}
return 0;
}
The Right eBPF Map Type
By combining these map types with your eBPF programs, you can build sophisticated, runtime-configurable kernel instrumentation, security monitors, network traffic analyzers, and performance profiling tools. Each map type adds a new capability or performance characteristic, allowing developers to craft solutions that were previously challenging or impossible without kernel modifications. This flexibility not only enhances existing solutions but also opens up new possibilities for kernel-level programming. Given the ongoing evolution of eBPF, selecting the right map type for your use case becomes even more important. When doing so, it’s essential to consider factors such as access patterns, data size, performance requirements, and the complexity of your architecture. Here are some things to keep in mind:
- Access Pattern and Data Size:
If you have a known, fixed number of entries indexed by integer keys, the ideal choice might be a
BPF_MAP_TYPE_ARRAY. If keys are dynamic or unpredictable,BPF_MAP_TYPE_HASHmight be the go-to. - Performance and Concurrency:
Under heavy load, where multiple CPUs frequently update shared data, per-CPU maps (
BPF_MAP_TYPE_PERCPU_HASHorBPF_MAP_TYPE_PERCPU_ARRAY) can reduce contention. Similarly,BPF_MAP_TYPE_RINGBUFis the perfect fit for high-throughput streaming scenarios. - Complexity and Modularity:
If you need to dynamically chain programs or manage multiple maps at runtime, you could use
BPF_MAP_TYPE_PROG_ARRAY,BPF_MAP_TYPE_ARRAY_OF_MAPS, orBPF_MAP_TYPE_HASH_OF_MAPSto facilitate more sophisticated architectures. - Networking and Prefix Matching:
For IP-based lookups,
BPF_MAP_TYPE_LPM_TRIEoffers a specialized structure optimized for network prefixes and routing logic. - Observability and Tracing:
BPF_MAP_TYPE_PERF_EVENT_ARRAYties into the Linux perf subsystem, enabling advanced performance monitoring and event correlation in conjunction with eBPF programs.
3 - eBPF Map Operations
eBPF Map Operations Overview
eBPF map operations are a set of functions defined in the Linux kernel that allow interaction with eBPF maps. These operations enable reading, writing, deleting, and managing data within the maps. The operations are part of the bpf_cmd defined in the kernel source file /include/uapi/linux/bpf.h. Some commonly used operations include:
BPF_MAP_CREATE: Creates a new eBPF map. This operation sets up a map.BPF_MAP_UPDATE_ELEM: Inserts or updates a key-value pair.BPF_MAP_LOOKUP_ELEM: Retrieves the value associated with a given key.BPF_MAP_DELETE_ELEM: Deletes a key-value pair by its key.BPF_MAP_LOOKUP_AND_DELETE_ELEM: Retrieves a value by key and deletes the entry in one step.BPF_MAP_GET_NEXT_KEY: Iterates through the keys in the map.BPF_MAP_LOOKUP_BATCH: Retrieves multiple entries in a single call.BPF_MAP_UPDATE_BATCH: Updates multiple entries at once.BPF_MAP_DELETE_BATCH: Deletes multiple entries in one operation.BPF_MAP_FREEZE: Converts the map into a read-only state.BPF_OBJ_PIN: Pins the map to the BPF filesystem so it persists beyond the process’s lifetime.BPF_OBJ_GET: Retrieves a previously pinned map.
These operations allow efficient data sharing between eBPF programs and user-space applications. The bpf() syscall is used to perform these operations, providing a flexible interface for interacting with eBPF maps. Each operation serves a specific purpose.
In this chapter, we have already explained BPF_MAP_CREATE in detail , so we will not cover it again. Instead, we will focus on the rest. We will show how to use them with a simple hash map and explain the code thoroughly.
Some map operations differ between user-space and kernel-space code. In user-space, you interact with eBPF maps using file descriptors and functions that often require an output parameter, Libbpf provides convenient wrappers for these commands which are defined in tools/lib/bpf/bpf.c.
int bpf_map_update_elem(int fd, const void *key, const void *value,
__u64 flags)
{
const size_t attr_sz = offsetofend(union bpf_attr, flags);
union bpf_attr attr;
int ret;
memset(&attr, 0, attr_sz);
attr.map_fd = fd;
attr.key = ptr_to_u64(key);
attr.value = ptr_to_u64(value);
attr.flags = flags;
ret = sys_bpf(BPF_MAP_UPDATE_ELEM, &attr, attr_sz);
return libbpf_err_errno(ret);
}
int bpf_map_lookup_elem(int fd, const void *key, void *value)
{
const size_t attr_sz = offsetofend(union bpf_attr, flags);
union bpf_attr attr;
int ret;
memset(&attr, 0, attr_sz);
attr.map_fd = fd;
attr.key = ptr_to_u64(key);
attr.value = ptr_to_u64(value);
ret = sys_bpf(BPF_MAP_LOOKUP_ELEM, &attr, attr_sz);
return libbpf_err_errno(ret);
}
[...]
whereas in kernel-space (within eBPF programs) perform equivalent operations using built-in helper functions which are defined in kernel/bpf/helpers.c.
BPF_CALL_2(bpf_map_lookup_elem, struct bpf_map *, map, void *, key)
{
WARN_ON_ONCE(!rcu_read_lock_held() && !rcu_read_lock_trace_held() &&
!rcu_read_lock_bh_held());
return (unsigned long) map->ops->map_lookup_elem(map, key);
}
const struct bpf_func_proto bpf_map_lookup_elem_proto = {
.func = bpf_map_lookup_elem,
.gpl_only = false,
.pkt_access = true,
.ret_type = RET_PTR_TO_MAP_VALUE_OR_NULL,
.arg1_type = ARG_CONST_MAP_PTR,
.arg2_type = ARG_PTR_TO_MAP_KEY,
};
BPF_CALL_4(bpf_map_update_elem, struct bpf_map *, map, void *, key,
void *, value, u64, flags)
{
WARN_ON_ONCE(!rcu_read_lock_held() && !rcu_read_lock_trace_held() &&
!rcu_read_lock_bh_held());
return map->ops->map_update_elem(map, key, value, flags);
}
Additionally, some operations—like batch operations and object pinning/getting—are implemented in the kernel but are intended to be invoked from user-space via system calls or libbpf rather than being used directly inside eBPF programs. We’ll explain each operation in both contexts.
1. Map Update Element
User-Space code
BPF_MAP_UPDATE_ELEM command inserts or updates a key-value pair in the map.
The function bpf_map_update_elem is a libbpf wrapper for BPF_MAP_UPDATE_ELEM command, it’s part of the libbpf library, which provides a user-space interface for interacting with eBPF maps in the Linux kernel with prototype as follows:
int bpf_map_update_elem(int fd, const void *key, const void *value, __u64 flags);
It takes a map file descriptor, pointers to the key and value, and a flag indicating how the update should be performed. The flag can be
BPF_NOEXISTto insert only if the key does not exist.BPF_EXISTto update only if the key already exists.BPF_ANYto insert or update unconditionally. On success, this call returns zero. On failure, it returns -1 and setserrnoto indicate the cause of the error. For instance, if you useBPF_NOEXISTbut the key already exists, it returnsEEXIST. If you useBPF_EXISTbut the key does not exist, it returnsENOENTwhich isNo such file or directory.
Note
BPF_NOEXIST isn’t supported for array type maps since all keys always exist.
Here is an example that first tries to insert a new element using BPF_NOEXIST and then updates it using BPF_EXIST:
#include <bpf/libbpf.h>
#include <bpf/bpf.h>
#include <errno.h>
#include <unistd.h>
int create_hash_map(void) {
int fd = bpf_map_create(BPF_MAP_TYPE_HASH, "hash_map_example",
sizeof(int), // key_size
sizeof(int), // value_size
1024, // max_entries
NULL); // map_flags
if (fd < 0) {
fprintf(stderr, "Failed to create hash map: %s\n", strerror(errno));
}
return fd;
}
int main() {
int fd = create_hash_map();
if (fd >= 0) {
printf("Hash map created successfully with fd: %d\n", fd);
// Insert elements in the hash map
int key = 5;
long value = 100;
if (bpf_map_update_elem(fd, &key, &value, BPF_ANY) == 0) { // BPF_ANY means insert or update
printf("Element inserted or updated successfully: key = %d, value = %ld\n", key, value);
} else {
fprintf(stderr, "Failed to insert or update element: %s\n", strerror(errno));
close(fd); // Close the map before returning
return -1;
}
// Update an element in the hash map
value = 200;
if (bpf_map_update_elem(fd, &key, &value, BPF_EXIST) == 0) {
printf("Element inserted or updated successfully: key = %d, value = %ld\n", key, value);
} else {
fprintf(stderr, "Failed to insert or update element: %s\n", strerror(errno));
close(fd); // Close the map before returning
return -1;
}
// Update an element that doesn't exist in the hash map
key = 4;
value = 300;
if (bpf_map_update_elem(fd, &key, &value, BPF_EXIST) == 0) {
printf("Element inserted or updated successfully: key = %d, value = %ld\n", key, value);
} else {
fprintf(stderr, "Failed to insert or update element: %s\n", strerror(errno));
close(fd); // Close the map before returning
return -1;
}
close(fd);
return 0;
}
return -1;
}
To compile and run the program, use the following command: gcc -o update-ebpf-map update-ebpf-map.c -lbpf.
Then, execute the program with: sudo ./update-ebpf-map.
We first create a map and then insert (5 -> 100) using BPF_ANY, which either inserts or updates unconditionally. Since the map was empty, (5 -> 100) is inserted. Next, we update (5 -> 100) to (5 -> 200) using BPF_EXIST, ensuring that the key must exist beforehand. The operation succeeds, and the value associated with key 5 is now 200.
Then, we try to insert (4 -> 300) using BPF_EXIST, which requires the key to already exist in the map. Since the key 4 does not exist in the map, the operation fails, and the error ENOENT is triggered, resulting in the message “Failed to insert or update element: No such file or directory.”
The output from running the program (sudo ./update-ebpf-map) is as follows:
Hash map created successfully with fd: 3
Element inserted or updated successfully: key = 5, value = 100
Element inserted or updated successfully: key = 5, value = 200
Failed to insert or update element: No such file or directory
Kernel-Space code
int bpf_map_update_elem(void *map, const void *key, const void *value, __u64 flags);
2. Map Lookup Element
User-Space code
BPF_MAP_LOOKUP_ELEM command is used to retrieve the value associated with a given key. The bpf_map_lookup_elem function is a libbpf wrapper for BPF_MAP_LOOKUP_ELEM command and its prototype is : int bpf_map_lookup_elem(int fd, const void *key, void *value) , so you provide the map’s file descriptor, a pointer to the key you want to look up, and a pointer to a buffer where the value will be stored if the key is found. If the operation succeeds, it returns zero, and the value is copied into the user-provided buffer. If the key does not exist, it returns -1 and sets errno to ENOENT.
Consider a scenario where you have inserted an entry (key=10, value=100) into the map. Looking it up would look like this:
#include <bpf/libbpf.h>
#include <bpf/bpf.h>
#include <errno.h>
#include <unistd.h>
int create_hash_map(void) {
int fd = bpf_map_create(BPF_MAP_TYPE_HASH, "hash_map_example",
sizeof(int), // key_size
sizeof(int), // value_size
1024, // max_entries
NULL); // map_flags
if (fd < 0) {
fprintf(stderr, "Failed to create hash map: %s\n", strerror(errno));
}
return fd;
}
int main() {
int fd = create_hash_map();
if (fd >= 0) {
printf("Hash map created successfully with fd: %d\n", fd);
// Insert a single entry: (10 -> 100)
int key = 10;
int value = 100;
if (bpf_map_update_elem(fd, &key, &value, BPF_ANY) == 0) {
printf("Element inserted or updated successfully: key = %d, value = %ld\n", key, value);
} else {
fprintf(stderr, "Failed to insert or update element: %s\n", strerror(errno));
close(fd);
return -1;
}
// Attempt to look up the value for key=10
int lookup_key = 10;
int lookup_val = 0;
if (bpf_map_lookup_elem(fd, &lookup_key, &lookup_val) == 0) {
printf("Found value %d for key %d\n", lookup_val, lookup_key);
} else {
fprintf(stderr, "Element doesn't exist: %s\n", strerror(errno));
close(fd);
return -1;
}
// Attempt to look up a value that doesn't exist
lookup_key = 11;
lookup_val = 0;
if (bpf_map_lookup_elem(fd, &lookup_key, &lookup_val) == 0) {
printf("Found value %d for key %d\n", lookup_val, lookup_key);
} else {
fprintf(stderr, "Element doesn't exist: %s\n", strerror(errno));
close(fd);
return -1;
}
close(fd);
return 0;
}
return -1;
}
In this example, we first create a hash map, then insert (10 -> 100) into it. When we call bpf_map_lookup_elem with lookup_key=10, the kernel checks the map for this key. Since it exists, lookup_val is set to 100 and the function returns zero. If the key had not existed, bpf_map_lookup_elem would return -1 and set errno=ENOENT and the output should look like:
Hash map created successfully with fd: 3
Element inserted or updated successfully: key = 10, value = 100
Found value 100 for key 10
Element doesn't exist: No such file or directory
This operation allows you to query the map and read the data it contains without modifying it. If the map is empty or does not contain the requested key, bpf_map_lookup_elem simply fails and sets an appropriate error code.
Kernel-Space code
void *bpf_map_lookup_elem(const void *map, const void *key);
3. Map Delete Element
User-Space code
BPF_MAP_DELETE_ELEM command removes a key-value pair from the map.
The bpf_map_delete_elem function is a libbpf wrapper for BPF_MAP_DELETE_ELEM command and its prototype is : int bpf_map_delete_elem(int fd, const void *key) which takes a map file descriptor and a pointer to the key you want to remove. If the key is found and deleted, it returns zero. If the key does not exist, it returns -1 and sets errno=ENOENT.
Here is an example of deleting a key:
#include <bpf/libbpf.h>
#include <bpf/bpf.h>
#include <errno.h>
#include <unistd.h>
int create_hash_map(void) {
int fd = bpf_map_create(BPF_MAP_TYPE_HASH, "hash_map_example",
sizeof(int), // key_size
sizeof(int), // value_size
1024, // max_entries
NULL); // map_flags
if (fd < 0) {
fprintf(stderr, "Failed to create hash map: %s\n", strerror(errno));
}
return fd;
}
int main() {
int fd = create_hash_map();
if (fd >= 0) {
printf("Hash map created successfully with fd: %d\n", fd);
// Insert a key-value pair (20 -> 250)
int key = 20;
int value = 250;
if (bpf_map_update_elem(fd, &key, &value, BPF_ANY) == 0) {
printf("Element inserted or updated successfully: key = %d, value = %ld\n", key, value);
} else {
fprintf(stderr, "Failed to insert or update element: %s\n", strerror(errno));
close(fd);
return -1;
}
// Now delete the key-value pair for key=20
if (bpf_map_delete_elem(fd, &key) == 0) {
printf("Key %d deleted successfully\n", key);
} else {
fprintf(stderr, "Failed to delete element: %s\n", strerror(errno));
close(fd);
return 1;
}
// Confirm that the key no longer exists
int lookup_val;
if (bpf_map_lookup_elem(fd, &key, &lookup_val) == 0) {
printf("Unexpectedly found key %d after deletion, value=%d\n", key, lookup_val);
} else {
if (errno == ENOENT) {
printf("Confirmed that key %d no longer exists\n", key);
} else {
printf("Element still exists\n");
}
}
close(fd);
return 0;
}
return -1;
}
After inserting (20 -> 250) into the map, we call bpf_map_delete_elem to remove it. The call succeeds, returning zero. A subsequent lookup for key=20 fails with ENOENT, confirming that the entry has been removed and the output:
Hash map created successfully with fd: 3
Element inserted or updated successfully: key = 20, value = 250
Key 20 deleted successfully
Confirmed that key 20 no longer exists
If you call bpf_map_delete_elem for a key that does not exist, the operation simply returns an error and sets errno=ENOENT, indicating that there was nothing to delete.
Kernel-Space code
int bpf_map_delete_elem(void *map, const void *key);
4. Map Lookup and Delete Element
User-Space code
BPF_MAP_LOOKUP_AND_DELETE_ELEM command retrieves the value associated with the given key, just like BPF_MAP_LOOKUP_ELEM command, but it also removes the key-value pair from the map in a single operation The bpf_map_lookup_and_delete_elem function is a libbpf wrapper for BPF_MAP_LOOKUP_AND_DELETE_ELEM command and its prototype is: int bpf_map_lookup_and_delete_elem(int fd, const void *key, void *value) . If the key exists, the function returns zero, copies the value to the user-provided buffer, and deletes that entry from the map. If the key is not found, it returns -1 and sets errno=ENOENT. This operation is particularly useful for scenarios where you want to consume entries from a map, such as implementing a queue or stack-like structure, or simply ensuring that once you retrieve a value, it is removed without requiring a separate delete call.
First, consider inserting a key-value pair and then looking it up and deleting it at the same time:
#include <bpf/libbpf.h>
#include <bpf/bpf.h>
#include <errno.h>
#include <unistd.h>
int create_hash_map(void) {
int fd = bpf_map_create(BPF_MAP_TYPE_HASH, "hash_map_example",
sizeof(int), // key_size
sizeof(int), // value_size
1024, // max_entries
NULL); // map_flags
if (fd < 0) {
fprintf(stderr, "Failed to create hash map: %s\n", strerror(errno));
}
return fd;
}
int main() {
int fd = create_hash_map();
if (fd >= 0) {
printf("Hash map created successfully with fd: %d\n", fd);
// Insert a key-value pair (10 -> 100)
int key = 10;
int value = 100;
if (bpf_map_update_elem(fd, &key, &value, BPF_ANY) == 0) {
printf("Element inserted or updated successfully: key = %d, value = %ld\n", key, value);
} else {
fprintf(stderr, "Failed to insert or update element: %s\n", strerror(errno));
close(fd);
return -1;
}
// Now perform lookup-and-delete
int lookup_val;
if (bpf_map_lookup_and_delete_elem(fd, &key, &lookup_val) == 0) {
printf("Lookup and delete succeeded, value=%d\n", lookup_val);
} else {
fprintf(stderr, "Failed to insert or update element: %s\n", strerror(errno));
close(fd);
return 1;
}
// Verify that the key is no longer in the map
int verify_val;
if (bpf_map_lookup_elem(fd, &key, &verify_val) == 0) {
printf("Unexpectedly found key %d after deletion\n", key);
} else if (errno == ENOENT) {
printf("Confirmed that key %d no longer exists\n", key);
} else {
printf("Element still exists\n");
}
close(fd);
return 0;
}
return -1;
}
The previous example inserts (10 -> 100) into a hash map, then the program calls bpf_map_lookup_and_delete_elem for key=10. The operation returns the value 100 and removes the entry from the map at the same time. A subsequent lookup confirms the key is gone. The output is similar to this:
Hash map created successfully with fd: 3
Element inserted or updated successfully: key = 10, value = 100
Lookup and delete succeeded, value=100
Confirmed that key 10 no longer exists
Kernel-Space code
void *bpf_map_lookup_and_delete_elem(const void *map, const void *key);
5. Get Next Key
User-Space code
BPF_MAP_GET_NEXT_KEY command iterates through the keys in a map. If you pass a specific key, the function returns the next key in the map, or sets errno=ENOENT if there is no next key. If you call it with a non-existing key or a NULL pointer (in some usages), it can return the first key in the map. This allows you to iterate over all keys one by one, even if you do not know them in advance.. The bpf_map_get_next_key function is a libbpf wrapper for BPF_MAP_GET_NEXT_KEY command and its prototype is: int bpf_map_get_next_key(int fd, const void *key, void *next_key).
It’s important to note that the order of keys returned by bpf_map_get_next_key is not guaranteed to be the same as the typical ordering found in most iterators in other programming languages. The keys in eBPF maps are stored in an internal, arbitrary order determined by the kernel. Therefore, the order in which keys are returned when iterating is not necessarily sequential (e.g., ascending or based on insertion order). If you need a specific order, such as sorted keys, you will need to handle that ordering manually in your application.
Here’s how you might iterate over all keys:
#include <bpf/libbpf.h>
#include <bpf/bpf.h>
#include <errno.h>
#include <unistd.h>
int create_hash_map(void) {
int fd = bpf_map_create(BPF_MAP_TYPE_HASH, "hash_map_example",
sizeof(int), // key_size
sizeof(int), // value_size
1024, // max_entries
NULL); // map_flags
if (fd < 0) {
fprintf(stderr, "Failed to create hash map: %s\n", strerror(errno));
}
return fd;
}
int main() {
int fd = create_hash_map();
if (fd >= 0) {
printf("Hash map created successfully with fd: %d\n", fd);
// Insert multiple keys for demonstration
int keys[] = {10, 20, 30};
int values[] = {100, 200, 300};
for (int i = 0; i < 3; i++) {
if (bpf_map_update_elem(fd, &keys[i], &values[i], BPF_ANY) == 0) {
printf("Element inserted or updated successfully: key = %d, value = %ld\n", keys[i], values[i]);
} else {
fprintf(stderr, "Failed to insert or update element: %s\n", strerror(errno));
close(fd);
return -1;
}
}
// We'll start by using a key that doesn't exist (e.g., start_key=-1) to get the first key.
int start_key = -1;
int next_key;
if (bpf_map_get_next_key(fd, &start_key, &next_key) == 0) {
printf("Next key: %d\n", next_key);
} else {
fprintf(stderr, "Error getting next key: %s\n", strerror(errno));
close(fd);
return -1;
}
// Move to the next key
start_key = next_key;
if (bpf_map_get_next_key(fd, &start_key, &next_key) == 0) {
printf("Next key: %d\n", next_key);
} else {
fprintf(stderr, "Error getting next key: %s\n", strerror(errno));
close(fd);
return -1;
}
// Move to the next key
start_key = next_key;
if (bpf_map_get_next_key(fd, &start_key, &next_key) == 0) {
printf("Next key: %d\n", next_key);
} else {
fprintf(stderr, "Error getting next key: %s\n", strerror(errno));
close(fd);
return -1;
}
close(fd);
return 0;
}
return -1;
}
In this example, we insert (10->100), (20->200), (30->300) into the map. We start iteration with a key (-1) that we know does not exist. The kernel returns the first key in ascending order. We then print each key-value pair and call bpf_map_get_next_key to advance to the next key. When ENOENT is returned, we know we have reached the end of the map. This process allows scanning the map’s contents without knowing the keys upfront.
Kernel-Space code
int bpf_map_get_next_key(const void *map, const void *key, void *next_key);
6. Map Lookup Batch
User-Space code
BPF_MAP_LOOKUP_BATCH command fetches multiple elements from the map in a single call. Instead of calling BPF_MAP_LOOKUP_ELEM command repeatedly for each key, you can use this operation to retrieve several keys and their associated values at once. This improves performance when dealing with large maps or when you need to read multiple entries efficiently.
The bpf_map_lookup_batch function is a libbpf wrapper for BPF_MAP_LOOKUP_BATCH command and it uses two special parameters: in_batch and out_batch, which help maintain the state between successive batch lookups. You begin by passing a NULL in_batch to start from the first set of entries. The kernel then returns a batch of (key, value) pairs and sets out_batch to indicate where to resume from. On subsequent calls, you pass out_batch as in_batch to continue retrieving the next batch of entries until all entries have been retrieved. This method is particularly efficient for maps with a large number of entries, as it reduces the overhead of making individual lookups for each element, thus speeding up the retrieval process.
The helper function prototype is
int bpf_map_lookup_batch(int fd, void *in_batch, void *out_batch, void *keys,
void *values, __u32 *count, const struct bpf_map_batch_opts *opts);
- fd: The file descriptor for the eBPF map you’re querying.
- in_batch: The address of the first element in the batch to read. You pass
NULLfor the first call to start from the beginning of the map. On subsequent calls, you pass the address ofout_batchto continue from the last retrieved entry. - out_batch: This is an output parameter that the kernel sets to the position of the last element retrieved. It indicates where to resume for the next batch lookup.
- keys: A pointer to a buffer where the kernel will store the keys retrieved.
- values: A pointer to a buffer where the kernel will store the corresponding values for the retrieved keys.
- count: On input, this specifies the number of elements you want to retrieve in the batch. On output, it will contain the actual number of elements retrieved.
- opts: An optional parameter for additional configuration (can be
NULLif not needed).
Let’s go through an example:
#include <bpf/libbpf.h>
#include <bpf/bpf.h>
#include <errno.h>
#include <unistd.h>
int create_hash_map(void) {
int fd = bpf_map_create(BPF_MAP_TYPE_HASH, "hash_map_example",
sizeof(int), // key_size
sizeof(int), // value_size
1024, // max_entries
NULL); // map_flags
if (fd < 0) {
fprintf(stderr, "Failed to create hash map: %s\n", strerror(errno));
}
return fd;
}
int main() {
int fd = create_hash_map();
if (fd >= 0) {
printf("Hash map created successfully with fd: %d\n", fd);
// Insert several entries for demonstration
int keys[] = {10, 20, 30, 40, 50, 60, 70, 80, 90};
int values[] = {100, 200, 300, 400, 500, 600, 700, 800, 900};
for (int i = 0; i < 9; i++) {
if (bpf_map_update_elem(fd, &keys[i], &values[i], BPF_ANY) == 0) {
printf("Element inserted or updated successfully: key = %d, value = %ld\n", keys[i], values[i]);
} else {
fprintf(stderr, "Failed to insert or update element: %s\n", strerror(errno));
close(fd);
return -1;
}
}
// Prepare to batch lookup
int batch_keys[1024];
int batch_vals[1024];
__u32 batch_count = 2; // Number of elements to retrieve in one go
__u32 *in_batch = NULL; // Start from the beginning
__u32 out_batch;
int err;
do {
err = bpf_map_lookup_batch(fd, in_batch, &out_batch,
batch_keys, batch_vals, &batch_count, NULL);
if (err == 0) {
for (unsigned i = 0; i < batch_count; i++) {
printf("Batch element: key=%d, value=%d\n", batch_keys[i], batch_vals[i]);
}
// Prepare for next batch: continue from last position
in_batch = &out_batch; // Set `in_batch` to the position of the last element
} else if (errno != ENOENT) {
// An error other than ENOENT means a failure occurred.
fprintf(stderr, "Lookup batch failed: %s\n", strerror(errno));
break;
}
} while (err == 0);
close(fd);
return 0;
}
return -1;
}
The previous example first inserts nine key-value pairs into a hash map. Then, it calls bpf_map_lookup_batch repeatedly to retrieve elements in batches, until ENOENT indicates that all entries have been retrieved. Each successful batch call prints out a subset of the map entries. Since there are only nine entries, you will likely retrieve them in one or two batches, depending on the batch size. However, this method scales well for larger maps.
The batch size is set to 2 (in batch_count), meaning the program will attempt to retrieve two entries in each call to bpf_map_lookup_batch. If the map does not contain enough entries to fill the entire batch, batch_count is adjusted to reflect how many entries were actually returned. When bpf_map_lookup_batch eventually returns ENOENT, it indicates that all elements have been retrieved. The output could be like:
Hash map created successfully with fd: 3
Element inserted or updated successfully: key = 10, value = 100
Element inserted or updated successfully: key = 20, value = 200
Element inserted or updated successfully: key = 30, value = 300
Element inserted or updated successfully: key = 40, value = 400
Element inserted or updated successfully: key = 50, value = 500
Element inserted or updated successfully: key = 60, value = 600
Element inserted or updated successfully: key = 70, value = 700
Element inserted or updated successfully: key = 80, value = 800
Element inserted or updated successfully: key = 90, value = 900
Batch element: key=30, value=300
Batch element: key=20, value=400
Batch element: key=80, value=800
Batch element: key=70, value=900
Batch element: key=60, value=600
Batch element: key=40, value=700
Batch element: key=50, value=500
Batch element: key=90, value=600
Kernel-Space code
There is no helper function for such operation.
7. Map Update Batch
User-Space code
BPF_MAP_UPDATE_BATCH command allows you to insert or update multiple keys and values in a single call. Similar to BPF_MAP_LOOKUP_BATCH command, this can significantly reduce overhead compared to performing multiple BPF_MAP_LOOKUP_ELEM calls in a loop. The bpf_map_update_batch function is a libbpf wrapper for BPF_MAP_UPDATE_BATCH command and its prototype is:
int bpf_map_update_batch(int fd, const void *keys, const void *values, __u32 *count,
const struct bpf_map_batch_opts *opts)
You provide arrays of keys and values, along with a count, and bpf_map_update_batch attempts to insert or update all of them at once. Just like bpf_map_update_elem, you can specify flags such as BPF_ANY, BPF_NOEXIST, or BPF_EXIST to control insertion and update behavior as we mentioned earlier.
#include <bpf/libbpf.h>
#include <bpf/bpf.h>
#include <errno.h>
#include <unistd.h>
int create_hash_map(void) {
int fd = bpf_map_create(BPF_MAP_TYPE_HASH, "hash_map_example",
sizeof(int), // key_size
sizeof(int), // value_size
1024, // max_entries
NULL); // map_flags
if (fd < 0) {
fprintf(stderr, "Failed to create hash map: %s\n", strerror(errno));
}
return fd;
}
int main() {
int fd = create_hash_map();
if (fd >= 0) {
printf("Hash map created successfully with fd: %d\n", fd);
// Prepare arrays of keys and values
int bulk_keys[3] = {40, 50, 60};
int bulk_values[3] = {400, 500, 600};
__u32 bulk_count = 3;
// Update multiple entries in one go
if (bpf_map_update_batch(fd, bulk_keys, bulk_values, &bulk_count, BPF_ANY) == 0) {
printf("Batch update succeeded\n");
} else {
fprintf(stderr, "Batch update failed: %s\n", strerror(errno));
close(fd);
return 1;
}
// Verify that the entries are now in the map
for (int i = 0; i < 3; i++) {
int val;
if (bpf_map_lookup_elem(fd, &bulk_keys[i], &val) == 0) {
printf("Key=%d, Value=%d\n", bulk_keys[i], val);
} else {
fprintf(stderr, "Key=%d not found after batch update: %s\n", bulk_keys[i], strerror(errno));
}
}
close(fd);
return 0;
}
return -1;
}
This example inserts (40->400), (50->500), and (60->600) into the map in a single bpf_map_update_batch call. Afterward, we verify that all three keys were successfully inserted. If any error occurs (e.g., map is full), some keys might be updated before the error is returned. You can inspect errno and bulk_count for partial success handling.
Hash map created successfully with fd: 3
Batch update succeeded
Key=40, Value=400
Key=50, Value=600
Key=60, Value=50
This bulk approach is especially beneficial when populating maps with a large set of keys during initialization or when updating multiple entries at once.
Kernel-Space code
There is no helper function for such operation.
8. Map Delete Batch
User-Space code
BPF_MAP_DELETE_BATCH command removes multiple entries from the map in a single call, much like BPF_MAP_DELETE_ELEM does for individual keys. You supply arrays of keys along with a count, and the kernel attempts to delete all those keys at once. This operation is more efficient than deleting entries one by one, especially for large sets of keys. The bpf_map_delete_batch function is a libbpf wrapper for BPF_MAP_DELETE_BATCH command and its prototype is:
int bpf_map_delete_batch(int fd, const void *keys, __u32 *count,
const struct bpf_map_batch_opts *opts)
The fd parameter is the file descriptor for the map, and keys is a pointer to an array of keys to delete. The count parameter specifies the number of keys to delete and is updated with the actual number of deletions. The opts parameter is optional and allows additional configuration (usually passed as NULL). The function returns 0 if successful, or a negative error code if an error occurs, with errno providing more details.
For example, if your map currently contains (10->100), (20->200), and (30->300), and you want to remove (10, 20, 30) all at once:
#include <bpf/libbpf.h>
#include <bpf/bpf.h>
#include <errno.h>
#include <unistd.h>
int create_hash_map(void) {
int fd = bpf_map_create(BPF_MAP_TYPE_HASH, "hash_map_example",
sizeof(int), // key_size
sizeof(int), // value_size
1024, // max_entries
NULL); // map_flags
if (fd < 0) {
fprintf(stderr, "Failed to create hash map: %s\n", strerror(errno));
}
return fd;
}
int main() {
int fd = create_hash_map();
if (fd >= 0) {
printf("Hash map created successfully with fd: %d\n", fd);
// Prepare arrays of keys and values
int bulk_keys[3] = {40, 50, 60};
int bulk_values[3] = {400, 500, 600};
__u32 bulk_count = 3;
// Update multiple entries in one go
if (bpf_map_update_batch(fd, bulk_keys, bulk_values, &bulk_count, BPF_ANY) == 0) {
printf("Batch update succeeded\n");
} else {
fprintf(stderr, "Batch update failed: %s\n", strerror(errno));
close(fd);
return 1;
}
// Now batch-delete them
__u32 delete_count = 3;
if (bpf_map_delete_batch(fd, bulk_keys, &delete_count, NULL) == 0) {
printf("Batch delete succeeded\n");
} else {
fprintf(stderr, "Batch delete failed: %s\n", strerror(errno));
close(fd);
return 1;
}
// Confirm deletion
for (int i = 0; i < 3; i++) {
int val;
if (bpf_map_lookup_elem(fd, &bulk_keys[i], &val) == 0) {
printf("Unexpectedly found key %d after batch deletion\n", bulk_keys[i]);
} else if (errno == ENOENT) {
printf("Confirmed key %d is removed\n", bulk_keys[i]);
} else {
fprintf(stderr, "Lookup error: %s\n", strerror(errno));
}
}
close(fd);
return 0;
}
return -1;
}
If successful, all three keys are removed. If an error occurs (for example, if one key does not exist), delete_count may be set to the number of successfully deleted keys before the error. In that case, you can handle partial success accordingly.
This approach is ideal when you need to clear out a subset of keys without performing multiple individual deletions.
Kernel-Space code
There is no helper function for such operation.
9. Map Freeze
User-Space code
BPF_MAP_FREEZE command converts the specified map into a read-only state. After freezing a map, no further updates or deletions can be performed using bpf() syscalls, although eBPF programs themselves can still read and, in some cases, modify certain fields if allowed by the map type. Freezing is useful when you have finished constructing or populating a map and want to ensure its contents remain stable.
The bpf_map_freeze function is a libbpf wrapper for BPF_MAP_FREEZE command and its prototype is:
int bpf_map_freeze(int fd)
To freeze a map:
#include <bpf/libbpf.h>
#include <bpf/bpf.h>
#include <errno.h>
#include <unistd.h>
int create_hash_map(void) {
int fd = bpf_map_create(BPF_MAP_TYPE_HASH, "hash_map_example",
sizeof(int), // key_size
sizeof(int), // value_size
1024, // max_entries
NULL); // map_flags
if (fd < 0) {
fprintf(stderr, "Failed to create hash map: %s\n", strerror(errno));
}
return fd;
}
int main() {
int fd = create_hash_map();
if (fd >= 0) {
printf("Hash map created successfully with fd: %d\n", fd);
// Insert an entry (10->100)
int key = 10;
int value = 100;
if (bpf_map_update_elem(fd, &key, &value, BPF_ANY) == 0) {
printf("Element inserted or updated successfully: key = %d, value = %ld\n", key, value);
} else {
fprintf(stderr, "Failed to insert or update element: %s\n", strerror(errno));
return -1;
}
// Freeze the map to prevent further updates
if (bpf_map_freeze(fd) == 0) {
printf("Map is now frozen and read-only\n");
} else {
perror("bpf_map_freeze");
return 1;
}
// Attempting to update after freezing should fail
int new_val = 200;
if (bpf_map_update_elem(fd, &key, &new_val, BPF_ANY) != 0) {
if (errno == EPERM) {
printf("Update failed, map is frozen\n");
} else {
perror("bpf_map_update_elem");
}
} else {
printf("Unexpected success, map should have been frozen\n");
}
close(fd);
return 0;
}
return -1;
}
After this call, attempts to update or delete elements through bpf_map_update_elem or bpf_map_delete_elem will fail with EPERM. This ensures that user-space cannot inadvertently modify the map’s contents, making it a suitable mechanism for finalizing configuration or ensuring data integrity.
Hash map created successfully with fd: 3
Element inserted or updated successfully: key = 10, value = 100
Map is now frozen and read-only
Update failed, map is frozen
Kernel-Space code
There is no helper function for such operation.
10. Object Pin
User-Space code
BPF_OBJ_PIN command allows you to pin a map (or other eBPF objects like programs) to a location in the eBPF filesystem (/sys/fs/bpf by default). Pinning makes the map accessible to other processes after the original process that created it terminates, thereby extending the map’s lifetime beyond that of a single application.
The bpf_obj_pin_opts function is a libbpf wrapper for BPF_OBJ_PIN command and its prototype is:
int bpf_obj_pin_opts(int fd, const char *pathname, const struct bpf_obj_pin_opts *opts)
Note
The pathname argument must not contain a dot (".")./sys/fs/bpf/my_map:
#include <bpf/libbpf.h>
#include <bpf/bpf.h>
#include <errno.h>
#include <unistd.h>
int create_hash_map(void) {
int fd = bpf_map_create(BPF_MAP_TYPE_HASH, "hash_map_example",
sizeof(int), // key_size
sizeof(int), // value_size
1024, // max_entries
NULL); // map_flags
if (fd < 0) {
fprintf(stderr, "Failed to create hash map: %s\n", strerror(errno));
}
return fd;
}
int main() {
int fd = create_hash_map();
if (fd >= 0) {
printf("Hash map created successfully with fd: %d\n", fd);
// Prepare arrays of keys and values
int bulk_keys[3] = {40, 50, 60};
int bulk_values[3] = {400, 500, 600};
__u32 bulk_count = 3;
// Update multiple entries in one go
if (bpf_map_update_batch(fd, bulk_keys, bulk_values, &bulk_count, BPF_ANY) == 0) {
printf("Batch update succeeded\n");
} else {
fprintf(stderr, "Batch update failed: %s\n", strerror(errno));
return 1;
}
// Pin the map to the BPF filesystem
const char *pin_path = "/sys/fs/bpf/my_map";
if (bpf_obj_pin(fd, pin_path) == 0) {
printf("Map pinned at %s\n", pin_path);
} else {
perror("bpf_obj_pin");
return 1;
}
close(fd);
return 0;
}
return -1;
}
Here, we create a map, insert (20->200), and pin it to /sys/fs/bpf/my_map. After pinning, we can safely close the file descriptor without losing the map. The map remains accessible at the pin path, allowing other processes to open it later.
Note
Closingfd in the current process does not destroy the map. It persists at /sys/fs/bpf/my_map until unlinked or until the system reboots.
Kernel-Space code
There is no helper function for such operation.
11. Object Get
User-Space code
BPF_OBJ_GET command retrieves a file descriptor for a previously pinned map, allowing a separate process to access and interact with that map. This facilitates sharing eBPF maps between multiple processes or restoring access to the map after the original creating process has exited.
The bpf_obj_get function is a libbpf wrapper for BPF_OBJ_GET command and its prototype is:
int bpf_obj_get(const char *pathname)
By calling bpf_obj_get(path), you open a reference to the pinned map from the filesystem path. Let’s get the previous map /sys/fs/bpf/my_map
#include <bpf/libbpf.h>
#include <bpf/bpf.h>
#include <errno.h>
#include <unistd.h>
int main() {
const char *pin_path = "/sys/fs/bpf/my_map";
// Open the pinned map
int pinned_map_fd = bpf_obj_get(pin_path);
if (pinned_map_fd < 0) {
perror("bpf_obj_get");
return 1;
}
printf("Opened pinned map from %s\n", pin_path);
// Verify the map's content
int key = 50;
int val = 0;
if (bpf_map_lookup_elem(pinned_map_fd, &key, &val) == 0) {
printf("Retrieved value %d for key %d from pinned map\n", val, key);
} else {
perror("bpf_map_lookup_elem");
}
close(pinned_map_fd);
return 0;
}
This program assumes that a map was previously pinned at /sys/fs/bpf/my_map. Calling bpf_obj_get opens a file descriptor to that map. We then retrieve (50->500) that was inserted in the previous example, confirming that the pinned map persists across processes.
Opened pinned map from /sys/fs/bpf/my_map
Retrieved value 500 for key 50 from pinned map
If successful, pinned_map_fd can be used just like any other map file descriptor. This is essential for long-running services or tools that need persistent state maintained across restarts, or for sharing data structures between different components of a system.
Kernel-Space code
There is no helper function for such operation.
I know it can be challenging to wrap your head around the differences between eBPF user-space code and kernel-space eBPF programs. Bear with me—soon we’ll see eBPF programs in action, including maps and map operations, and everything will start to click!
4 - eBPF Program Types
Understanding eBPF’s capabilities is a thorough grasp of eBPF program types. Each eBPF program type represents a different interface or hook point in the kernel’s workflow. By selecting a particular program type when loading an eBPF program, the user defines the program’s environment: which kernel functions or events it can attach to, what kinds of data structures it can access, and which kernel helper functions can be called. Understanding these program types is crucial, because eBPF is not a one-size-fits-all technology. Instead, it offers a toolkit of specialized hooks, each tailored to a specific domain within the kernel.
In the Linux kernel source code, eBPF program types are listed in the UAPI header file include/uapi/linux/bpf.h. This header file provides an enumeration called enum bpf_prog_type that declares all the recognized program types.
enum bpf_prog_type {
BPF_PROG_TYPE_UNSPEC,
BPF_PROG_TYPE_SOCKET_FILTER,
BPF_PROG_TYPE_KPROBE,
BPF_PROG_TYPE_SCHED_CLS,
BPF_PROG_TYPE_SCHED_ACT,
BPF_PROG_TYPE_TRACEPOINT,
BPF_PROG_TYPE_XDP,
BPF_PROG_TYPE_PERF_EVENT,
BPF_PROG_TYPE_CGROUP_SKB,
BPF_PROG_TYPE_CGROUP_SOCK,
BPF_PROG_TYPE_LWT_IN,
BPF_PROG_TYPE_LWT_OUT,
BPF_PROG_TYPE_LWT_XMIT,
BPF_PROG_TYPE_SOCK_OPS,
BPF_PROG_TYPE_SK_SKB,
BPF_PROG_TYPE_CGROUP_DEVICE,
BPF_PROG_TYPE_SK_MSG,
BPF_PROG_TYPE_RAW_TRACEPOINT,
BPF_PROG_TYPE_CGROUP_SOCK_ADDR,
BPF_PROG_TYPE_LWT_SEG6LOCAL,
BPF_PROG_TYPE_LIRC_MODE2,
BPF_PROG_TYPE_SK_REUSEPORT,
BPF_PROG_TYPE_FLOW_DISSECTOR,
BPF_PROG_TYPE_CGROUP_SYSCTL,
BPF_PROG_TYPE_RAW_TRACEPOINT_WRITABLE,
BPF_PROG_TYPE_CGROUP_SOCKOPT,
BPF_PROG_TYPE_TRACING,
BPF_PROG_TYPE_STRUCT_OPS,
BPF_PROG_TYPE_EXT,
BPF_PROG_TYPE_LSM,
BPF_PROG_TYPE_SK_LOOKUP,
BPF_PROG_TYPE_SYSCALL, /* a program that can execute syscalls */
BPF_PROG_TYPE_NETFILTER,
__MAX_BPF_PROG_TYPE
};
When the user invokes the bpf() system call with the BPF_PROG_LOAD command, they specify one of these types. The kernel’s eBPF subsystem, including the verifier and the JIT compiler, then interprets the program according to the type requested. This choice determines what the program can do and which kernel functions it can safely interact with.
For example, when an operator writes an eBPF program that inspects network packets at a very early stage, they will choose the XDP (eXpress Data Path) program type. When performing dynamic tracing of kernel functions, they might use a kprobe or tracepoint program type. For building network firewalls or address-based restrictions at the cgroup level, they might opt for cgroup-related program types. Thus, each program type stands at the intersection of kernel events, context definitions, and allowed helper functions. This allows eBPF to cover a wide range of kernel instrumentation and customization scenarios while maintaining a strong safety and verification model.
It is also important to understand that each eBPF program type has a well-defined context structure and is closely tied to specific kernel functions or subsystems. For example, a socket filter program interacts with the socket layer, and the kernel provides a context structure (such as struct __sk_buff) that the eBPF program can read and manipulate. Similarly, a kprobe program type interacts with kernel functions specified by the user, and the kernel exposes function arguments through a context representing CPU registers. While kernel code is typically written in C, with some assembly and domain-specific macros, the eBPF environment operates as a restricted virtual machine inside the kernel, ensuring safety through static verification.
These eBPF programs can be attached to different types of events in the kernel, which defines where and when the program is executed. While many program types have a default attachment point deduced from the program type itself, some can attach to multiple locations in the kernel. In these cases, the attachment type must be explicitly specified to ensure the program is hooked to the correct event, such as a specific tracepoint. This distinction between program types and attachment types allows for greater flexibility and precision in how eBPF programs interact with kernel functions and events.
The following table, sourced from the kernel manual for libbpf, outlines the various eBPF program types and ELF section names. For more details, you can refer to the official documentation.

Sleepable eBPF programs are programs that are allowed to sleep during execution, marked by the BPF_F_SLEEPABLE flag. These programs are typically limited to specific types, such as security or tracing programs, while most other eBPF programs cannot sleep due to performance and safety reasons.
Before diving into specific program types, it is worth noting what a kernel function means in this context. The Linux kernel exports a wide range of functions, some internal and some available as hooks or tracepoints. Traditional kernel development would require a developer to write a loadable kernel module (LKM) and link it against these kernel functions, potentially breaking stability. With eBPF, however, the developer attaches to these kernel functions or kernel events indirectly, through stable, well-defined interfaces like kprobes, tracepoints, or security hooks. The kernel function from the perspective of an eBPF developer is usually a point in the kernel’s execution flow where they can gain insight or exert minimal influence.
eBPF provides indirect access through safe, monitored gateways rather than direct manipulation of kernel symbols, ensuring that even when instrumentation is performed at runtime, kernel stability and security remain intact. We have the full list of eBPF program types here. Now, let’s dive into the ones used most often.
BPF_PROG_TYPE_SOCKET_FILTER
One of the earliest and most foundational uses of eBPF is the socket filter program type. Historically, classic BPF (cBPF) was introduced for socket filtering, allowing a user program to attach a small filtering program to a raw socket. With eBPF, the socket filter functionality is extended to a more versatile and powerful environment.
A SOCKET_FILTER type program executes whenever a packet arrives at the socket it is attached to. Its context is a struct __sk_buff, a data structure defined in the kernel’s networking subsystem. This structure represents the packet’s metadata: its length, protocol, and pointers to the packet’s head and tail within the kernel’s networking stack. When the socket filter program runs, it can inspect packet headers, check IP addresses, transport layer ports, or even packet payload data.
In the kernel source code, the logic that associates a BPF program with a socket can be found in networking-related files, such as net/core/filter.c. The kernel functions involved in socket receive paths ultimately invoke the attached eBPF program. While the developer never directly calls these kernel functions from user space, understanding that the bpf() syscall with BPF_PROG_LOAD installs a filter that the kernel will call on packet reception helps conceptualize how kernel and eBPF code interact.
BPF_PROG_TYPE_KPROBE
Kprobes are a kernel mechanism that allows the insertion of breakpoints into running kernel code for debugging and tracing. A KPROBE type eBPF program leverages this mechanism to execute whenever a specified kernel function is called. The corresponding kernel functions providing this capability are found in kernel/kprobes.c and related source files. Although these are low-level kernel features, from a user’s perspective, attaching a kprobe-based eBPF program is a matter of specifying the function name and loading the program with the correct type and section name (such as SEC("kprobe/…")).
When the kernel hits the probed function, it automatically invokes the attached eBPF program. Inside the eBPF program, the context may provide access to the registers and arguments of that kernel function call. Unlike a static interface, a kprobe can be attached to almost any kernel function symbol, enabling dynamic and powerful instrumentation. This is especially useful for performance analysis, debugging kernel behavior, or collecting usage statistics for particular kernel subsystems.
For instance, consider a scenario where the user wants to monitor file opens in the kernel by probing the do_sys_open function. By attaching a kprobe eBPF program to this function, it becomes possible to log every file open event, record the filename argument, and store it in eBPF map keyed by process ID. In user space, an operator can retrieve this data to understand which processes are touching which files over time. Previously, achieving this level of detail would require recompiling the kernel with special instrumentation or using heavyweight tools. With eBPF kprobes, it is dynamic, safe, and efficient.
BPF_PROG_TYPE_TRACEPOINT
While kprobes attach to arbitrary kernel functions, tracepoints represent a set of pre-defined static instrumentation points placed throughout the kernel. Tracepoints are designed by kernel developers and maintainers to provide stable, versioned interfaces for tracing particular events. They might mark the start or end of a scheduling operation, the completion of I/O operations, or the invocation of certain subsystems.
A TRACEPOINT type eBPF program, when loaded and attached to a specific tracepoint event, is guaranteed a stable and well-defined context structure. For example, a tracepoint may provide the PID of the task involved in a scheduling event or the device number in a block I/O event. This stability makes tracepoints well-suited for long-term monitoring and performance analysis tools, because they are less prone to changes as the kernel evolves than raw function symbols.
A compelling application might be monitoring scheduling events to understand how often a particular process is context-switched. By attaching an eBPF tracepoint program to the sched_process_exec tracepoint, the user can record every time a new process executes, linking PIDs to command lines, and gathering metrics about system activity. This data can be streamed to user space and visualized or stored for later analysis. Because tracepoints are standardized, the same eBPF program code is likely to work across multiple kernel releases, enhancing maintainability and portability.
BPF_PROG_TYPE_XDP
XDP, short for eXpress Data Path, is a revolutionary approach to packet processing. XDP programs run extremely early in the packet’s journey, often at the device driver level, before the kernel’s networking stack processes the packet. This positioning allows XDP programs to achieve exceptionally high performance, making them an attractive option for load balancing, denial-of-service protection, and advanced packet filtering.
In the kernel source code, XDP integration can be found in network driver code and in net/core/dev.c, where the kernel’s receive path logic is implemented. The kernel functions that handle packet arrival invoke the XDP hook, giving the XDP eBPF program direct access to the packet’s raw buffer and metadata. The eBPF code can then decide to drop, pass, redirect, or modify the packet in place, all with minimal overhead.
Consider a data center environment with a load balancer at the edge. By deploying an XDP eBPF program, the operator can inspect incoming packets and choose which backend server to forward them to, based on dynamic policies stored in maps. If a sudden attack occurs, the same XDP program can recognize malicious patterns and drop unwanted traffic immediately, preventing the kernel’s main networking stack from wasting CPU cycles. This ability to implement custom high-performance networking logic on the fly is one of the reasons XDP is considered a game-changer in Linux networking.
BPF_PROG_TYPE_PERF_EVENT
Linux’s perf subsystem provides powerful performance monitoring capabilities, including counting hardware events (cache misses, branch mispredictions), software events (task migrations, page faults), and custom tracepoints. By attaching an eBPF PERF_EVENT type program, developers can collect and process performance data in real time. The kernel code handling these events lives largely within the kernel/events/ directory, where the perf subsystem is implemented.
A PERF_EVENT type eBPF program can run periodically based on sampling events or be triggered by certain performance conditions. Once triggered, it can record the current instruction pointer, stack trace, or other metrics into eBPF map. User space can then use tools like bpftool or perf itself to retrieve this data and generate flame graphs, histograms, or other visualizations. The benefit of using eBPF here is the flexibility to implement custom logic within the kernel’s perf event callbacks, something that would be impossible or cumbersome without eBPF.
For example, a developer might sample the CPU at a fixed rate to capture instruction pointers and thereby build a statistical profile of the hottest code paths in a production system. With a PERF_EVENT eBPF program, this sampling can be done efficiently and continuously, helping identify performance bottlenecks and guiding optimization efforts without stopping the system or deploying debugging kernels.
BPF_PROG_TYPE_RAW_TRACEPOINT
Raw tracepoints are similar to standard tracepoints, but they give the eBPF program direct access to the raw event data before the kernel applies stable formatting or abstractions. In other words, a RAW_TRACEPOINT program deals with the tracepoint’s underlying arguments and data structures without the stable, versioned interface offered by regular tracepoints. Kernel code related to raw tracepoints can also be found in tracing subsystems, but these are often less documented or guaranteed.
While this makes RAW_TRACEPOINT programs more fragile, it also grants advanced users more flexibility. If a developer needs to instrument a kernel feature that does not have a stable tracepoint or must interpret tracepoint data in a custom way, a raw tracepoint provides that opportunity. As the kernel evolves, a raw tracepoint may require updates in the eBPF program to remain compatible, but for advanced instrumentation tasks, the raw access can be invaluable.
A possible use case is for low-level file system or memory management events that have not been given stable tracepoint formats. By attaching a RAW_TRACEPOINT eBPF program to a kernel event, the user can parse the raw data structures themselves, extracting fields that normal tracepoints would not expose.
BPF_PROG_TYPE_CGROUP_SOCK_ADDR
Cgroup socket address programs integrate eBPF with Linux control groups (cgroups), providing the ability to enforce network policies at a container or service level. When a process inside a particular cgroup attempts to bind or connect a socket, the attached eBPF program runs. This allows administrators to define policies that restrict which IP addresses or ports a cgrouped process may use.
The kernel code that integrates eBPF with cgroups lives in kernel/cgroup and net/core/sock.c, among other places. By setting BPF_PROG_TYPE_CGROUP_SOCK_ADDR, the user signals that the program will be invoked at the socket layer whenever an address operation occurs. In the program, the context provides access to the requested IP and port. The eBPF code can then check these values against a map of allowed destinations and return a decision—permit or deny. This approach is more dynamic and fine-grained than static firewall rules, and it fits seamlessly into containerized environments where cgroups define the boundaries of service-level isolation.
For instance, if an operator wants to ensure that a container running a certain microservice can only connect to a backend database cluster and nowhere else, a cgroup sock address eBPF program can implement this logic. By updating the map of allowed addresses in real time, the operator can adapt policies as the network environment changes, without having to restart the containers or adjust complicated firewall configurations. This helps build more secure, isolated, and manageable service ecosystems.
BPF_PROG_TYPE_FLOW_DISSECTOR
The kernel uses a flow dissector to classify packets into flows for features like packet steering, hashing, and load balancing. By default, this classification might rely on a standard tuple of IP addresses and ports. However, in complex environments, administrators may need custom logic to handle encapsulation protocols, new transport protocols, or proprietary headers.
A FLOW_DISSECTOR type eBPF program allows customization of the kernel’s flow classification logic. Inside the kernel source, flow dissector code can be found in files like net/core/flow_dissector.c. By loading a FLOW_DISSECTOR eBPF program, the user can instruct the kernel how to parse packet headers and extract keys differently than the default code. This can be crucial in environments that rely heavily on tunneling or need specialized hashing strategies.
Imagine a data center that uses a custom tunnel header format for internal traffic. Without eBPF, the kernel’s flow classification might fail to distinguish different flows correctly, leading to poor load balancing and performance. With a FLOW_DISSECTOR eBPF program, the operator can parse these custom headers and properly hash flows across multiple CPUs or network paths.
BPF_PROG_TYPE_RAW_TRACEPOINT_WRITABLE
While most eBPF program types are focused on reading data and making decisions, RAW_TRACEPOINT_WRITABLE introduces a scenario where the program can potentially modify certain event data. This is advanced feature, allowing the developer to experiment with kernel events and, in some cases, adjust parameters or fields as they are passed to kernel subsystems. The relevant code is tightly integrated with the tracing subsystem, and due to the risk and complexity involved, the kernel imposes strict verification rules to ensure this does not compromise stability.
A RAW_TRACEPOINT_WRITABLE eBPF program might be used in highly specialized debugging scenarios, where a developer needs to simulate unusual conditions or override fields to test kernel behavior. Because this feature is neither common nor intended for typical production use, it is rarely encountered by average eBPF practitioners.
BPF_PROG_TYPE_LSM
Linux Security Modules (LSMs) are a mechanism by which security frameworks like SELinux or AppArmor integrate with the kernel to enforce access control policies. With eBPF’s introduction, it became possible to write LSM policies dynamically. By choosing BPF_PROG_TYPE_LSM, the developer can attach eBPF programs to LSM hooks, allowing them to implement custom security policies without patching or rebuilding the kernel.
The kernel’s security subsystem defines a variety of hooks for filesystem operations, network accesses, and system call checks. Attaching an LSM eBPF program means that whenever a protected operation occurs—such as opening a file, creating a socket, or executing a binary—the eBPF code runs to decide whether to permit or deny the action. This approach blends eBPF’s runtime adaptability with the kernel’s security framework.
A straightforward example might be a scenario where a particular container should never read from a certain sensitive file or directory. By attaching an LSM eBPF program to the relevant file-open hook, the system can block any open attempts that violate this policy. If conditions change (say the file’s allowed access pattern must be updated), the administrator can simply update the eBPF map or reload the LSM program. This transforms what was once a static policy configuration into a dynamic, code-driven security model.
BPF_PROG_TYPE_NETFILTER
Netfilter is the framework underlying most Linux firewall and NAT functionalities. Historically configured via iptables or nftables, Netfilter provides hooks at various stages of packet traversal within the kernel’s networking stack. By writing a NETFILTER type eBPF program, the developer can plug into these hooks and implement dynamic, programmable firewall rules and packet handling logic.
In kernel source code, netfilter hooks are spread across the net/ipv4, net/ipv6, and net/netfilter directories. Attaching an eBPF program at these hooks allows rewriting packets, filtering them according to complex criteria, or even performing custom NAT logic. Unlike static Netfilter rules, which rely on limited matching conditions and actions, an eBPF NETFILTER program can execute arbitrary logic, consult eBPF maps for dynamically updated policies, and integrate seamlessly with other eBPF components like XDP or cgroup hooks.
For instance, a complex multi-tenant environment might require distinct firewall policies per tenant that evolve as services change. By storing these policies in maps and using a NETFILTER eBPF program, the operator can update them at runtime, achieving a level of flexibility and programmability that static rules cannot offer. As the kernel continues to integrate eBPF more deeply into its subsystems, NETFILTER type programs are poised to become a powerful complement or even replacement for traditional firewall configurations.
We don’t need to explain the Attach Types because they are abstracted away when using libbpf. It automatically sets the proper attachment based on the program type and ELF section name.
Don’t worry if you don’t fully understand everything just yet or can’t see the big picture—by working through the examples in the next chapter, the concepts will become much clearer. We will explore practical examples of eBPF programs and their interaction with various kernel events, demonstrating how to apply the concepts we’ve covered and providing hands-on experience with attaching eBPF programs to real-world events.