eBPF Architecture
The eBPF architecture is both simple—through its rigid instruction set, maps, and helpers—and sophisticated—via the verifier, JIT, and integration points. At a high level, it is a pipeline taking user-space defined logic through a safety check and into the kernel’s execution environment. At a deep level, each component (verifier, maps, JIT) enforces strict rules that guarantee the kernel’s stability and performance. Through this layered design, eBPF achieves a rare combination: the ability to safely run custom code inside the kernel at near-native speeds while maintaining robust security and reliability guarantees.
Some of the following may not be clear to you yet, as each component will be explained in more detail in the following chapters.
A high-level view of the architecture:
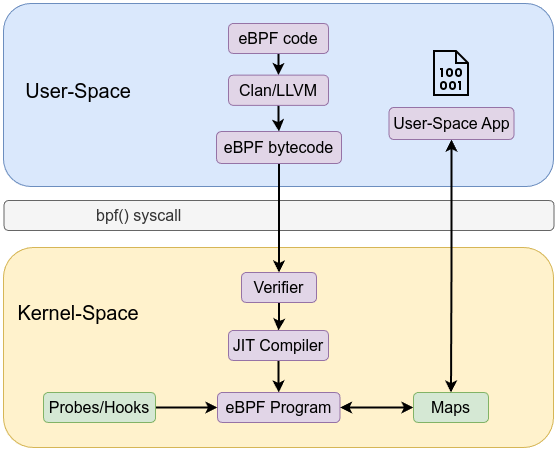
eBPF Loader and User-Space Tools
User space tooling compiles and loads these eBPF programs. For example, Clang/LLVM: Compiles C (or other) source code to eBPF bytecode using a special -target bpf flag. The workflow is similar to the following:
- Write program in C (or higher-level language).
- Compile to eBPF bytecode with clang.
- Use
bpf()system calls via libbpf or bpftool to load the bytecode into the kernel. - The verifier inspects it, and if safe, it is ready to run.
This pipeline ensures a controlled, step-by-step process from user space into the kernel.
Verification and Safety Constraints
Before an eBPF program runs, it must pass through a static verifier that analyzes every possible execution path. The verifier ensures:
- Memory Safety: No out-of-bounds accesses to the stack, no invalid pointer arithmetic, and no unsafe direct memory dereferences.
- Termination Guarantee: No infinite loops; all loops must have known upper bounds.
- Argument Checking: Arguments passed to helper functions must conform to expected types and constraints.
- Register State Tracking: The verifier tracks register states to ensure no use of uninitialized values and proper pointer usage rules.
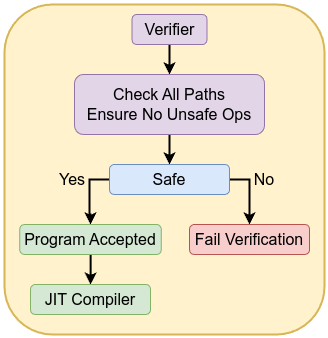
The verifier ensures that once a program is accepted, it cannot violate kernel integrity.
JIT Compilation and Performance
Once verified, eBPF bytecode can be interpreted by an in-kernel virtual machine, or just-in-time compiled into native machine instructions. The JIT compiler:
- Translates eBPF instructions to efficient CPU instructions.
- Eliminates interpretation overhead.
- Ensures near-native performance, which is vital for high-frequency events like networking.
This makes eBPF suitable for performance-critical tasks, such as packet processing at line rate with XDP (eXpress Data Path).
Context and Hook Points
eBPF programs are executed when certain kernel events occur. These events are known as hook points. Common hook points include:
- Tracepoints & Kprobes: Run when specific kernel functions or events occur.
- XDP Hooks: Triggered at the earliest point in network packet processing, allowing for ultra-fast packet filtering or modification.
- Socket and TC Hooks: Attach to sockets or traffic control ingress/egress points for per-packet decision making.
Each hook provides a context—a structured pointer to data relevant to that event (e.g., packet metadata, process info). The program reads fields from this context within verifier-approved bounds, making decisions based on current state.
Maps
Maps are the primary mechanism for storing and sharing state between eBPF programs and user space. They enable persistent data storage, counters, histograms, or lookup tables that eBPF code can use at runtime.
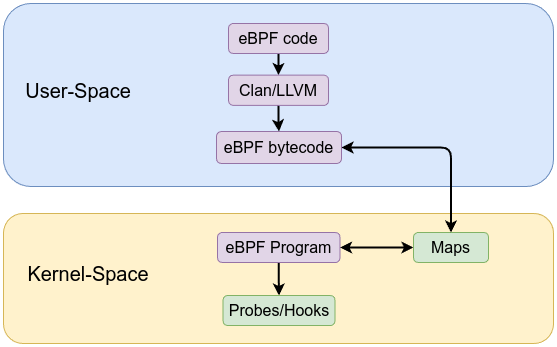
The verifier knows the properties of each map and ensures all access is safe (e.g., correct key size, no out-of-bounds reads). This static knowledge allows for safe data sharing between eBPF and user space.
Don’t worry if you don’t fully understand all the details yet—this is completely normal! As we go through applied examples, each step of the architecture will become much clearer, and you’ll be able to see how everything fits together in practice.